Release Notes
January 24, 2025
This release includes deprecated functionality and several fixed issues.
Deprecated Functionality
Several features which are not commonly used have been deprecated with this release and might be removed in a future release.
The following table lists the deprecated features, as well as suggested alternatives:
| Deprecated Feature | Suggested Alternatives |
|---|---|
| Time series analysis for jobs |
You can still view the total record count and throughput when monitoring a job or a topology that includes the job, but you cannot view the data over a period of time. For example, you can’t view the record count for the last five minutes or for the last hour. To create a historic view, call the Control Hub REST APIs to retrieve job metrics on a periodic basis and store the metrics in an external system. |
| Data delivery reports | Call the Control Hub Rest APIs to retrieve job metrics on a periodic basis, store the metrics in an external system, and then use the external system to generate reports on the data processing metrics. |
| Historical time series charts for engine performance information, including CPU load and memory usage |
You can still view the latest engine performance information, but you cannot view the data over a period of time. For example, you can’t view the engine performance for the last hour or for the last seven days. To create a historic view, call the Control Hub REST APIs to retrieve engine performance information on a periodic basis and store the information in an external system. |
| Historical charts for data SLAs for topologies | Data SLAs still trigger alerts when the specified threshold is reached, but you cannot view the historical chart of the throughput or error rate. |
Fixed Issues
- When a runtime parameter value contains a large number of characters, the pipeline properties panel shifts the value to the right such that you must scroll to display the value.
- When you import a pipeline that uses a fragment that was renamed in a later version, the fragment incorrectly uses the original name from version 1 of the fragment.
October 4, 2024
This release includes an enhancement and several fixed issues.
Enhancement
- Connection upgrades
- When you edit a connection and choose an authoring Data Collector of a later version that includes changes to the connection properties, you can now choose to upgrade the connection to use the changed properties. Alternatively, you can choose to create a copy of the connection and then upgrade the copy to use the changed properties.
Fixed Issues
- When viewing a read-only pipeline in the pipeline canvas, parameters with long values display to the far right of the properties panel such that you must scroll to view the values.
- A subscription triggered by a job status change event that does not use the JOB_OWNER parameter in the email action or event condition fails to send an email when the job owner no longer exists.
- When you choose to view engine metrics from seven or more days ago, Control Hub displays metrics from the last two days only.
- The Execute > Deployments view fails to load for users that are assigned the Provisioning Operator role.
July 26, 2024
- Users with the Job Operator and Pipeline User roles receive an HTTP 403 forbidden error when accessing the Job Instances and Job Templates views.
- Pipelines edited with an upgraded Data Collector incorrectly display the Data Collector version.
May 24, 2024
- You cannot sort by the Cron Expression or Time Zone column in the Scheduled Tasks view.
April 5, 2024
- Scheduled tasks periodically fail to start, sometimes displaying a
Connection is closederror in the run history. - The Update Stage Libraries dialog box does not save updates.
February 9, 2024
- You cannot export a draft pipeline or fragment using the Export option that removes plain text credentials.
- You cannot import a draft pipeline that includes a fragment.
- When using the Stream Selector processor, connecting the last stream when there were more than 4 streams required clicking on the edge of the icon.
December 8, 2023
- When you select jobs on the Jobs view and then click Create New Topology, the Topologies view displays rather than the Create New Topology window.
- Control Hub incorrectly retrieves the latest offset for a single instance job, causing an outdated or incorrect offset to display.
October 6, 2023
This release fixes the following issue:
- Jobs can become slow to start and stop.
September 8, 2023
This release includes several enhancements and fixed issues.
Enhancements
This release includes the following enhancements:
- Authoring engine timeout
- By default, Control Hub waits five seconds for a response from an authoring engine before considering the engine as inaccessible. An organization administrator can modify the default value in the organization properties.
- Alerts
- When the alert text defined for a data SLA or
pipeline alert exceeds 255 characters, Control Hub truncates the text
to 244 characters and adds a
[TRUNCATED]suffix to the text so that the triggered alert is visible when you click the Alerts icon in the top toolbar.
Fixed Issues
- If you change the values of existing pipeline fragment parameters, publish a new version of the fragment, and then update a pipeline using that fragment to use the latest version, the update incorrectly changes the default values for any existing runtime parameters in the pipeline.
- When you configure a scheduled task to use a time zone other than the default UTC, the task might not start at the correct time.
- Fragment export fails when a fragment contains multiple stages of the same type that use different library versions.
- On Windows 10, some file archive programs cannot extract an exported Control Hub ZIP file because of the colon (:) character in the JSON file names.
July 26, 2023
- When you export a draft pipeline or fragment, Control Hub does not remove plain text credentials configured directly in the pipeline or fragment.
- Export All Published Pipelines exports only some published pipelines.
May 19, 2023
This release includes an enhancement and several behavior changes and fixed issues.
Enhancement
This release includes the following enhancement:
- Pipeline and fragment export
Behavior Changes
This release includes the following behavior changes:
- StreamSets Data Collector Edge
-
StreamSets has paused all development on Data Collector Edge and is not supporting any active customer installations of Data Collector Edge. As a result, you can no longer download and register Data Collector Edge for use with Control Hub.
- Balancing and synchronizing jobs
- When you balance or synchronize a Data Collector job, Control Hub now temporarily stops the job to ensure that the last-saved offset from each pipeline instance is maintained. Control Hub then reassigns the pipeline instances to Data Collectors and restarts the job.
Fixed Issues
This release includes the following fixed issues:
- If you use Control Hub credentials to access an organization that uses SAML authentication and if
you change the password for those credentials, Control Hub might show the following security
warning:
The URL /?ss-repeated-redirect= is not registered as an engine that you have access to. Are you sure you want to send your login information to this URL?This warning is shown in error. You can ignore this message and log in to Control Hub with your updated credentials.
- When you modify or delete a parameter from a fragment being used in a pipeline, publish the fragment, and then update the pipeline to use the latest fragment version, the parameter changes are not reflected in the pipeline.
- When a pipeline fails over to another Data Collector, the input and output records that display in the job history do not include the records for the original Data Collector.
- When a pipeline fails over to another Data Collector, the input and output records that display in the Summary tab and in the run summary for a selected job run accessed from the History tab do not include the records for all Data Collectors.
- The Fields to Convert property in the Field Type Converter processor does not allow an expression that includes a comma.
April 7, 2023
This release includes a behavior change and a fixed issue.
Behavior Change
- Job instances with no job runs
- With this release, Control Hub automatically deletes inactive job instances older than 365 days that have never been run.
Fixed Issue
- Preview does not work when the Run Preview Through Stage property is set to a fragment.
January 30, 2023
- Data Collectors automatically provisioned using the Provisioning Agent are suddenly unregistered and deleted.
January 27, 2023
This release fixes the following issues:
- While monitoring a Transformer job, you cannot view and download the Spark driver log from the Control Hub UI.
- When you configure a pipeline to write aggregated statistics to Kafka using the SSL security protocol, the generated system pipeline incorrectly uses the plain text security protocol.
- If more than twenty authoring Data Collectors are available while creating a connection and you select an authoring Data Collector's radio button from the bottom of the list, the screen goes blank.
November 11, 2022
- The TRIGGERED_COUNT and TRIGGERED_ON subscription parameters do not contain the correct values.
- You can delete a job associated with a running scheduled task, resulting in a scheduled task that attempts to trigger actions on a job that doesn’t exist.
- Stages that were originally in a fragment could become uneditable.
- In rare cases, the configured time zone for a scheduled task is ignored, which causes the task to start and finish at undesired times.
- If you rename a job, scheduled tasks for that job do not update the job name.
August 19, 2022
- In rare cases, jobs can remain stuck in an active status even though the underlying pipeline never starts or can remain stuck in a deactivating status even though the underlying pipeline has been property stopped.
- When you click Reports > Report Definitions, the user interface does not load the report definitions and endlessly spins.
July 22, 2022
- In rare cases, Control Hub can send duplicate subscription notifications to the messaging queue.
June 24, 2022
- The topology canvas does not display the Edit icon or the topology version list.
June 10, 2022
This release includes several new features and fixed issues.
New Features
This release includes the following new features:
- Job status
- Jobs that have not run are listed with an Inactive status. Previously, jobs that had not run were listed without a status.
- Starting multiple scheduled jobs at the same time
- When you start multiple jobs at the exact same time using the scheduler, the
number of pipelines running on an engine can exceed the Max Running Pipeline
Count configured for the engine.
If exceeding the resource threshold is not acceptable, you can enable an organization property that synchronizes the start of multiple scheduled jobs. However, be aware that enabling the property can cause scheduled jobs to take longer to start.
- Control Hub logs
- Control Hub uses the Apache Log4j 2.17.2 library to write log data. In previous releases, Control Hub used the Apache Log4j 1.x library which is now end-of-life.
Fixed Issues
- Credential fields in a pipeline state notification webhook do not properly show the value of entered passwords when authentication is used.
- The pipeline canvas cannot handle more than 100 instances of the same stage.
- When a subscription fails to trigger because the event condition includes an invalid expression, the error message does not clearly indicate the cause.
- When you change the owner of a scheduled task, the previous owner is incorrectly listed as the user that executes the task.
- Some subscription edits are not persisted.
- Export All Published Pipelines exports only some published pipelines.
- The number of pipelines running on an engine can exceed the Max Running Pipeline Count configured for the engine when you start multiple jobs at the exact same time using the scheduler.
- A single faulty subscription prevents other suitable subscriptions from triggering.
- Pipeline names containing some special characters cause errors when running jobs.
- Exporting jobs can generate a corrupt ZIP file.
- The job History tab inconsistently displays Data Collector URLs.
March 18, 2022
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Scheduled tasks
- While creating a scheduled task, you can search for the job to schedule.
- SDC_ID subscription parameter displays as Engine ID in the user interface
- When you create a subscription and define a simple condition for an execution engine not responding event, the
SDC_IDparameter now displays asEngine IDin the UI, instead ofSDC_ID. TheEngine IDlabel indicates that the parameter can include the ID of any engine type.
Fixed Issues
This release fixes the following issues:
- Subscriptions do not trigger when permission enforcement is disabled for the organization.
- Exporting multiple pipelines can generate a corrupt ZIP file.
- When you select a later version of an authoring Data Collector while a pipeline is in read-only mode, stage libraries are not updated in the pipeline.
- The Global Failover Retries property does not display when creating or editing a Transformer job.
- Jobs enabled for failover take longer to complete than jobs that are not enabled for failover.
- Pipeline export fails when a pipeline contains multiple stages of the same type that use different library versions.
- A user with the License Administrator role cannot add or remove the Connection Editor or Connection User roles from users and groups.
February 18, 2022
- Job instances created from a job template do not inherit tags added to the template.
- The Global Failover Retries property is not maintained during the export and import of a job.
- A running job becomes corrupted if you import another version of the job that uses a newer pipeline version.
- A subscription for a job status change event with a JOB_OWNER condition set to a specific email address fails to trigger.
January 7, 2022
This release includes the following new feature:
- Control Hub REST API
-
When you use the Control Hub Job Runner REST API to return all jobs, you can now use additional parameters to search for jobs by name. You can search for jobs with names that equal the specified search text or search for jobs with names that start with the specified search text.
December 10, 2021
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Provisioned Data Collectors
- StreamSets has certified provisioning Data Collectors to AWS Fargate with Amazon Elastic Kubernetes Service (EKS). When using AWS Fargate with EKS, you must add additional attributes to the deployment YAML specification file.
- Jobs
- By default when a job encounters an inactive error status, users must acknowledge the error message before the job can be restarted.
- Pipeline preview
- By default, Control Hub does not save the preview record schema in the pipeline configuration. When you close and then reopen a pipeline, the Schema tab for each pipeline stage is empty. You must run preview again to update the input and output schema.
Fixed Issues
- Scheduled jobs do not start because they are stuck in a DEACTIVATING state.
- Jobs can transition to an INACTIVE_ERROR state with the following error
because multiple Job Runner applications attempt to process the same job:
JOBRUNNER_69 At least one of the execution engines <engine ID> didn’t respond to the stop command - Group permissions are not sufficient to trigger subscriptions.
- The pipeline canvas incorrectly allows adding a fragment to another fragment although nested fragments are not supported.
- After reloading a pipeline, parameters called from properties that display as checkboxes are not displayed.
- When a user has the Engine Creator and Engine Manager roles but no permission on an engine, the user can still directly connect to that engine.
- Job run history is not updated after accessing another job from the global search bar.
- Special characters in a pipeline name causes Control Hub to generate an incorrect Job URL.
- The Maximum Password Validity property for an organization does not change the password expiration time.
- Importing a pipeline with parameters and with fragments that use the same stage for different libraries can cause the import to fail with a duplicate key error.
- Scheduled jobs sometimes don’t run when the Missed Execution Handling is set to Ignore.
- If you configure the Global Failover Retries property for a job to 0, Control Hub incorrectly uses -1 for the property value and retries the failover indefinitely.
- Committing a pipeline causes a “Packet for query is too large” error.
September 22, 2021
- Jobs can remain in an ACTIVE state even if the pipeline run has finished.
- Jobs might incorrectly transition to an INACTIVE_ERROR state instead of an INACTIVE state.
- Jobs can remain in a DEACTIVATING state for several hours.
- Fixed with Transformer version 4.1.0 - When pipeline failover is enabled for a Control Hub job that runs a Transformer pipeline, the job can hang in a failover Transformer in a STARTING state when the Spark job completes before the failover Transformer fully takes over the Control Hub job.
August 27, 2021
- When a large number of jobs are started at the same time, the pipelines can remain in a starting state.
June 30, 2021
- Control Hub might display the following error when you attempt to acknowledge a
job with an inactive error
status:
org.apache.openjpa.persistence.ArgumentException: Cannot load object with id “<object_id>”. Instance "com.streamets.apps.jobrunner.backend.bean.JobStatusHistory@<id>” with the same id already exists in the L1 cache. This can occur when you assign an existing id to a new instance, and before flushing attempt to load the existing instance for that id.
June 25, 2021
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Jobs
-
When you enable a Data Collector or Transformer job for pipeline failover, you can configure the global number of pipeline failover retries to attempt across all available engines. When the limit is reached, Control Hub stops the job.
- Subscriptions
-
You can configure a subscription action for a maximum global failover retries exhausted event. For example, you might create a subscription that sends an alert to a Slack channel when a job has exceeded the maximum number of pipeline failover retries across all available engines.
Fixed Issues
- After you reset the origin for a job, the run history of the job incorrectly displays the input, output, and error record count.
- When an organization has more than 50 groups, you can only share objects with the first 50 groups listed in alphanumeric order.
- The pipeline canvas becomes unresponsive when you click the HTTP tab for the HTTP Client processor.
- The color of an Inactive job status can be incorrect due to race conditions. For
example, if a pipeline fails and the execution engine stops and deletes the
pipeline before the job transitions to a red Inactive status, then the job
status can display as gray or green Inactive instead of red Inactive.
May 14, 2021
- Datetime data does not display when you preview a pipeline.
April 16, 2021
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Pipeline Design
-
- Undo and Redo icons - The toolbar above the pipeline canvas includes an Undo icon to revert recent changes, and a Redo icon to restore changes that were reverted.
- Copy and paste multiple stages and fragments - You can
select multiple stages and fragments, copy them to the clipboard, and
then paste the stages and fragments into the same pipeline or into
another pipeline.
Previously, you could duplicate a single stage or fragment within the same pipeline only.
- Scheduled Tasks
- By default, Control Hub retains the details for scheduled task runs for 30 days or for a maximum of 100 runs, and then purges them. You can change these values by modifying the organization configuration properties. Previously, Control Hub retained the details for scheduled task runs indefinitely.
- Execution Engines
- When you monitor registered Data Collectors and Transformers
from the Execute view, you can access the following information for each
execution engine:
- Support bundle - Allows you to generate a support bundle, or archive file, with the information required to troubleshoot various issues with the engine.
- Logs - Displays the log data for the engine. You can download the log and modify the log level when needed.
- Directories - Lists the directories that the engine uses.
- Health Inspector - Displays information about the basic health of the Data Collector. Health Inspector provides a snapshot of how the Data Collector JVM, machine, and network are performing. Available for Data Collector engines only.
Fixed Issues
- A Transformer job should fail over only when the Transformer instance becomes unresponsive.
- When SAML authentication is enabled, resetting the password of a user
assigned the Organization Administrator role after the user was created
causes the following error:
Invalid/unsupported hash version 'UNKNOWN'
February 19, 2021
- Pipelines can incorrectly fail over to a different execution engine type.
- The Provisioning Agent fails to send status updates about deployed Data Collectors to Control Hub.
- Control Hub commits unused fragments when you import a pipeline.
February 12, 2021
- The Jobs view does not display the engine label and job tags filter for users not assigned the Organization Administrator role.
February 5, 2021
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Dashboards
- The Dashboards view includes the following dashboards:
- Alerts Dashboard - Provides a summary of triggered alerts, jobs with errors, offline execution engines, and unhealthy engines that have exceeded their resource thresholds. Use to monitor and troubleshoot jobs.
- Topologies Dashboard - Provides a summary of the number of pipelines, jobs, topologies, and execution engines that you have access to. The Topologies Dashboard was previously named the Default Dashboard.
- Alerts
- Control Hub retains acknowledged data SLA and pipeline alerts for 30 days, and then purges them. Previously, Control Hub retained acknowledged alerts indefinitely.
- Data Collector Pipelines
- When designing Data Collector pipelines using an authoring Data Collector version 3.18.x or later, pipelines and stages include advanced options with default values that should work in most cases. By default, new and upgraded pipelines hide the advanced options. Advanced options can include individual properties or complete tabs.
- Jobs
-
- Pipeline failover for Transformer jobs - You can enable a
Transformer job for pipeline failover for some cluster types when the
job runs on Transformer version 3.17.0 or later. Enable pipeline
failover to prevent Spark applications from failing due to an unexpected
Transformer shutdown. When enabled for failover, Control Hub can
reassign the job to an available backup Transformer.
At this time, you can enable failover for jobs that include pipelines configured to run on an Amazon EMR or Google Dataproc cluster. You cannot enable failover for other cluster types.
- View custom stage metrics for Data Collector jobs - When a Data Collector pipeline includes stages that provide custom metrics, you can view the custom metrics in the Realtime Summary tab as you monitor the job.
- Pipeline failover for Transformer jobs - You can enable a
Transformer job for pipeline failover for some cluster types when the
job runs on Transformer version 3.17.0 or later. Enable pipeline
failover to prevent Spark applications from failing due to an unexpected
Transformer shutdown. When enabled for failover, Control Hub can
reassign the job to an available backup Transformer.
- Reports
- The Reports view includes the following views:
- Reports - Provides a set of predefined reports that give an overall summary of the system. Use these predefined reports to monitor and troubleshoot jobs.
- Report Definitions - Allows you to define a custom data delivery report that provides data processing metrics for a given job or topology. The Report Definitions view was previously named the Reports view.
- Subscriptions
-
- Visible subscription parameters - When you define conditions
to filter events, subscription parameters are now visible in the UI. You
can select a parameter and define its value to create a simple
condition. You can also create advanced conditions using the StreamSets
expression language.
Previously, you had to view the documentation for the list of subscription parameters. In addition, you had to use the expression language to define all conditions, including simple conditions.
- Single event types - Subscriptions have been simplified so
that you can create a subscription for a single event type instead of
for multiple event types. Because you can only define a single action
for a subscription, it’s more practical to create a subscription for a
single event type. In most cases, you’ll want to define a unique action
for each event type.
If you previously created subscriptions for multiple event types, the upgrade process successfully upgrades the subscription and displays each event type. You can continue to use these subscriptions. However, you cannot create new subscriptions for multiple event types.
- Visible subscription parameters - When you define conditions
to filter events, subscription parameters are now visible in the UI. You
can select a parameter and define its value to create a simple
condition. You can also create advanced conditions using the StreamSets
expression language.
- Execution Engines
- When you monitor registered Data Collectors and Transformers
from the Execute view, you can view the following information for each execution
engine:
- Configuration - Lists configuration properties for the engine.
- Thread dump - Lists all active Java threads used by the engine.
- Metrics - Displays metric charts about the engine, such as the CPU usage, threads, and heap memory usage.
Fixed Issues
- The pipeline status displayed in the Jobs list sometimes does not match the pipeline status displayed in the job details.
- You cannot view a job when the associated system job has been deleted.
December 11, 2020
- Control Hub might fail to delete a user from an organization.
- When you balance a job, Control Hub unevenly redistributes the pipeline load across available Data Collectors.
November 13, 2020
- You cannot acknowledge an error for a deployment with an activating error status.
- Pipelines configured to write statistics to Amazon Kinesis Streams using an authoring Data Collector version 3.18.x or earlier fail when run on an execution Data Collector version 3.19.0.
- When permission enforcement is enabled, a pipeline cannot be run if another user has performed a test run of the draft pipeline.
November 6, 2020
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Connections
- You can create connections to define the information required to access data in external systems. You share the connections with data engineers, and they simply select the appropriate connection name when configuring pipelines and pipeline fragments in Control Hub Pipeline Designer.
- Jobs
- When monitoring a job run on Transformer version 3.16.0 or later, you can view
the contents of the Spark
driver log from the Control Hub UI for the
following types of pipelines:
- Local pipelines
- Cluster pipelines run in Spark standalone mode
- Cluster pipelines run on Kubernetes
- Cluster pipelines run on Hadoop YARN in client deployment mode
- Organization Configuration
-
An organization administrator can configure the execution engine heartbeat interval property. The interval determines the maximum number of seconds since the last reported execution engine heartbeat before Control Hub considers the engine as unresponsive. In most cases, the default value of five minutes is sufficient.
Fixed Issues
- You cannot stop a job when the system job has been deleted.
- When you use a registered Data Collector to download a published pipeline from Control Hub, the latest draft pipeline is downloaded instead of the published pipeline.
- Job tags are not copied from a job template to job instances created from that template.
- Pipeline Designer incorrectly displays the Copy icon when you select multiple stages in the canvas.
- The Jobs view inaccurately displays an asterisk (*) for the pipeline status when the pipeline fails over to another Data Collector.
- When an HTTP Client processor uses the Control Hub API to delete a job, the processor returns an HTTP 200 status with an empty response instead of including the deleted job in the response.
- Stopped deployments might remain in a deactivating state even after the
Provisioning Agent successfully stops the existing Data Collector containers in Kubernetes.
- Pipeline Designer displays only 50 fragments in the stage library and allows you to search for those 50 fragments instead of all fragments.
- After updating the stage definitions in a pipeline, Pipeline Designer incorrectly displays an error that the stage definition cannot be found until you refresh the page.
September 25, 2020
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Update Jobs when Publishing a Pipeline
-
When publishing a pipeline, you can update jobs that include the pipeline to use the latest pipeline version. You can also easily create a new job using the latest pipeline version.
- Sample Pipelines
-
"Pipeline templates" are now known as "sample pipelines".
The pipeline repository provides a new Sample Pipelines view that makes it easier to view a sample pipeline to explore how the pipeline and stages are configured. You can duplicate a sample pipeline to use it as the basis for building your own pipeline.
- Pipelines and Pipeline Fragments Views
-
- Filter pipelines and fragments by status - In the Pipelines and Pipeline Fragments views, you can filter the list of pipelines or fragments by status. For example, you can filter the list to display only published pipelines or to display only draft pipelines.
- User who last modified a pipeline or fragment - The Pipelines and Pipeline Fragments views include a column that lists the user who last modified each pipeline or fragment.
- Pipeline Design
-
- Stage library panel display and stage installation for Data Collector
pipelines - The stage library panel in the pipeline canvas
displays all Data Collector stages, instead of only the stages installed on the selected
authoring Data Collector.
Stages that are not installed appear disabled, or greyed out.
When the selected authoring Data Collector is a tarball installation, you can click on a disabled stage to install the stage library that includes the stage on the authoring Data Collector. Previously, you had to log into Data Collector to install additional stage libraries.
- Install external libraries from the properties panel - You can select a stage in the pipeline canvas and then install external libraries for that stage from the properties panel. Previously, you had to log into Data Collector or Transformer to install external libraries.
- View all jobs that include a pipeline version - When viewing a pipeline in Pipeline Designer, you can view the complete list of jobs that include that pipeline version.
- Optional parameter name prefix for fragments - When adding a fragment to a pipeline, you can remove the parameter name prefix. You might remove the prefix when reusing a fragment in a pipeline and you want to use the same values for the runtime parameters in those fragment instances.
- Stage library panel display and stage installation for Data Collector
pipelines - The stage library panel in the pipeline canvas
displays all Data Collector stages, instead of only the stages installed on the selected
authoring Data Collector.
Stages that are not installed appear disabled, or greyed out.
- Jobs
-
When monitoring an active Data Collector or Transformer job, you can view the log for the execution engine running the remote pipeline instance. You can filter the messages by log level or open the log in the execution engine UI.
Fixed Issues
- The Realtime Summary tab in the monitoring panel does not work for Data Collector Edge jobs.
- When you restart a deployment, a job with a pipeline that calls credential
functions fails to restart on a newly provisioned Data Collector due to the
following
error:
CREDENTIAL_STORE_001 - Store ID '<store-ID>', user does not belong to group 'all@<org-name>', cannot access credential '<credential-name>&<secret-name>' - After stopping a job that has the number of pipeline instances set to -1, the job may remain in a Deactivating state.
- Subscriptions fail when the subscription owner is deleted.
July 22, 2020
- A Provisioning Agent fails to deploy Data Collector containers when the deployment YAML specification file associates a Kubernetes Horizontal Pod Autoscaler, service, or Ingress with the deployment.
July 17, 2020
This release includes new features and fixed issues.
New Features
This release includes the following new features:
- Pipeline Design
-
- Pipeline test run history - The test run history for a draft pipeline displays the input, output, and error record count for each test run.
- Transformer pipeline validation - You can use Pipeline Designer to validate a Transformer pipeline against the cluster configured to run the pipeline.
- Jobs
-
- Tags - You can assign tags to jobs to identify similar jobs and job templates. Use job tags to easily search and filter jobs and job templates in the Jobs view.
- Pipeline status - The status of remote pipeline instances run from a job is more visible in the Jobs view.
- Job run history - The run history for a job displays the input, output, and error record count for each job run.
- Snapshots
-
- Preview source - You can use snapshot data as the source data when previewing Data Collector pipelines.
- Rename snapshots - You can rename captured snapshots.
- View snapshots after pipeline test run stops - You can view snapshots captured for a pipeline test run after the test run stops.
- Failure snapshots for pipeline test runs - When a pipeline test run fails, Control Hub automatically captures a failure snapshot which you can view to troubleshoot the problem.
- Scheduler
-
- Scheduled task details - The details of a scheduled task include the name and link to the report or job that has been scheduled.
- View audit - When you view the audit of all changes made to a scheduled task, the audit lists the most recent change first.
- Subscriptions
-
You can use the PIPELINE_COMMIT_ID parameter for a subscription trigged by a pipeline committed event.
- Export
-
You can export all pipelines, pipeline fragments, jobs, or topologies by selecting the More > Export All option from the appropriate view.
- UI Improvements
-
- Global search - You can globally search for pipelines, pipeline
fragments, jobs, and topologies by name using the following search field
in the top toolbar:

- Pagination - All views except for the Scheduler view display long lists over multiple pages.
- Global search - You can globally search for pipelines, pipeline
fragments, jobs, and topologies by name using the following search field
in the top toolbar:
- Control Hub Rest API
-
The Control Hub REST API includes the following enhancements:
- New PipelineStore Metrics API - Retrieves all pipelines created by users in a group within a specified time period.
- Security Metrics APIs - Additional Security Metrics APIs that
retrieve the following information:
- Retrieve all users that have logged in within a specified time period.
- Retrieve all users that have not logged in within a specified time period.
- Retrieve all users created within a specified time period.
- Retrieve all users that don’t belong to a specified group.
Fixed Issues
- When creating a report, the list of jobs and topologies does not display correctly.
- When designing a Transformer pipeline, you cannot connect an origin to a pipeline fragment that includes at least one origin and a processor with an open input stream.
- Previewing a pipeline in Pipeline Designer fails even though previewing the same pipeline using Data Collector or Transformer succeeds.
- Preview does not clearly display errors for stages that are included in a pipeline fragment.
- Control Hub incorrectly considers registered Data Collectors to be unresponsive.
- Cannot duplicate a job that has been upgraded to the latest published pipeline version.
- Scheduled tasks intermittently do not trigger at the scheduled time.
- An imported pipeline does not retain the pipeline name provided during the import process.
- Control Hub generates an invalid JSON payload for a webhook action for a subscription when the payload includes special characters.
- When a JDBC Multitable Consumer origin reads from more than 55 tables, Pipeline Designer cannot display the list of tables.
- Starting a job for a pipeline that includes a SQL Server Change Tracking Client origin fails with a null pointer exception.
- Job details do not display correctly when the job has not been run.
May 29, 2020
- After editing the grok pattern for a Log Parser processor and then publishing the pipeline, Control Hub incorrectly displays a warning that the pipeline has not changed but then saves the newer version with the change.
- When version 1 of a pipeline is deleted, you cannot edit any other versions of the pipeline.
- When the owner of a scheduled task is deleted, the scheduled task cannot start a job.
May 11, 2020
- The StreamSets Control Agent uses a key length of less than the recommended 2048
bits for the RSA encryption algorithm.
This fix is included in the Control Agent Docker image version 3.17.0. StreamSets recommends that you update all existing Provisioning Agents to use this latest version.
If an existing Provisioning Agent uses
latestas the Control Agent Docker image version and theimagePullPolicyattribute in the Provisioning Agent YAML specification is set toAlways, redeploy the Provisioning Agent so that it is automatically updated to use version 3.17.0. If an existing Provisioning Agent uses a specific Control Agent Docker image version, update the Provisioning Agent YAML specification file to use the Control Agent Docker image version3.17.0or to uselatest. For more information, see Applying Changes to Provisioning Agents.
May 8, 2020
This release includes new features and fixed issues.
New Features
- Pipelines and Pipeline Fragments
-
- A microservice sample pipeline is now available when creating a Data Collector pipeline from a sample pipeline.
- Pipeline Designer can
now use field information from data preview in the following ways:
- Some field properties have a Select Fields Using Preview Data icon that you can use to select fields from the last data preview.
- As you type a configuration, the list of valid values includes fields from the input and output schema extracted from the preview.
- Fields in the Schema tab and in the data preview have a Copy Field Path to Clipboard icon that you can use to copy a field path, which you can then paste where needed.
- The Pipelines view and the Pipeline Fragments view now display long lists over multiple pages.
- The Pipelines view and the Pipeline Fragments view now offer additional
support for filters:
- Click the Keep Filter Persistent checkbox to retain the last applied filter when you return to the view.
- Save or share the URL to reopen the view with the applied filter later or on a different browser.
- Snapshots
- You can now capture snapshots during pipeline test runs or job runs for Data Collector. You can view a
snapshot to see the pipeline records at a point in time and you can download the
snapshot file. The Data Collector
instance used for the snapshot depends on where you take the snapshot:
- Snapshots taken from a pipeline test run use the selected authoring Data Collector.
- Snapshots taken while monitoring a job use the execution Data Collector for the job run. When there is more than one execution Data Collector, the snapshot uses the Data Collector selected in the monitoring detailed view.
- Jobs
-
- From the Jobs view, you can now duplicate a job or job template to create one or more exact copies of an existing job or job template. You can then change the configuration and runtime parameters of the copies.
- The color of the job status in the Jobs view during deactivation depends on
how the job was deactivated:
- Jobs stopped automatically due to an error have a red deactivating status.
- Jobs stopped as requested or as expected have a green deactivating status.
- The Jobs view now offers additional support for filters:
- Click the Keep Filter Persistent checkbox to retain the last applied filter when you return to the view.
- Save or share the URL to reopen the view with the applied filter later or on a different browser.
- The monitoring panel now shows additional information about job runs:
- The Summary tab shows additional metrics, such as record throughput.
- The History tab has a View Summary link that opens a Job Metrics Summary page for previous job runs.
- System Data Collector
- Administrators can now enable or disable the system Data Collector for use as the default authoring Data Collector in Pipeline Designer. By default, the system Data Collector is enabled for existing organizations, but disabled for new organizations.
- Control Hub REST API
- The Control Hub REST API
includes a new Control Hub
Metrics category that contains several RESTful APIs:
- Job Runner Metrics APIs retrieve metrics on job runs and executor uptime, CPU, and memory usage.
- Time Series APIs retrieve metrics on job runs and executor CPU and memory usage over time.
- Security Metrics APIs retrieve login and action audit reports.
Fixed Issues
- The scheduler is unable to start a job due to a concurrent update.
- Pipeline preview fails with errors.
- In the MemSQL Fast Loader destination, the JDBC tab becomes unresponsive when loading a large amount of JDBC content.
- When using a provisioned Data Collector, late-arriving events cause an authentication issue.
- Control Hub inserts spaces in Data Collector labels when saving edits from the Deployments view.
- Adding or updating a filter condition longer than 255 characters in a subscription generates an error message.
- The StreamSets Control Agent Docker image uses Alpine Linux 3.9 rather than Alpine Linux 3.11.
- For pipelines configured to not discard the start event, Pipeline Designer shows unused properties on the Start Event tab.
- The % CPU Usage label is misleading.
- Job Runner RESTful APIs do not consider some parameters.
April 8, 2020
- Cannot compare different versions of pipelines.
- Cannot switch between different versions of pipelines.
- Some labels do not display correctly.
March 21, 2020
This release includes new features and fixed issues.
New Features
- Pipeline Fragments
- When you reuse pipeline fragments in the same pipeline, you can now specify different values for the runtime parameters in each instance of the fragment. When adding a pipeline fragment to a pipeline, you specify a prefix for parameter names, and Pipeline Designer automatically adds that prefix to each runtime parameter in the pipeline fragment.
- Jobs
- To improve performance and scalability, this release introduces a process to
manage job history. Now, Control Hub automatically
deletes the history and metrics associated with a job on a predetermined basis.
By default, Control Hub:
- Retains the job history for the last 10 job runs. Administrators can increase the retention to at most 100 job runs.
- Retains the job history for 15 days from each retained job run. The history for each job run can contain at most 1,000 entries. Administrators can increase the retention to at most 60 days of job history.
- Retains job metrics only for jobs that have been active within the past 6 months.
Also, deleting a job now removes the job from the database.
- Integration of Cloud-Native Transformer Application
- You can use Helm charts to run Transformer as a cloud-native application in a
Kubernetes cluster. Control Hub can now generate a Helm script that inserts the Transformer authentication
token and Control Hub URL into
a Helm chart.
You can use Transformer running inside a Kubernetes cluster to launch Transformer pipeline jobs outside the Kubernetes cluster, such as those in a Databricks cluster, EMR cluster, or Azure HDInsight cluster. However, you can run a Transformer pipeline from the Kubernetes cluster without any additional Spark installation support from other vendors.
Fixed Issues
- Viewing a topology throws a null-pointer exception when the job associated with the topology has been deleted.
- Subscriptions incorrectly filter 201 responses as error messages.
- Duplicate entries for an organization user prevent reuse of a user ID.
- Importing an existing job causes an error when the imported job
does not contain the
executorTypefield. - Subscriptions created to trigger a report event generate a null-pointer exception.
- Stopping a job with the scheduler stops the job but results in an HTTP 404 error.
- Unable to scroll through the navigation list in the Firefox browser.
-
The schedule option is enable for job templates.
January 10, 2020
This release includes new features, deprecated features, and fixed issues.
New Features
- Data Protector
-
- Import and export policies - You can now import and export policies and
their associated procedures. This enables you to share policies with
different organizations, as from a development to a production
organization.
Import or export policies from the Protection Policies view.
- Category name assist in procedures - When you configure a procedure based on a category pattern, a list of matching category names displays when you begin typing the name. You can select the category name to use from the list of potential matches.
- Policy enactment change - Policies are no longer restricted to being
used only upon read or only upon write. A policy can now be used in
either case. As a result, the following changes have occurred:
- When previewing data or configuring a job, you can now select any policy for the read and for the write.
- You can now select any policy as the default read or write policy for an organization. You can even use the same policy as the default read policy and the default write policy.
- Import and export policies - You can now import and export policies and
their associated procedures. This enables you to share policies with
different organizations, as from a development to a production
organization.
- UI Improvements
- To improve usability, the Pipelines, Pipeline Fragments, Reports, and Jobs views change the positions of some fields.
- Data Collectors and Data Collector Edge
- You can now configure resource thresholds for any registered Data Collector or Data Collector Edge. When starting, synchronizing, or balancing jobs, Control Hub ensures that a Data Collector or Data Collector Edge does not exceed its resource thresholds for CPU load, percent memory used, and number of pipelines running.
- Balancing Jobs
- From the Registered Data Collectors list, you can now balance jobs that are enabled for failover and running on selected Data Collectors to distribute pipeline load evenly. When balancing jobs, Control Hub redistributes jobs based on assigned labels, possibly distributing jobs to Data Collectors not selected.
- Organization Security
- When creating or editing a group, you can now click links to clear any assigned roles or select all available roles.
Deprecated Features
- Viewing deleted jobs
- The ability to view the details and last monitoring statistics for deleted jobs and templates will be removed from Control Hub in future releases. Beginning in February 2020, Control Hub will only show jobs deleted 30 or fewer days ago. With the first release after March 1, 2020 Control Hub will show no deleted jobs: Deleting a job will remove the job from the database.
Fixed Issues
- Failover does not succeed when running many jobs or when the underlying pipeline for a job does not exist.
- The job status list shows duplicate Data Collector IDs.
- Webhook actions do not set read timeout.
- The Create and Start Job Instances window freezes when launching jobs based on templates.
- Jobs created by users removed from an organization do not restart during failover.
- Control Hub uses a non-compliant Jetty version.
- The Execute view does not list created and deployed Provisioning Agents for users with correct roles.
December 16, 2019
- Failover is unsuccessful when running large numbers of jobs.
- Jobs created by users removed from an organization do not restart during failover.
November 23, 2019
- Slow queries cause high resource utilization.
November 8, 2019
- The browser autofill feature saves and reuses passwords.
- Previews of JSON data do not always display data properly.
- Filtering pipelines by label can cause the same pipeline to appear multiple times in the list of pipelines.
- Lists of users do not show all available users.
October 25, 2019
This release includes new features and fixed issues.
New Features
- Data Protector
-
- Classification preview - You can now preview how StreamSets and custom
classification rules classify data. You can use the default JSON test
data or supply your own test data for the preview.
This is a Technology Preview feature that is meant for development and testing only.
- Pipeline preview with policy selection - When you preview pipeline data,
you can now configure the read and write protection policies to use
during the preview.
This is a Technology Preview feature that is meant for development and testing only.
- Cluster mode support - Data Protector now supports protecting data in cluster mode pipelines.
- Encrypt Data protection method - You can now use the Encrypt Data protection method to encrypt sensitive data.
- UI enhancements:
- The “Classification Rules” view has been renamed “Custom Classifications.”
- The Custom Classifications view and Protection Policies view are now available under a new Data Protector link in the navigation panel.
- Protection policies now list procedures horizontally instead of vertically.
- Classification preview - You can now preview how StreamSets and custom
classification rules classify data. You can use the default JSON test
data or supply your own test data for the preview.
- Subscriptions
- When configuring an email action for a job status change event, you can now use a parameter to have an email sent to the owner of the job.
- Organization Security
- This release includes the following improvements for managing users:
- The Add User dialog box now has links to clear any assigned roles or select all available roles.
- After you create a user account or reset the password of a user account, Control Hub now sends an email with a link to set a new password.
- Accessing Metrics with the REST API
-
You can now use the Control Hub REST API to access the count of input records, output records, and error records, as well as the last reported metric time for a job run.
Fixed Issues
- Length of user name is not validated.
- Cannot delete a user and then recreate the same user.
- Incorrectly computed acknowledgement timeouts cause jobs to enter an inactive error state.
- When you share objects, the Sharing Settings window does not clearly differentiate between users and groups, does not let you select multiple users and groups at once, and displays unreadable text for long names.
October 11, 2019
This release fixes the following known issues:
- Pipelines with multiple event-creating destinations do not render the destinations correctly.
- Stopping and restarting jobs on the same instance of Data Collector causes incorrect counts of running pipelines.
- Data preview does not work for published pipelines.
- Data preview does not wrap long values.
- Changes to pipelines cannot be published.
September 27, 2019
This release fixes the following known issue:
- The statuses of Data Collector pipelines are not shown correctly.
September 20, 2019
This release includes the following new feature:
- Uploading Offsets with the REST API
- You can now upload a valid offset with the Control Hub REST API, which uploads the offset as JSON data.
- Data preview is broken for edge pipelines.
- The automatically generated YAML specification file for new deployments contains incorrect syntax.
-
Colons in job titles incorrectly result in a tooltip that says “unsafe.”
September 15, 2019
This release fixes the following known issues:
- Uploading an initial offset file fails when an offset is already set for the job.
- When you define a second table configuration for the JDBC Multitable Consumer origin, properties in the first table configuration are overridden.
- When you start a job that contains a Transformer pipeline and the pipeline encounters a START_ERROR state, the job remains in an active state.
September 4, 2019
This release fixes the following known issue:
- Cannot preview or perform a test run of a draft pipeline when using an authoring Data Collector version earlier than 3.10.0.
August 30, 2019
This release includes the following new features and enhancements:
- Transformer Integration
- This release integrates StreamSets Transformer in Control Hub.
- Pipeline Design
- Pipeline Designer includes the following enhancements:
- Delete a draft pipeline or fragment in Pipeline Designer - While editing a draft version of a pipeline or fragment, you can now delete that draft version to revert to the previous published version of the pipeline or fragment. Previously, you could not delete a draft pipeline or fragment that was open in Pipeline Designer. You had to view the pipeline history, and then select the draft version to delete.
- View the input and output schema for each stage - After running preview
for a pipeline, you can now view the input and output schema for each
stage on the Schema tab in the pipeline properties panel. The schema
includes each field name and data type.
Use the Schema tab when you configure pipeline stages that require field names. For example, let’s say you are configuring a Field Type Converter processor to convert the data type of a field by name. You can run preview, copy the field name from the Schema tab, and then paste the field name into the processor configuration.
- Bulk update pipelines to use a different fragment version - When viewing a published pipeline fragment in Pipeline Designer, you can now update multiple pipelines at once to use a different version of that fragment. For example, if you edit a fragment and then publish a new version of the fragment, you can easily update all pipelines using that fragment to use the latest version.
- Import a new version of a published pipeline in Pipeline Designer - While viewing a published pipeline in Pipeline Designer, you can import a new version of the pipeline. You can import any pipeline exported from Data Collector for use in Control Hub or any pipeline exported from Control Hub as a new version of the current pipeline.
- User-defined sample pipelines - You can now create a
user-defined sample pipeline by assigning the
templatespipeline label to a published pipeline. Users with read permission on the published pipeline can select the pipeline as a user-defined sample when developing a new pipeline. - Test run of a draft pipeline - You can now perform a test run of a draft pipeline in Pipeline Designer. Perform a test run of a draft pipeline to quickly test the pipeline logic. You cannot perform a test run of a published pipeline. To run a published pipeline, you must first add the pipeline to a job and then start the job.
- Shortcut keys to undo and redo actions - You can now use the
following shortcut keys to easily undo and redo actions in Pipeline
Designer:
- Press Command+Z to undo an action.
- Press Command+Shift+Z to redo an action.
- Jobs
- Jobs include the following enhancements:
- Monitoring errors - When you monitor an active Data Collector job with a pipeline stage that encounters errors, you can now view details about each error record on the Errors tab in the Monitor panel.
- Export and import job templates - When you export and import a job template, the template is now imported as a job template. You can then create job instances from that template in the new organization. You cannot export and import a job instance. Previously, when you exported and imported a job template or a job instance, the imported job template or instance functioned as a regular job in the new organization.
- Subscriptions
- You can now configure a subscription action for a changed job status color. For example, you might create a subscription that sends an email when a job status changes from active green to active red.
- Roles
- All Data Collector roles have been renamed to Engine roles and now enable performing tasks in registered Data
Collectors and registered Transformers.
For example, the Data Collector Administrator role has been renamed to the Engine Administrator role. The Engine Administrator role now allows users to perform all tasks in registered Data Collectors and registered Transformers.
- Provisioned Data Collectors
- Provisioned Data Collectors include the following enhancements:
- Upload the deployment YAML specification file - When you create a deployment, you can now upload the deployment YAML specification file instead of copying the contents of the file in the YAML Specification property.
- View YAML specification file for active deployments - You can now view the contents of the YAML specification file when you view the details of an active deployment.
- Configurable Kerberos principal user name - When you define a deployment YAML specification file to provision
Data Collector containers enabled for Kerberos authentication, you can
now optionally define the Kerberos principal user name to use for the
deployment. If you do not define a Kerberos user name, the Provisioning
Agent uses
sdcas the user name.
- Registered Data Collectors intermittently become unavailable due to read timeouts.
- Permissions on provisioned Data Collectors might be removed when the Data Collectors are restarted.
- When LDAP or SAML authentication is enabled, Control Hub user names are not case sensitive during login, but are case sensitive for permissions.
- Control Hub allows HTML tags in user names, which can allow phishing emails to be sent from the application.
- The Control Hub API allows users to access the sign-up functionality.
June 14, 2019
This release includes the following new features and enhancements:
- Pipeline Design
-
Pipeline Designer includes the following enhancements:
- Preview time zone - You can now select the time zone to use for the preview of date, datetime, and time data. Previously, preview always displayed data using the browser time zone.
- Compare pipeline versions - When you compare pipeline
versions, you can now click the name of either pipeline version to
open that version in the pipeline canvas.
Previously, you had to return to the Navigation panel and then select the pipeline version from the Pipeline Repository to open one of the versions in the pipeline canvas.
- Jobs
- You can now upload an initial offset file for a job. Upload an initial offset file when you first run a pipeline in Data Collector, publish the pipeline to Control Hub, and then want to continue running the pipeline from the Control Hub job using the last-saved offset maintained by Data Collector.
- SAML Authentication
-
When SAML authentication is enabled, users with the new Control Hub Authentication role can complete the following tasks that require users to be authenticated by Control Hub:
- Use the Data Collector command line interface.
- Log into a Data Collector running in disconnected mode.
- Use the Control Hub REST API.
Previously, only users with the Organization Administrator role could complete these tasks when SAML authentication was enabled.
- Provisioned Data Collectors
- The Control Agent Docker image version 3.10.0 now
requires that each YAML specification file that defines a deployment use the
Kubernetes API version
apps/v1. Previously, the Control Agent Docker image required that each YAML specification file use the API versionextensions/v1beta1for a deployment. Kubernetes has deprecated theextensions/v1beta1version for deployments.
This release also fixes the following known issues:
- Jobs might incorrectly display metrics when you create a job for a pipeline that was downloaded from Control Hub into a registered Data Collector, and then exported from Data Collector to Control Hub.
- Job history does not track the inactive status.
- Duplicating a pipeline that contains two or more pipeline fragments displays a validation error about unconnected stages.
- An email subscription for a Pipeline Committed event does not display the pipeline commit message when the pipeline is published from Pipeline Designer.
- Importing jobs does not work reliably because Control Hub displays the rules associated with the job instead of with the pipeline.
- Cannot view logs when monitoring an active job.
- When you create a pipeline with the SFTP/FTP Client origin, the Pipeline Designer displays a validation error.
- Upgrading a job to the latest pipeline version does not upgrade the pipeline rules.
- Creating a new user requires that you directly assign the Organization Administrator or Organization User role to the user even if that user inherits those roles from an assigned group.
- Pipeline is duplicated in the Pipelines view when the pipeline is shared with a user and with a group that the user belongs to.
- Control Hub encounters a data truncation error when saving Data Collector metrics.
- During the maintenance window for a Control Hub Cloud release, all traffic is redirected to https://trust.streamsets.com, which causes Data Collectors to be inaccessible.
- When SAML authentication is enabled for an organization, all new users are required to update their password.
- Control Hub incorrectly checks for password expiration when SAML authentication is enabled.
Update Deployments for Provisioned Data Collectors
Starting with the StreamSets Control Agent
Docker image version 3.10.0, the Control Agent requires that each YAML specification
file that defines a deployment use the Kubernetes API version
apps/v1. Previously, the Control Agent Docker image required
that each YAML specification file use the API version
extensions/v1beta1. Kubernetes has deprecated the
extensions/v1beta1 version.
If you upgrade a Provisioning Agent that uses a
Control Agent Docker image version earlier than 3.10.0, you must update all
deployment YAML specification files to use apps/v1 before you
redeploy the Provisioning Agent.
To upgrade a Provisioning Agent and then update deployments, complete the following steps:
-
Stop all deployments.
- In the Navigation panel, select .
- Select each deployment, and then click the Stop icon.
-
Upgrade the Provisioning Agent to use the Control Agent Docker image version
3.17.0 or later. If using
latestas the Control Agent Docker image version, you can skip this step. -
Update all deployments.
February 27, 2019
- When a pipeline fragment includes a Stream Selector processor, the job fails with a SELECTOR_02 error.
- When using a browser on a Windows machine, the scrollbar in Pipeline Designer does not render correctly.
- Error counts displayed for stages are cleared only when you refresh the page.
- When editing a pipeline, you cannot close the validation error message because it is hidden by the Stage Library icon.
- The Job Status tab displays incorrect links to the Data Collectors running remote pipeline instances for the job.
- A report generated for a job displays a double count of processed records.
- Creating and starting a job template should not require the Organization Administrator role.
- After SAML authentication is enabled for an organization, Control Hub should not require new users to change their password.
- When permission enforcement is enabled and more than 50 objects of a single object type exist, users might not be able to see any objects that they have access to.
December 21, 2018
This release includes the following new features and enhancements:
- Provisioned Data Collectors
- You can now create a Provisioning Agent that provisions Data Collector containers enabled for Kerberos authentication.
- Jobs
- You can now upgrade active jobs to use the latest pipeline version. When you upgrade an active job, Control Hub stops the job, updates the job to use the latest pipeline version, and then restarts the job.
- Pipeline Design
- When you use the Control Hub Pipeline Designer to design pipelines, you can now call pipeline parameters for properties that display as checkboxes and drop-down menus. The parameters must evaluate to a valid option for the property.
- Permissions
- You can now share and grant permissions on multiple objects at the same time.
- Subscriptions
- When you create a subscription, you now configure the subscription in a single dialog box instead of clicking through multiple pages.
- The email sent for a pipeline metric or data alert contains an incorrect URL to the alert.
- Clarify that failover retries on a job is per Data Collector.
- Pipeline Designer displays credential values in stage properties when the pipeline is viewed in read only mode.
- Pipeline Designer does not detect changes to the pipeline when you change a metric, data, or data drift rule.
- When you stop and restart a job, Control Hub pins each pipeline instance to the same Data Collector.
- A job owner can stop the job when it is running on a Data Collector that he doesn't have access to.
- When jobs are manually started or scheduled to start, Control Hub should not attempt to start the jobs on Data Collectors that are not active.
- The Scheduler view can display only 50 scheduled jobs or reports.
- The Execute > Data Collectors view displays an incorrect number of running pipelines for registered Data Collectors.
- When the browser uses a timezone other than UTC and you attempt to schedule a
job or report, Control Hub displays the following
error:
ERROR : BEAN_BACKEND_000 - create, validation failed - When permission enforcement is enabled, pagination logic on the Jobs view might prevent you from viewing and creating jobs.
- When Control Hub uses LDAP authentication, you cannot log into registered Data Collectors using the disconnected mode.
November 28, 2018
- When the scheduler starts a job that includes a pipeline with a Hadoop-related
stage configured to impersonate the Hadoop user as the currently logged in Data
Collector user, Control Hub incorrectly interprets the user who starts the
pipeline to be
scheduler000which causes the pipeline to fail.
November 19, 2018
This release includes the following new features and enhancements:
- Preview in Pipeline Designer
-
Pipeline Designer can now display preview data in table view.
- Subscriptions
-
Subscriptions include the following enhancements:
- Pipeline status change event - You can now configure a subscription action for a changed pipeline status. For example, you might create a subscription that sends an email when a pipeline status changes to RUN_ERROR.
- Expression completion to filter events - You can now use expression completion to determine the functions and parameters that you can use for each subscription filter.
- Scheduler
-
The Control Hub scheduler can now stop a job at a specified frequency. For example, you might want to run a streaming job every day of the week except for Sunday. You create one scheduled task that starts the job every Monday at 12:00 am. Then, you create another scheduled task that stops the same job every Sunday at 12:00 am.
- SAML Authentication
-
When you map a Control Hub user account to a SAML IdP user account, the SAML User Name property now defaults to the email address associated with the Control Hub user account. Previously, the default value was the user ID associated with the Control Hub user account.
- The Control Hub UI takes a long time to display users and groups.
October 27, 2018
This release includes the following new features and enhancements:
- Data Protector
-
This release supports the latest version of Data Protector, Data Protector 1.4.0.
- Preview in Pipeline Designer
- You can now preview multiple stages in Pipeline Designer. When you preview multiple stages, you select the first stage and the last stage in the group. The Preview panel then displays the output data of the first stage in the group and the input data of the last stage in the group.
- Job Templates
- When you create a job for a pipeline that uses runtime parameters, you can now enable the job to work as a job template. A job template lets you run multiple job instances with different runtime parameter values from a single job definition.
- Subscribe to Unresponsive Data Collector or Data Collector Edge Events
- You can now configure a subscription action for a Data Collector or Data Collector Edge not responding event. For example, you might create a subscription that sends an alert to a Slack channel when a registered Data Collector stops responding.
- The POST method for the
/pipelinestore/rest/v1/pipelines/exportPipelineCommitsREST API endpoint has the wrong content type response header. - When special characters such as colons (:) and square brackets ( [ ] ) are included in a pipeline name, the remotely running pipeline cannot communicate with Control Hub.
October 12, 2018
This release includes the following new features and enhancements:
- Failover Retries for Jobs
- When a job is enabled for failover, Control Hub by default retries the pipeline failover an infinite number of times. If you want the pipeline failover to stop after a given number of retries, you can now define the maximum number of retries to perform. Control Hub maintains the failover retry count for each available Data Collector.
- Starting Jobs with the REST API
- You can now define runtime parameter values for a job when you start the job using the Control Hub REST API.
October 4, 2018
- A job encounters system pipeline failures when the job includes a pipeline published from Data Collector 3.5.0 and configured to write aggregated statistics to a Kafka cluster.
September 28, 2018
This release includes the following new features and enhancements:
- Data Protector
- You can now use Data Protector to perform global in-stream discovery and protection of data in motion with Control Hub.
- Pipeline Designer
- Pipeline Designer includes the following enhancements:
- Expression completion - Pipeline Designer now completes expressions in stage and pipeline properties to provide a list of data types, runtime parameters, fields, and functions that you can use.
- Manage pipeline and fragment versions - When
configuring a pipeline or pipeline fragment in Pipeline Designer,
you can now view the following visualization of the pipeline or
fragment version history:
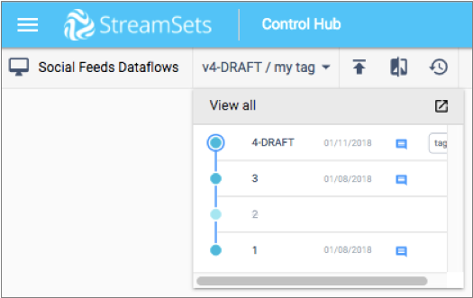
When you expand the version history, you can manage the pipeline or fragment versions including comparing versions, creating tags for versions, and deleting versions.
- Pipeline fragment expansion in pipelines - You can now expand and collapse
individual pipeline fragments when used in a pipeline. Previously,
expanding a fragment meant that all fragments in the pipeline were
expanded.
When a fragment is expanded, the pipeline enters read-only mode allowing no changes. Collapse all fragments to make changes to the pipeline.
- Preview and validate edge pipelines - You can now use Pipeline Designer to preview and validate edge pipelines.
- Shortcut menu for stages - When you select
a stage in the canvas, a shortcut menu now displays with a set of
options:
- For a pipeline fragment stage, you can copy, expand or delete the fragment.
- For all other stages, you can copy or delete the stage, or create a pipeline fragment using the selected stage or set of stages.
- Data Collectors
- You can now use an automation tool such as Ansible, Chef, or Puppet to automate
the registering and unregistering of Data Collectors using the following commands:
streamsets sch register streamsets sch unregister
- Scheduling a job in any time zone except UTC does not work as expected.
- Stopping a job that contains a pipeline with a Directory origin causes intermittent SPOOLDIR_35 errors to occur.
August 29, 2018
- Control Hub uses multiple versions of the jackson-databind JAR file.
August 4, 2018
This release includes the following new features and enhancements:
- Pipelines and Pipeline Fragments
-
- Data preview enhancements:
- Data preview support for pipeline fragments - You can now use data preview with pipeline fragments. When using Data Collector 3.4.0 for the authoring Data Collector, you can also use a test origin to provide data for the preview. This can be especially useful when the fragment does not contain an origin.
- Edit data and stage properties - You can now edit preview data and stage properties, then run the preview with your changes. You can also revert data changes and refresh the preview to view additional data.
- Select multiple stages - When you design pipelines and pipeline fragments, you can now select multiple stages in the canvas by selecting the Shift key and clicking each stage. You can then move or delete the selected stages.
- Export enhancement - When you export a single
pipeline or a single fragment, the pipeline or fragment is now saved
in a zip file of the same name, as follows:
<pipeline or fragment name>.zip. Exporting multiple pipelines or fragments still results in the following file name:<pipelines|fragments>.zip. - View where fragments are used - When you view the details of a fragment, Pipeline Designer now displays the list of pipelines that use the fragment.
- Data preview enhancements:
- Jobs
-
- Runtime parameters enhancements - When you edit a job, you can now use the Get Default Parameters option to retrieve all parameters and their default values as defined in the pipeline. You can also use simple edit mode, in addition to bulk edit mode, to define parameter values.
- Pipeline failover enhancement - When determining which available Data Collector restarts a failed pipeline, Control Hub now prioritizes Data Collectors that have not previously failed the pipeline.
- Data Collectors
-
- Monitor Data Collector performance - When you view registered Data Collectors version 3.4.0 from the Execute view, you can now monitor the CPU load and memory usage of each Data Collector.
- Edge Data Collectors (SDC Edge)
-
- Monitor SDC Edge performance - When you view registered Edge Data Collectors version 3.4.0 from the Execute view, you can now monitor the CPU load and memory usage of each SDC Edge.
- Data Delivery Reports
-
- Destination statistics - Data delivery reports for jobs and topologies now contain statistics for destinations.
- Documentation
-
- Documentation enhancement - The online help has a new look and feel. All of the previous documentation remains exactly where you expect it, but it is now easier to view and navigate on smaller devices like your tablet or mobile phone.
- Re-importing a deleted job does not update all relevant information.
- When load balancing jobs to other Data Collectors, offsets are not retained.
- Do not change a job status to Inactive until after the status of the system pipeline becomes Inactive.
- When you configure a pipeline in Pipeline Designer to use Write to Kafka for both the Error Records and Statistics tabs, changes you make to the Kafka settings on one tab are automatically copied to the other tab.
- When the same job is executed by different Data Collectors, a topology can display metrics from a previous run of the job.
- Data Collectors provisioned with a deployment might not inherit permissions assigned to the deployment.
May 25, 2018
This release fixes the following known issues:
- Viewing pipeline details from the Topology view causes an error to occur.
- Time series charts for jobs cannot be viewed from the Topology view even though time series analysis is enabled.
- When a Kubernetes pod is restarted, the Provisioning Agent fails to register the Data Collector containers with Control Hub.
May 11, 2018
This release includes the following new features and enhancements:
- Pipeline Fragments
- Control Hub now includes pipeline fragments. A pipeline fragment is a stage or set of connected stages that you can reuse in Data Collector or SDC Edge pipelines. Use pipeline fragments to easily add the same processing logic to multiple pipelines and to ensure that the logic is used as designed.
- Scheduler
-
Control Hub now includes a scheduler that manages long-running scheduled tasks. A scheduled task periodically triggers the execution of a job or a data delivery report at the specified frequency. For example, a scheduled task can start a job or generate a data delivery report on a weekly or monthly basis.
Before you can schedule jobs and data delivery reports, the Scheduler Operator role must be assigned to your user account.
- Data Delivery Reports
-
Control Hub now includes data delivery reports that show how much data was processed by a job or topology over a given period of time. You can create periodic reports with the scheduler, or create an on-demand report.
Before you can manage data delivery reports, the Reporting Operator role must be assigned to your user account.
- Jobs
-
- Edit a pipeline version directly from a job - When viewing the details of a job or monitoring a job, you can now edit the latest version of the pipeline directly from the job. Previously, you had to locate the pipeline in the Pipeline Repository view before you could edit the pipeline.
- Enable time series analysis - You can now enable time
series analysis for a job. When enabled, you can view
historical time series data when you monitor the job or a topology that
includes the job.
When time series analysis is disabled, you can still view the total record count and throughput for a job or topology, but you cannot view the data over a period of time. For example, you can’t view the record count for the last five minutes or for the last hour.
By default, all existing jobs have time series analysis enabled. All new jobs have time series analysis disabled. You might want to enable time series analysis for new jobs for debugging purposes or to analyze dataflow performance.
- Pipeline force stop timeout - In some situations when you stop a job, a remote pipeline instance can remain in a Stopping state for a long time. When you configure a job, you can now configure the number of milliseconds to wait before forcing remote pipeline instances to stop. The default time to force a pipeline to stop is 2 minutes.
- View logs- While monitoring an active job, the top toolbar now includes a View Logs icon that displays the logs for any remote pipeline instance run from the job.
- Subscriptions
-
- Email action - You can now create a subscription that listens for Control Hub events and then sends an email when those events occur. For example, you might send an email each time a job status changes.
- Pipeline committed event - You can configure an action for a pipeline committed event. For example, you might send a message when a pipeline is committed with the name of the user who committed it.
- Filter the events to subscribe to - You can now
use the StreamSets expression language to create an expression that
filters the events that you want to subscribe to. You can
include subscription parameters and StreamSets string functions in the
expression.For example, you might enter the following expression for a Job Status Change event so that the subscription is triggered only when the specified job ID encounters a status change:
${JOB_ID == '99efe399-7fb5-4383-9e27-e4c56b53db31:MyCompany'}If you do not filter the events, then the subscription is triggered each time an event occurs for all objects that you have at least read permission on.
- Permissions - When permission enforcement is enabled for your organization, you can now share and grant permissions on subscriptions.
- Provisioned Data Collectors
-
When you define a deployment YAML specification file for provisioned Data Collectors, you can now optionally associate a Kubernetes Horizontal Pod Autoscaler, service, or Ingress with the deployment.
Define a deployment and Horizontal Pod Autoscaler in the specification file for a deployment of one or more execution Data Collectors that must automatically scale during times of peak performance. The Kubernetes Horizontal Pod Autoscaler automatically scales the deployment based on CPU utilization.
Define a deployment and service in the specification file for a deployment of a single development Data Collector that must be exposed outside the cluster using a Kubernetes service. Optionally associate an Ingress with the service to provide load balancing, SSL termination, and virtual hosting to the service in the Kubernetes cluster.
- Importing a pipeline with a null label causes a null pointer exception.
March 30, 2018
This release includes the following new features and enhancements:
- Pipelines
-
Pipelines include the following enhancements:
- Duplicate pipelines - You can now select a pipeline in the Pipeline Repository view and then duplicate the pipeline. A duplicate is an exact copy of the original pipeline.
- Commit message when publishing pipelines - You can now enter commit messages when you publish pipelines from Pipeline Designer. Previously, you could only enter commit messages when you published pipelines from a registered Data Collector.
- Export and Import
-
You can now use Control Hub to export and import the following objects:
- Jobs and topologies - You can now export and
import jobs and topologies to migrate the objects from one
organization to another. You can export a single job or topology or
you can export a set of jobs and topologies.
When you export and import jobs and topologies, you also export and import dependent objects. For jobs, you also export and import the pipelines included in the jobs. For topologies, you also export and import the jobs and pipelines included in the topologies.
- Sets of pipelines - You can now select multiple pipelines in the Pipeline Repository view and export the pipelines as a set to a ZIP file. You can also now import pipelines from a ZIP file containing multiple pipeline files.
- Jobs and topologies - You can now export and
import jobs and topologies to migrate the objects from one
organization to another. You can export a single job or topology or
you can export a set of jobs and topologies.
- Alerts
-
The Notifications view has now been renamed the Alerts view.
- Subscriptions
-
You can now create a subscription that listens for Control Hub events and then completes an action when those events occur. For example, you might create a subscription that sends a message to a Slack channel each time a job status changes.
When you create a subscription, you select the Control Hub events to subscribe to - such as a changed job status or a triggered data SLA. You then configure the action to take when the events occur - such as using a webhook to send an HTTP request to an external system.Important: By default, an organization is not enabled to send events that trigger subscriptions. Before Control Hub can trigger subscriptions for your organization, your organization administrator must enable events for the organization. - Jobs
-
- Scale out active jobs - When the Number of
Instances property for a job is set to -1, Control Hub can now automatically scale out pipeline processing for the active
job.
When Number of Instances is set to any other value, you must synchronize the active job to start additional pipeline instances on newly available Data Collectors or Edge Data Collectors.
For example, if Number of Instances is set to -1 and three Data Collectors have all of the specified labels for the job, Control Hub runs three pipeline instances, one on each Data Collector. If you register another Data Collector with the same labels as the active job, Control Hub automatically starts a fourth pipeline instance on that newly available Data Collector.
Previously, you had to synchronize all active jobs - regardless of the Number of Instances value - to start additional pipeline instances on a newly registered Data Collector.
- View logs for an active job - When monitoring an active job, you can now view the logs for a remote pipeline instance from the Data Collectors tab.
- Scale out active jobs - When the Number of
Instances property for a job is set to -1, Control Hub can now automatically scale out pipeline processing for the active
job.
- Control Hub does not update the job status after automatically scaling out an active job.
- The topology auto fix method throws an error when an updated pipeline version includes changes made to an error handling stage.
- After deleting a registered Data Collector, the Data Collector heartbeats back into Control Hub, but without a Data Collector URL.
- Users and groups are not hard deleted.
March 6, 2018
- The Pipeline Designer preview mode does not correctly display no output.
- The Pipeline Designer deletes the incorrect row from a list of expressions.
- The browser crashes when a topology contains an infinite loop.
January 14, 2018
- Pipeline Designer does not yet include the ability to configure rules.
- You cannot acknowledge errors or force stop system jobs that run system pipelines.
- Runtime parameters are not propagated to the system pipeline - causing the system pipeline to fail.
December 15, 2017
This release includes the following new features and enhancements:
- Product Rename
-
With this release, we have created a new product called StreamSets Control HubTM that includes a number of new cloud-based dataflow design, deployment, and scale-up features. Since this release is now our core service for controlling dataflows, we have renamed the StreamSets cloud experience from "Dataflow Performance Manager (DPM)" to "StreamSets Control Hub”.
DPM now refers to the performance management functions that reside in the cloud such as live metrics and data SLAs. Customers who have purchased the StreamSets Enterprise Edition will gain access to all Control Hub functionality and continue to have access to all DPM functionality as before.
- Pipeline Designer
-
You can now create and design pipelines directly in the Control Hub Pipeline Designer after you select an authoring Data Collector for Pipeline Designer to use. You select one of the following types of Data Collectors to use as the authoring Data Collector:
- System Data Collector - Use to design pipelines only - cannot be used to preview or explicitly validate pipelines. The system Data Collector is provided with Control Hub for exploration and light development. Includes the latest version of all stage libraries available with the latest version of Data Collector.
- Registered Data Collector using the HTTPS protocol - Use to design, preview, and explicitly validate pipelines. Includes the stage libraries and custom stage libraries installed in the registered Data Collector.
When you create pipelines in Pipeline Designer, you can create a blank pipeline or you can create a pipeline from a sample. Use sample pipelines to quickly design pipelines for typical use cases.
- Provisioning Data Collectors
-
You can now automatically provision Data Collectors on a Kubernetes container orchestration framework. Provisioning includes deploying, registering, starting, scaling, and stopping Data Collector Docker containers in the Kubernetes cluster.
Use provisioning to reduce the overhead of managing a large number of Data Collector instances. Instead, you can manage a central Kubernetes cluster used to run multiple Data Collector containers.
- Integration with Data Collector Edge
-
Control Hub now works with Data Collector Edge (SDC Edge) to execute edge pipelines. SDC Edge is a lightweight agent without a UI that runs pipelines on edge devices with limited resources. Edge pipelines read data from the edge device or receive data from another pipeline and then act on that data to control the edge device.
You install SDC Edge on edge devices, then register each SDC Edge with Control Hub. You assign labels to each SDC Edge to determine which jobs are run on that SDC Edge.
You either design edge pipelines in the Control Hub Pipeline Designer or in a development Data Collector. After designing edge pipelines, you publish the pipelines to Control Hub and then add the pipelines to jobs that run on a registered SDC Edge.
- Pipeline comparison
-
When you compare two pipeline versions, Control Hub now highlights the differences between the versions in the pipeline canvas. Previously, you had to visually compare the two versions to discover the differences between them.
- Balancing jobs
-
When a job is enabled for pipeline failover, you can now balance the job to redistribute the pipeline load across available Data Collectors that are running the fewest number of pipelines. For example, let’s say that a failed pipeline restarts on another Data Collector due to the original Data Collector shutting down. When the original Data Collector restarts, you can balance the job so that Control Hub redistributes the pipeline to the restarted Data Collector not currently running any pipelines.
- Roles
-
You can now assign provisioning roles to user accounts, which enable users to view and work with Provisioning Agents and deployments to automatically provision Data Collectors.
You must assign the appropriate provisioning roles to users before they can access the Provisioning Agents and Deployments views in the Navigation panel.
- Navigation panel
-
The Navigation panel now groups the Data Collectors view under an Execute menu, along with the new Edge Data Collectors, Provisioning Agents, and Deployments views:
- Dashboards
-
The default dashboard now includes the number of users in your organization when your user account has the Organization Administrator role.
September 22, 2017
- When the pipeline repository contains more than 50 pipelines, creating a job from the Pipeline Repository view might fail.
- Data Collector version 2.7.0.0 cannot report remote pipeline status to DPM.
- If a job fails over to another Data Collector, DPM continues to store acknowledgement messages from the previous Data Collector that is no longer running a remote pipeline for the job. This can cause performance issues when you try to view a large number of jobs in DPM.
August 9, 2017
This release includes the following new features and enhancements:
- Jobs
-
- Number of pipeline instances - The default value for the
number of pipeline instances for a job is now 1. This runs one pipeline
instance on an available Data Collector running the fewest number of pipelines.
Previously, the default value for the number of pipeline instances was -1, which ran one pipeline instance on each available Data Collector. For example, if three Data Collectors had all of the specified labels for the job, by default DPM ran three pipeline instances, one on each Data Collector.
- Job
history - When you monitor a job, the History tab now
includes the following additional information:
- All user actions completed on the job - such as when a user starts, stops, resets the offset, or acknowledges an error for the job.
- The progress of all Data Collectors running remote a pipeline instance for the job - such as when each Data Collector starts and stops the remote pipeline instance.
- Inactive job status when pipelines finish - When all pipelines run from an active job reach a finished state, the job now transitions to an inactive status. Previously, the job remained in the active status.
- Number of pipeline instances - The default value for the
number of pipeline instances for a job is now 1. This runs one pipeline
instance on an available Data Collector running the fewest number of pipelines.
- Data Collectors
-
- Data Collector versions - The Data Collectors view now displays the version of each registered Data Collector. You can filter the list of registered Data Collectors by version.
- Registering Data Collectors from DPM - After you generate an authentication token to register a Data Collector from DPM, you can now simply click Copy Token to copy the token from the Authentication Tokens window. Previously, you had to select the entire token string, right-click, and then select Copy to copy the token.
- Roles
-
You can now assign the Auth Token Administrator role to user accounts, which enables users to complete the following tasks:
- Register, unregister, and deactivate Data Collectors using DPM.
- Regenerate authentication tokens and delete unregistered authentication tokens.
June 17, 2017
This release includes the following new features and enhancements:
- SAML authentication
- If your company uses a Security Assertion Markup Language (SAML) identity provider (IdP), you can use the IdP to authenticate DPM users.
- Send pipeline statistics directly to DPM
- You can now use Data Collector to configure a pipeline to write statistics directly to DPM. Write statistics directly to DPM when you run a job for the pipeline on a single Data Collector.
- Jobs
-
- Runtime
parameters - You can now specify the values to use for
runtime parameters when you create or edit a job that includes a
pipeline with runtime parameters.
You configure runtime parameters for a pipeline in Data Collector. Use runtime parameters to represent any stage or pipeline property with a value that must change for each pipeline run - such as batch sizes and timeouts, directories, or URI.
After you publish the pipeline to DPM, you can change the parameter values for each job that runs the pipeline without having to edit the pipeline.
- Use latest pipeline version - DPM now notifies you when a
job includes a pipeline that has a later version by displaying the New
Pipeline Version icon (
 ) next to the job. When the job is inactive,
you can simply click the icon to update the job to use the latest
pipeline version.
) next to the job. When the job is inactive,
you can simply click the icon to update the job to use the latest
pipeline version. - Filter jobs by label - You can now filter jobs by label in the Jobs view.
- Create jobs for multiple pipelines - You can now use the Pipeline Repository view to select multiple pipelines and then create jobs for each of the pipelines.
- Create multiple jobs for a single pipeline - In the Add Job window, you can now choose to create multiple jobs for the selected pipeline. For example, if you use runtime parameters, you can quickly create multiple jobs for the same pipeline, defining different values for the runtime parameters for each job.
- Add to a topology during job creation - You can now add a job to an existing topology when you create the job.
- Create a topology from the Jobs view - You can now select multiple jobs in the Jobs view and create a topology that includes those jobs.
- Runtime
parameters - You can now specify the values to use for
runtime parameters when you create or edit a job that includes a
pipeline with runtime parameters.
- Topologies
-
- Manage
jobs from a topology - You can now perform the following
actions for jobs from a topology:
- Acknowledge errors for a job.
- Force stop a job.
- Start and stop all jobs.
- Auto discover connecting systems - DPM can now automatically discover connecting systems between jobs in a topology. DPM discovers possible connecting systems and then offers you suggestions of how you might want to connect the systems, which you can accept or reject.
- Display of topology details - Topology details now display on the right
side of the canvas instead of on the bottom. Double-click the canvas or
click the Open Detail Pane arrow to display the
topology detail pane. You can close the detail pane to view the canvas
only, or you can resize the detail pane.
The following image shows the new display of topology details:
- Manage
jobs from a topology - You can now perform the following
actions for jobs from a topology:
- Notifications
-
When you click the Notifications icon (
 ) in the top toolbar, you can now view the
following notifications:
) in the top toolbar, you can now view the
following notifications:- Triggered alerts - Displays all triggered alerts that have not been acknowledged.
- History of error messages - Displays recent error messages that briefly displayed in the UI.
April 15, 2017
- Pipeline Failover
- DPM now supports pipeline failover for jobs. Enable pipeline failover for jobs to minimize downtime due to unexpected pipeline failures and to help you achieve high availability. By default, pipeline failover is disabled for all jobs.
March 4, 2017
This release includes the following new features and enhancements:
- Groups
- You can now create groups of users to more efficiently manage user accounts. You can assign roles and permissions to individual user account or to groups.
- Permissions
- You can now can share and grant permissions on Data Collectors, pipelines, jobs, topologies, and data SLAs. Permissions determine the access level that users and groups have on objects belonging to the organization.
- Data SLAs for Topologies
- You can now configure data SLAs (service level agreements) for topologies. Data SLAs trigger an alert when a specified threshold has been reached. You configure data SLAs on the jobs included in the topology. Data SLAs enable you to monitor incoming data to ensure that it meets business requirements for availability and accuracy.
- Job Offsets
- The job History view now displays the last-saved job offset sent by each Data Collector running a remote pipeline instance for the job.
- Register Data Collectors with DPM
- If Data Collector uses file-based authentication and if you register the Data Collector from the Data Collector UI, you can now create DPM user accounts and groups during the registration process.
- Organization Configuration
- You can now configure the following information for your organization:
- Maximum number of minutes that a user session can remain inactive before timing out.
- Maximum number of days that a user password is valid.
Known Issues
There are no known issues at this time.