Snowflake Table Destination
The Snowflake Table destination writes data to a single Snowflake table. To write to more than one table, use additional destinations.
When you configure the destination, you specify the table to write to and whether the destination should create the table if it does not exist. You define the write mode and related properties. You can also enable data drift handling, which updates the target table when the pipeline rows contain unexpected data.
Table Creation
The Snowflake Table destination can create a table before writing to it. When you enable the Create Table property, the Snowflake Table destination creates a table based on the data to be written to the table. The destination then writes to the table based on the selected write mode and related properties.
On subsequent pipeline runs, the Snowflake Table destination writes to the table based on the write mode and related properties. It does not drop and recreate the table.
Write Mode
The write mode defines how the Snowflake Table destination writes to an existing table, including the second batch to a table that the destination created.
- Append to table
- The destination appends rows to an existing table.
- Overwrite table
- The destination removes all rows in the existing table before writing new
rows to the table. When you use this option, you also specify the overwrite
mode to use:
- Drop Table - Drops the existing table, creates a new table based on pipeline data, and then writes to the table.
- Truncate Table - Truncates the data in the existing table, then writes to the table.
- Merge rows in table by condition
- The destination merges data to an existing table based on the configured merge keys and other merge properties.
- Propagate updates from Slowly Changing Dimension processor
- The destination inserts and updates rows provided by the Slowly Changing Dimension processor.
Merging Data
- Autocalculate Merge
- When the destination automatically calculates the merge, information in the
following row columns determines how each row is written to the target
table:
__SS_META_KEYS- List of columns to use as keys.__SS_META_OPERATION- Operation to perform for the row. Uses the following values:- 1 - Insert
- 2 - Update
- 3 - Delete
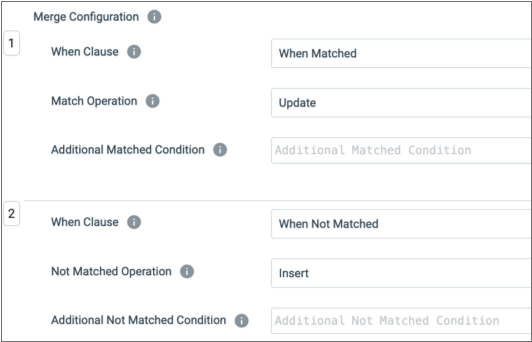
- Merge Configuration
- When the destination uses merge configuration properties, you define one or
more sets of configuration properties. Typically, you specify at least one
WHEN MATCHEDand oneWHEN NOT MATCHEDclause. Specify sets of configuration properties in the order that they should appear in the SQL query. - For example, you might use the following configuration properties to update
existing rows and insert all new rows:
Data Drift Handling
You can configure the Snowflake Table destination to handle data drift. Data drift is an unexpected change in the structure or format of the data, such as additional columns or column data changing from integer to decimal data.
When handling data drift, the destination updates the target table to enable writing data with these unexpected changes to the table. Enable data drift only when you want to enable data with unexpected shifts in data structures to be written to the target table.
Do not enable data drift when you do not expect shifts in data structure or types and do not want such rows to be written to the destination, or when you simply do not want the target table to be changed based on incoming data.
- If the table does not exist, the destination creates the table
- If pipeline data includes a column that the target table does not, the
destination issues an ALTER TABLE ADD COLUMN statement to add all required
columns.
String columns are created as Varchar(n) where n is based on the maximum precision for the column in the first batch being written.
This ensures that the source and target table have the same structure.
Configuring a Snowflake Table Destination
Configure a Snowflake Table destination to write data to a single Snowflake table. To write to more than one table, use additional destinations.
-
On the General tab, configure the following
properties:
General Property Description Name Stage name. Description Optional description. -
On the Table tab, configure the following
properties:
Table Property Description Table Table to write to. Use one of the following methods to define this property: - Select from lists - Click the first text box and select the database to
use. Click the second text box and select the schema to use. Click the third text box and select
the table to use.
If the table does not exist, you can enter the name of the table to create.
- Explore and select - Click the Select Table icon to explore your Snowflake account and navigate to thetable to use.
The specified table becomes the name of the stage. When needed, you manually enter a stage name on the General tab. If you select a new table for the stage, the name of the selected table overrides the manually-entered stage name.
Write Mode Write mode to use. Overwrite Mode Overwrite mode to use. Available when overwriting the table.
Create Table Enables creating the specified table if it does not exist. Data Drift Enabled Automatically compensates for new or missing data in pipeline rows. Enables adding new columns to the table and populating missing columns with null values. - Select from lists - Click the first text box and select the database to
use. Click the second text box and select the schema to use. Click the third text box and select
the table to use.