SQL Server 2019 BDC Bulk Loader (deprecated)
The SQL Server 2019 BDC Bulk Loader destination writes data to Microsoft SQL Server 2019 Big Data Cluster (BDC) using a bulk insert. For information about supported versions, see Supported Systems and Versions in the Data Collector documentation.
The destination writes data from record fields to table columns based on matching names. You can configure the destination to automatically handle data drift in SQL Server tables. The destination can create new SQL Server or external tables when new table references appear in records, and the destination can create new SQL Server columns when new field references appear in records. The destination cannot write data from record fields that store data in the Map, List, List_map, or File_ref data types.
When you configure the destination, specify connection information, including the database, schema, and table to write to, and the number of connections used. You can specify a row field that lists the fields to include in each row written to the table or you can have the destination write all rows except specified fields. You can also configure the destination to replace missing fields or fields containing invalid data types with specified default values, and to replace newline characters in string fields with a specified character.
Before you use the SQL Server 2019 BDC Bulk Loader destination, you must install the SQL Server 2019 Big Data Cluster stage library as a custom stage library and complete other prerequisite tasks.
Prerequisites
- Ensure you have access to SQL Server 2019 BDC with SQL Server credentials.
- Install the SQL Server 2019 Big Data Cluster stage library.
- Retrieve the JDBC URL needed to connect to SQL Server 2019 BDC, and use the URL to configure the destination.
Install the SQL Server 2019 Big Data Cluster Stage Library
You must install the SQL Server 2019 Big Data Cluster stage library before using the SQL Server 2019 BDC Bulk Loader destination. The SQL Server 2019 Big Data Cluster stage library includes the JDBC driver that the destination uses to access SQL Server 2019 BDC.
- Install the library in an existing Data Collector as a custom stage library.
- If using Control Hub, install the library in a provisioned Data Collector container that is part of an orchestration framework, such as Kubernetes. Use
a technique valid for your environment:
- In a production environment, see the Control Hub topic Provision Data Collectors. You must install the SQL Server 2019 Big Data Cluster stage library in the customized StreamSets Data Collector Docker image.
- In a development environment, you can run the StreamSets-developed deployment script to try SQL Server 2019 BDC with Data Collector through Control Hub.
The script deploys a Control Hub Provisioning Agent and Data Collector on a Kubernetes cluster. The script automatically installs the SQL Server 2019 Big Data Cluster stage library in the deployed Data Collector. You can use that Data Collector as an authoring Data Collector to create and test SQL Server 2019 BDC pipelines.
Use the script in development environments only. For more information, see the deployment script in Github.
Installing as a Custom Stage Library
You can install the SQL Server 2019 Big Data Cluster stage library as a custom stage library on a tarball, RPM, or Cloudera Manager Data Collector installation.
- To download the stage library, go to the StreamSets archives page.
- Under StreamSets Enterprise Connectors, click Enterprise Connectors.
-
Click the stage library name and version that you want to download.
The stage library downloads.
-
Install and manage the stage library as a custom stage library.
For more information, see Custom Stage Libraries in the Data Collector documentation.
External Tables
In SQL Server 2019 BDC, you can define external tables that access data virtualized in SQL Server. For more information, see the Microsoft documentation.
- Set the Database property to the SQL Server database where SQL Server 2019 BDC virtualizes the external table.
- Set the Table property to include the name of the external table.
To configure the SQL Server 2019 BDC Bulk Loader destination to write to a new external table when handling changes to tables, see Changes to Tables
Enabling Data Drift Handling
You can configure the SQL Server 2019 BDC Bulk Loader destination to automatically handle changes to columns or tables, also known as data drift.
For example, if a record suddenly includes a new
Address2 field, a destination configured to handle column changes
creates a new Address2 column in the target table. Similarly, if the
destination writes data to tables based on the region name in the
Region field and a new SW-3 region shows up in a
record, a destination configured to handle table changes creates a new
SW-3 table and writes the record to the new table.
You can use the data drift functionality to create all necessary tables in an empty database schema.
Changes to Columns
By default, the destination creates new columns based on the data in the new fields, such as creating a Double column for decimal data. You can, however, configure the destination to create all new columns as Varchar.
Changes to Tables
In destinations configured to create new columns when data drift occurs, you can also configure the destination to create new tables as needed. Select the Table Auto Create property. By default, the destination creates these new tables as SQL Server tables.
To have the destination create new tables as external tables, select the External Tables property, and then configure the external tables on the External Table tab. The destination requires the external data source and external file format, which you create in SQL Server 2019 BDC. For more information, see the Microsoft documentation.
For example, suppose you created an external data source named
mydatasource in SQL Server 2019 BDC to write to Hadoop. You also created an external file format named
myfileformat to write data in text-delimited format. You want to
configure the destination to process employee data. When data drift requires new tables,
you want the destination to write them to external tables in the
/webdata/employee.tbl file in Hadoop. On the JDBC tab, you
select the Table Auto Create property and the External Tables property. You configure
the External Table tab as follows:
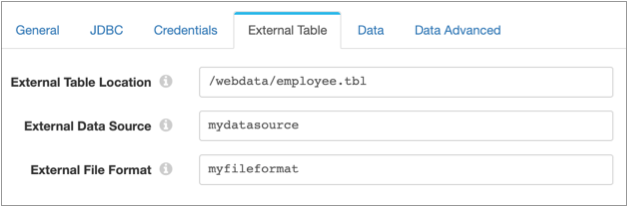
ClickStream, which contains the fields url,
event_date, and user_IP. The destination
automatically creates the following SQL statement to create the external
table:CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;Generated Data Types
When creating new tables or creating new columns in existing tables, the SQL Server 2019 BDC Bulk Loader destination generates the new column names based on the field names and the column data types based on the type of data in the field.
| Record Field Data Type | SQL Server 2019 BDC Column Data Type |
|---|---|
| Boolean | Bit |
| Byte | Tinyint |
| Byte_array | Binary |
| Char | Char |
| Date | Date |
| Datetime | Datetime |
| Decimal | Decimal |
| Float | Real |
| Integer | Int |
| Long | Bigint |
| Short | Smallint |
| String | Varchar |
| Time | Time |
| Zoned_datetime | Datetimeoffset |
Row Generation
By default, the SQL Server 2019 BDC Bulk Loader destination includes all fields from a record in the row written to the SQL Server 2019 BDC table. You can configure the destination to include only specified fields.
In the Row Field property, you specify a map
or list-map field in the record that contains all the data that the destination writes
from the record. By default, the property is set to the root field, /,
and the destination writes all the fields from the record. If you specify a map or
list-map field, the destination writes only the data from the fields in the specified
map or list-map field and excludes all other record data. Edit the Row Field property
when the data that you want to write to SQL Server 2019 BDC
exists in a single map or list-map field within the record.
If you do not want to include all fields and do not have a map or list-map field that contains the fields you want included, you can configure the destination to ignore specific fields. Edit the Fields to Ignore property to list the fields that you do not want written.
By default, the destination treats records with missing fields or with invalid data types in fields as error records. You can configure the destination to replace missing fields and data of invalid types with default values. You can also specify the default values to use for each data type. You can also configure the destination to replace newline characters in string fields with a replacement character.
Configuring a SQL Server 2019 BDC Bulk Loader Destination
Configure a SQL Server 2019 BDC Bulk Loader destination to write data to SQL Server 2019 BDC. Before you use the destination in a pipeline, complete the required prerequisites.
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline. Not valid for cluster pipelines.
-
On the JDBC tab, configure the following properties:
JDBC Property Description JDBC Connection String String used to connect to SQL Server 2019 BDC with the JDBC driver. The connection string requires the following format:jdbc:sqlserver://<ip>:<port>By default, the property contains an expression language function:jdbc:sqlserver://${sqlServerBDC:hostAndPort("master-svc-external")}The function searches the $SDC_RESOURCES/sql-server-bdc-resources folder for the sql-server-ip-and-port.json file. In the file, the function searches for the JSON object with the key-value pair
"serviceName":"master-svc-external"and uses the IP address and port specified by theipandportkeys in that object.If you installed the SQL Server 2019 Big Data Cluster stage library with the deployment script, you can use the default string because the script automatically creates the file that the function needs.
If you did not use the deployment script, you can either edit the connection string to specify the IP address and port, or you can use the default string and create the needed file with the following JSON object:
{ "serviceName": "master-svc-external", "ip": "<IP address>", "port": <port number> }Database Database in SQL Server 2019 BDC to write to. To write to an external table, specify the SQL Server database where SQL Server 2019 BDC virtualizes the external table.
Schema Schema from SQL Server 2019 BDC used to write records. Table Table in SQL Server 2019 BDC to write to. Data Drift Enabled Creates new columns in existing tables when records contain new fields. Note: SQL Server 2019 BDC cannot create new columns in existing external tables.Table Auto Create Creates tables automatically when needed. Available when the Data Drift Enabled property is selected. External Tables Creates new tables as external tables. Available when the Table Auto Create property is selected. If you select this property, you also need to configure properties on the External Table tab.
Create New Columns as VARCHAR Creates all new columns as Varchar columns. By default, the destination creates new columns based on the type of data in the field. Available when the Data Drift Enabled property is selected. Connection Pool Size Maximum number of connections used to write to SQL Server 2019 BDC. With the default, 0, the destination sets the number of connections to the number of threads that the pipeline uses. Connection Properties Additional properties used to connect to SQL Server 2019 BDC. To add properties, click Add and define the property name and value. Enter property names and values as expected by JDBC.
Upper Case Schema & Field Names Converts all database, schema, table, and column names, as well as field names used for column names, to all uppercase letters. This also applies to the names of any new tables or columns the destination creates to handle data drift. Quote Object Names Includes quotes around database, table, and column names in statements. Select when the databases, tables, or columns were created using quotation marks or when the database, table, or column names have lowercase or mixed-case names. -
On the Credentials tab, configure the following
properties:
Credentials Property Description User SQL Server 2019 BDC user name. Password Password for the user. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores. For more information about credential stores, see Credential Stores in the Data Collector documentation. -
On the External Table tab, configure the following
properties for the destination to create new tables as external tables when
handling changes to tables:
External Table Property Description External Table Location Folder or file path and file name in Hadoop or Azure Blob Storage where the destination writes data. Specify the location from the root folder. The root folder is the data location set in the external data source. External Data Source Name of the external data source where the destination writes data. External File Format Name of the object that stores the file format type and other properties for external data. You create the object in SQL Server 2019 BDC through a tool like Azure Data Studio. -
On the Data tab, configure the following properties:
Data Property Description Row Field Map or list-map field that contains the fields written to the row in SQL Server 2019 BDC. With the default value, /, the destination includes all fields from the record in the written row.Fields to Ignore Comma-separated list of fields to ignore. Field names are case sensitive. Null Value Characters written to replace null values. Default is NULL. -
On the Data Advanced tab, configure the following
properties:
Data Advanced Property Description Ignore Missing Fields Writes the default value for missing fields rather than creating an error record. Writes the default value specified for the expected data type. Ignore Fields with Invalid Types Replaces values that are invalid data types rather than creating an error record. Writes the default value specified for the expected data type. BINARY Default Size Default size of Binary fields, in bytes. Enter a value between 1 and 8,000. Default is 8,000. CHAR Default Size Default size of Char fields, in bytes. Enter a value between 1 and 8,000. Default is 8,000. DECIMAL Default Precision Maximum number of digits stored in Decimal fields. This includes the digits on both sides of the decimal. Enter a value between 1 and 38. Default is 18. DECIMAL Default Scale Number of digits stored to the right of the decimal in Decimal fields. Enter a value between 0 and the decimal precision. Default is 0. FLOAT Default Size Default size of Float fields, in mantissa bits. Enter a value between 1 and 53. Default is 53. VARCHAR Default Size Default string size of Varchar fields, in bytes. Maximum size is 8,000. Default is 8,000. Enter 0 or a negative value to set to the maximum storage size, 2 GB. TIME Default Fractional Seconds Scale Number of digits stored for the fractional part of seconds in Time fields. Enter a value between 0 and 7. Default is 7. DATETIMEOFFSET Default Fractional Seconds Precision Number of digits stored for the fractional part of seconds in Datetimeoffset fields. Enter a value between 0 and 7. Default is 7. BIGINT Default Default value stored in Bigint fields when ignoring missing fields or when fields contain invalid data types. Default is Null. BINARY Default Default value stored in Binary fields when ignoring missing fields or when fields contain invalid data types. Enter a hexadecimal value without a 0xprefix. Default is Null.BIT Default Default value stored in Bit fields when ignoring missing fields or when fields contain invalid data types. Default is Null. CHAR Default Default value stored in Char fields when ignoring missing fields or when fields contain invalid data types. Default is Null. DATE Default Default value stored in Date fields when ignoring missing fields or when fields contain invalid data types. Default is Null. DATETIME Default Default value stored in Datetime fields when ignoring missing fields or when fields contain invalid data types. Default is Null. DATETIME2 Default Default value stored in Datetime2 fields when ignoring missing fields or when fields contain invalid data types. Default is Null. DATETIMEOFFSET Default Default value stored in Dateimteoffset fields when ignoring missing fields or when fields contain invalid data types. Default is Null. DECIMAL Default Default value stored in Decimal fields when ignoring missing fields or when fields contain invalid data types. Default is Null. FLOAT Default Default value stored in Float fields when ignoring missing fields or when fields contain invalid data types. Default is Null. IMAGE Default Default value stored in Image fields when ignoring missing fields or when fields contain invalid data types. Default is Null. INT Default Default value stored in Int fields when ignoring missing fields or when fields contain invalid data types. Default is Null. MONEY Default Default value stored in Money fields when ignoring missing fields or when fields contain invalid data types. Default is Null. NCHAR Default Default value stored in Nchar fields when ignoring missing fields or when fields contain invalid data types. Default is Null. NVARCHAR Default Default value stored in NVarchar fields when ignoring missing fields or when fields contain invalid data types. Default is Null. NTEXT Default Default value stored in Ntext fields when ignoring missing fields or when fields contain invalid data types. Default is Null. NUMERIC Default Default value stored in Numeric fields when ignoring missing fields or when fields contain invalid data types. Default is Null. REAL Default Default value stored in Real fields when ignoring missing fields or when fields contain invalid data types. Default is Null. SMALLINT Default Default value stored in Smallint fields when ignoring missing fields or when fields contain invalid data types. Default is Null. SMALLDATE Default Default value stored in Smalldate fields when ignoring missing fields or when fields contain invalid data types. Default is Null. SMALLMONEY Default Default value stored in Smallmoney fields when ignoring missing fields or when fields contain invalid data types. Default is Null. TEXT Default Default value stored in Text fields when ignoring missing fields or when fields contain invalid data types. Default is Null. TIME Default Default value stored in Time fields when ignoring missing fields or when fields contain invalid data types. Default is Null. TINYINT Default Default value stored in Tinyint fields when ignoring missing fields or when fields contain invalid data types. Default is Null. VARBINARY Default Default value stored in Varbinary fields when ignoring missing fields or when fields contain invalid data types. Default is Null. VARCHAR Default Default value stored in Varchar fields when ignoring missing fields or when fields contain invalid data types. Default is Null. XML Default Default value stored in Xml fields when ignoring missing fields or when fields contain invalid data types. Default is Null. Replace Newlines Replaces newline characters with a specified character. Newline Replacement Character Character used to replace newline characters. Available when the Replace Newlines property is selected. Default is |.