Dataflow Triggers
Dataflow Triggers Overview
Dataflow triggers are instructions for the event framework to kick off tasks in response to events that occur in the pipeline. For example, you can use dataflow triggers to start a MapReduce job after the pipeline writes a file to HDFS. Or you might use a dataflow trigger to stop a pipeline after the JDBC Query Consumer origin processes all available data.
- event generation
- The event framework generates pipeline-related events and stage-related events. The framework generates pipeline events only when the pipeline starts and stops. The framework generates stage events when specific stage-related actions take place. The action that generates an event differs from stage to stage and is related to how the stage processes data.
- task execution
- To trigger a task, you need an executor. Executor stages perform tasks in Data Collector or external systems. Each time an executor receives an event, it performs the specified task.
- event storage
- To store event information, pass the event to a destination. The destination writes the event records to the destination system, just like any other data.
Pipeline Event Generation
The event framework generates pipeline events in Data Collector standalone pipelines at specific points in the pipeline lifecycle. You can configure the pipeline properties to pass each event to an executor or to another pipeline for more complex processing.
- Pipeline Start
- The pipeline start event is generated as the pipeline initializes, immediately after it starts and before individual stages are initialized. This can allow time for an executor to perform a task before stages initialize.
- Pipeline Stop
- The pipeline stop event is generated as the pipeline stops, either manually, programmatically, or due to a failure. The stop event is generated after all stages have completed processing and cleaning up temporary resources, such as removing temporary files. This allows an executor to perform a task after pipeline processing is complete, before the pipeline fully stops.
- Virtual processing - Unlike stage events, pipeline events are not
processed by stages that you configure in the canvas. They are passed to an
event consumer that you configure in the pipeline properties.
The event consumer does not display in the pipeline’s canvas. As a result, pipeline events are also not visualized in data preview.
- Single-use events - You can configure only one event consumer for each
event type within the pipeline properties: one for the Start event and one for
the Stop event.
When necessary, you can pass pipeline events to another pipeline. In the event consuming pipeline, you can include as many stages as you need for more complex processing.
For a solution that describes a couple ways to use pipeline events, see Offloading Data from Relational Sources to Hadoop.
Using Pipeline Events
You can configure pipeline events in standalone pipelines. When you configure a pipeline event, you can configure it to be consumed by an executor or another pipeline.
Pass an event to an executor when the executor can perform all of the tasks that you need. You can configure one executor for each event type.
Pass an event to another pipeline when you need to perform more complex tasks in the consuming pipeline, such as passing the event to multiple executors or to an executor and destination for storage.
Pass to an Executor
You can configure a pipeline to pass each event type to an executor stage. This allows you to trigger a task when the pipeline starts or stops. You configure the behavior for each event type separately. And you can discard any event that you do not want to use.
- In the pipeline properties, select the executor that you want to consume the event.
- In the pipeline properties, configure the executor to perform the task.
Example
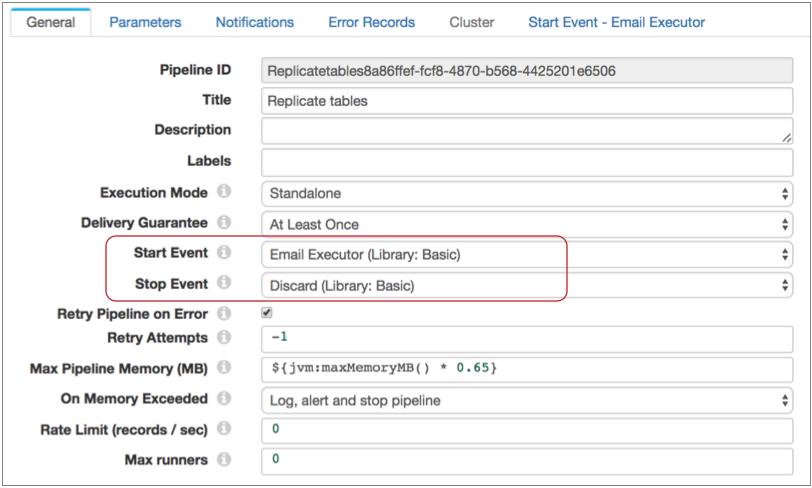
Say you want to send an email when the pipeline starts. First, you configure the pipeline to use the Email executor for the pipeline start event. Since you don't need the Stop event, you can simply use the default discard option:
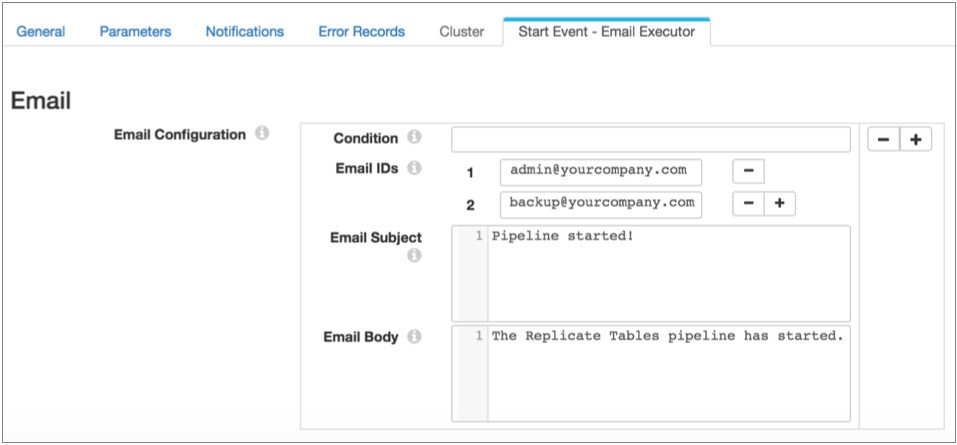
Then, also in the pipeline properties, you configure the Email executor. You can configure a condition for the email to be sent. If you omit the condition, the executor sends the email each time it receives an event:
Stage Event Generation
You can configure certain stages to generate events. Event generation differs from stage to stage, based on the way the stage processes data. For details about each the event generation for each stage, see "Event Generation" in the stage documentation.
| Stage | Generates events when the stage... |
|---|---|
| Amazon S3 origin |
For more information, see Event Generation in the origin documentation. |
| Azure Blob Storage origin |
For more information, see Event Generation in the origin documentation. |
| Azure Data Lake Storage Gen2 origin |
For more information, see Event Generation in the origin documentation. |
| Azure Data Lake Storage Gen2 (Legacy) origin |
For more information, see Event Generation in the origin documentation. |
| CONNX origin |
For more information, see Event Generation in the origin documentation. |
| CONNX CDC origin |
For more information, see Event Generation in the origin documentation. |
| Directory origin |
For more information, see Event Generation in the origin documentation. |
| File Tail origin |
For more information, see Event Generation in the origin documentation. |
| Google BigQuery origin |
For more information, see Event Generation in the origin documentation. |
| Google Cloud Storage origin |
For more information, see Event Generation in the origin documentation. |
| Groovy Scripting origin |
For more information, see Event Generation in the origin documentation. |
| Hadoop FS Standalone origin |
For more information, see Event Generation in the origin documentation. |
| JavaScript Scripting origin |
For more information, see Event Generation in the origin documentation. |
| JDBC Multitable Consumer origin |
For more information, see Event Generation in the origin documentation. |
| JDBC Query Consumer origin |
For more information, see Event Generation in the origin documentation. |
| Jython Scripting origin |
For more information, see Event Generation in the origin documentation. |
| MapR FS Standalone origin |
For more information, see Event Generation in the origin documentation. |
| MongoDB origin |
For more information, see Event Generation in the origin documentation. |
| MongoDB Atlas origin |
For more information, see Event Generation in the origin documentation. |
| Oracle Bulkload origin |
For more information, see Event Generation in the origin documentation. |
| Oracle CDC origin |
For more information, see Event Generation in the origin documentation. |
| Oracle CDC Client origin |
For more information, see Event Generation in the origin documentation. |
| Oracle Multitable Consumer origin |
For more information, see Event Generation in the origin documentation. |
| Salesforce origin |
For more information, see Event Generation in the origin documentation. |
| Salesforce Bulk API 2.0 origin |
For more information, see Event Generation in the origin documentation. |
| SAP HANA Query Consumer origin |
For more information, see Event Generation in the origin documentation. |
| SFTP/FTP/FTPS Client origin |
For more information, see Event Generation in the origin documentation. |
| SQL Server CDC Client origin |
For more information, see Event Generation in the origin documentation. |
| SQL Server Change Tracking origin |
For more information, see Event Generation in the origin documentation. |
| Web Client origin |
For more information, see Event Generation in the origin documentation. |
| Windowing Aggregator processor |
For more information, see Event Generation in the processor documentation. |
| Groovy Evaluator processor |
For more information, see Event Generation in the processor documentation. |
| JavaScript Evaluator processor |
For more information, see Event Generation in the processor documentation. |
| Jython Evaluator processor |
For more information, see Event Generation in the processor documentation. |
| TensorFlow Evaluator processor |
For more information, see Event Generation in the processor documentation. |
| Web Client processor |
For more information, see Event Generation in the destination documentation. |
| Windowing Aggregator processor |
For more information, see Event Generation in the processor documentation. |
| Amazon S3 destination |
For more information, see Event Generation in the destination documentation. |
| Azure Blob Storage destination |
For more information, see Event Generation in the destination documentation. |
| Azure Data Lake Storage Gen2 destination |
For more information, see Event Generation in the destination documentation. |
| Google Cloud Storage destination |
For more information, see Event Generation in the destination documentation. |
| Hadoop FS destination |
For more information, see Event Generation in the destination documentation. |
| Hive Metastore destination |
For more information, see Event Generation in the destination documentation. |
| Local FS destination |
For more information, see Event Generation in the destination documentation. |
| MapR FS destination |
For more information, see Event Generation in the destination documentation. |
| SFTP/FTP/FTPS Client destination |
For more information, see Event Generation in the destination documentation. |
| Snowflake File Uploader destination |
For more information, see Event Generation in the destination documentation. |
| Web Client destination |
For more information, see Event Generation in the destination documentation. |
| ADLS Gen2 File Metadata executor |
For more information, see Event Generation in the executor documentation. |
| Amazon S3 executor |
For more information, see Event Generation in the executor documentation. |
| Databricks Job Launcher executor |
For more information, see Event Generation in the executor documentation. |
| Databricks Query executor |
For more information, see Event Generation in the executor documentation. |
| Google BigQuery executor |
For more information, see Event Generation in the executor documentation. |
| Google Cloud Storage executor |
|
| HDFS File Metadata executor |
For more information, see Event Generation in the executor documentation. |
| Hive Query executor |
For more information, see Event Generation in the executor documentation. |
| JDBC Query executor |
For more information, see Event Generation in the executor documentation. |
| MapR FS File Metadata executor |
For more information, see Event Generation in the executor documentation. |
| MapReduce executor |
For more information, see Event Generation in the executor documentation. |
| Snowflake executor |
For more information, see Event Generation in the executor documentation. |
| Spark executor |
For more information, see Event Generation in the executor documentation. |
Using Stage Events
You can use stage-related events in any way that suits your needs. When configuring the event stream for stage events, you can add additional stages to the stream. For example, you might use a Stream Selector to route different types of events to different executors. But you cannot merge the event stream with a data stream.
- Task execution streams that route events to an executor to perform a task.
- Event storage streams that route events to a destination to store event information.
Task Execution Streams
A task execution stream routes event records from the event-generating stage to an executor stage. The executor performs a task each time it receives an event record.
For example, you have a pipeline that reads from Kafka and writes files to HDFS:

When Hadoop FS closes a file, you would like the file moved to a different directory and the file permissions changed to read-only.
Leaving the rest of the pipeline as is, you can enable event handling in the Hadoop FS destination, connect it to the HDFS File Metadata executor, and configure the HDFS File Metadata executor to files and change permissions. The resulting pipeline looks like this:
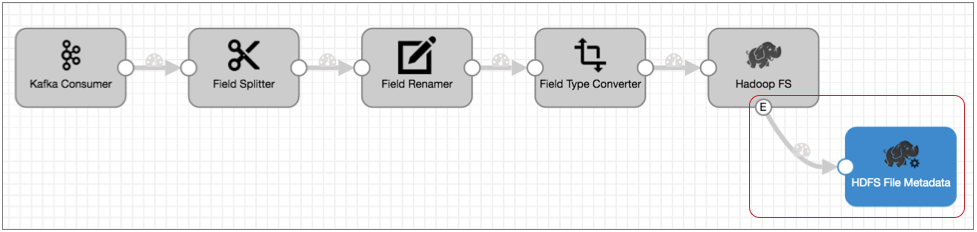
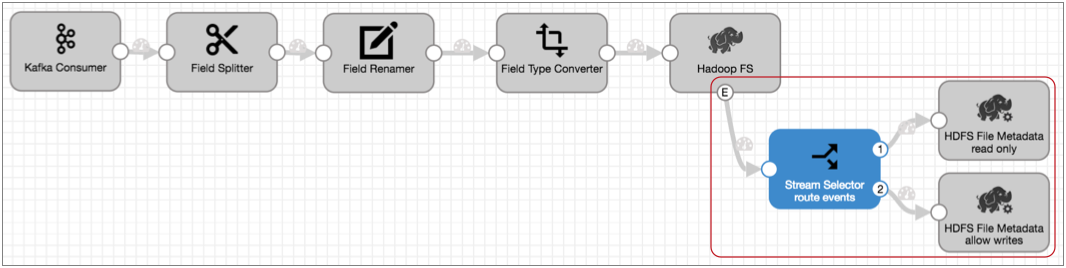
If you needed to set permissions differently based on the file name or location, you could use a Stream Selector to route the event records accordingly, then use two HDFS File Metadata executors to alter file permissions, as follows:
Event Storage Streams
An event storage stream routes event records from the event-generating stage to a destination. The destination writes the event record to a destination system.
Event records include information about the event in record header attributes and record fields. You can add processors to the event stream to enrich the event record before writing it to the destination.
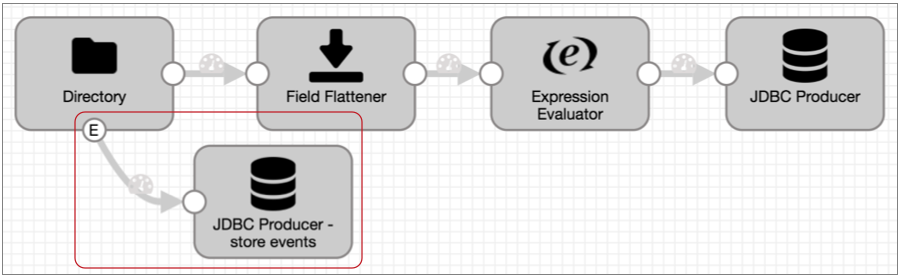
For example, you have a pipeline that uses the Directory origin to process weblogs:

Directory generates event records each time it starts and completes reading a file, and the event record includes a field with the file path of the file. For auditing purposes, you'd like to write this information to a database table.
Leaving the rest of the pipeline as is, you can enable event handling for the Directory origin and simply connect it to the JDBC Producer as follows:
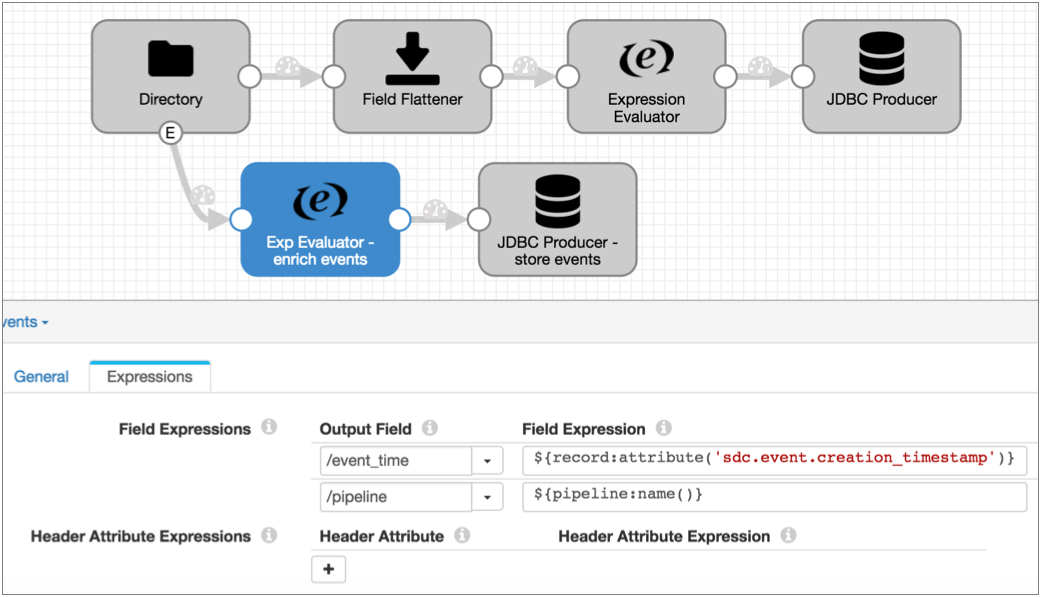
${record:attribute('sdc.event.creation_timestamp')}${pipeline:name()}The Expression Evaluator and the final pipeline looks like this:
Executors
Executors perform tasks when they receive event records.
- ADLS Gen2 File Metadata executor
- Changes file metadata, creates an empty file, or removes a file or directory in Azure Data Lake Storage Gen2 upon receiving an event.
- Amazon S3 executor
- Creates new Amazon S3 objects for the specified content, copies objects within a bucket, or adds tags to existing Amazon S3 objects upon receiving an event.
- Databricks Job Launcher executor
- Starts a Databricks job for each event.
- Databricks Query executor
- Runs a Spark SQL query on Databricks upon receiving an event.
- Email executor
- Sends a custom email to the configured recipients upon receiving an event. You can optionally configure a condition that determines when to send the email.
- Google BigQuery executor
- Runs one or more SQL queries on Google BigQuery upon receiving an event.
- Google Cloud Storage executor
- Creates new Google Cloud Storage objects for the specified content, copies or moves objects within a project, or adds metadata to existing objects upon receiving an event.
- Hive Query executor
- Executes user-defined Hive or Impala queries for each event.
- HDFS File Metadata executor
- Changes file metadata, creates an empty file, or removes a file or directory in HDFS or a local file system upon receiving an event.
- Pipeline Finisher executor
- Stops the pipeline when it receives an event, transitioning the pipeline to a Finished state. Allows the pipeline to complete all expected processing before stopping.
- JDBC Query executor
- Connects to a database using JDBC and runs one or more specified SQL queries.
- MapR FS File Metadata executor
- Changes file metadata, creates an empty file, or removes a file or directory in MapR FS upon receiving an event.
- MapReduce executor
- Connects to HDFS or MapR FS and starts a MapReduce job for each event.
- SFTP/FTP/FTPS Client executor
- Connects to an SFTP, FTP, or FTPS server and moves or removes a file upon receiving an event.
- Shell executor
- Executes a user-defined shell script for each event.
- Snowflake executor
- Loads whole files staged by the Snowflake File Uploader destination to Snowflake tables.
- Spark executor
- Connects to Spark on YARN and starts a Spark application for each event.
Logical Pairings
You can use events in any way that works for your needs. The following tables outline some logical pairings of event generation with executors and destinations.
Pipeline Events
| Pipeline Event Type | Event Consumer |
|---|---|
| Pipeline Start |
|
| Pipeline Stop |
|
Origin Events
| Event Generating Origin | Event Consumer |
|---|---|
| Amazon S3 |
|
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen2 |
|
| Azure Data Lake Storage Gen2 (Legacy) |
|
| CONNX origin |
|
| CONNX CDC origin |
|
| Directory |
|
| File Tail |
|
| Google BigQuery |
|
| Google Cloud Storage |
|
| Hadoop FS Standalone |
|
| JDBC Multitable Consumer |
|
| JDBC Query Consumer |
|
| MapR FS Standalone |
|
| MongoDB |
|
| MongoDB Atlas |
|
| Oracle Bulkload |
|
| Oracle CDC |
|
| Oracle CDC Client |
|
| Oracle Multitable Consumer |
|
| Salesforce |
|
| Salesforce Bulk API 2.0 |
|
| SAP HANA Query Consumer |
|
| SFTP/FTP/FTPS Client |
|
| SQL Server Change Tracking |
|
| Web Client |
|
Processor Events
| Event Generating Processor | Event Consumer |
|---|---|
| Windowing Aggregator |
|
| Groovy Evaluator |
|
| JavaScript Evaluator |
|
| Jython Evaluator |
|
| TensorFlow Evaluator |
|
| Web Client |
|
Destination Events
| Event Generating Destination | Event Consumer |
|---|---|
| Amazon S3 |
|
| Azure Blob Storage |
|
| Azure Data Lake Storage Gen2 |
|
| Google Cloud Storage |
|
| Hadoop FS |
|
| Hive Metastore |
|
| Local FS |
|
| MapR FS |
|
| SFTP/FTP/FTPS Client |
|
| Snowflake File Uploader |
|
Executor Events
| Event Generating Executor | Event Consumer |
|---|---|
| ADLS Gen2 File Metadata executor |
|
| Amazon S3 |
|
| Databricks Job Launcher executor |
|
| Databricks Query executor |
|
| Google BigQuery executor |
|
| Google Cloud Storage executor |
|
| HDFS File Metadata executor |
|
| Hive Query executor |
|
| JDBC Query executor |
|
| MapR FS File Metadata executor |
|
| MapReduce executor |
|
| Snowflake executor |
|
| Spark executor |
|
Event Records
Event records are records that are created when a stage or pipeline event occurs.
Most event records pass general event information in record headers, such as when the event occurred. They also can include event-specific details in record fields, like the name and location of the output file that was closed.
Event records generated by the File Tail origin are the exception - they include all event information in record fields.
Event Record Header Attributes
In addition to the standard record header attributes, most event records include record header attributes for event information such as the event type and when the event occurred.
${record:attribute('sdc.event.creation_timestamp')}Note that all record header attributes are String values. For more information about working with record header attributes, see Record Header Attributes.
| Event Record Header Attribute | Description |
|---|---|
| sdc.event.type | Event type. Defined by the stage that generates the event. For information about the event types available for an event generating stage, see the stage documentation. |
| sdc.event.version | Integer that indicates the version of the event record type. |
| sdc.event.creation_timestamp | Epoch timestamp when the stage created the event. |
Viewing Events in Data Preview and Snapshot
When generated, stage events display in data preview and snapshot as event records. Once a record leaves the event-generating stage, it is treated like a standard record.
Pipeline events generated by the event framework do not display in data preview. However, you can enable data preview to generate and process pipeline events.
Viewing Stage Events in Data Preview and Snapshot
In data preview and when reviewing snapshots of data, stage-related event records display in the event-generating stage marked as "event records," and they appear below the batch of standard records.
After leaving the stage, the record displays like any other record.
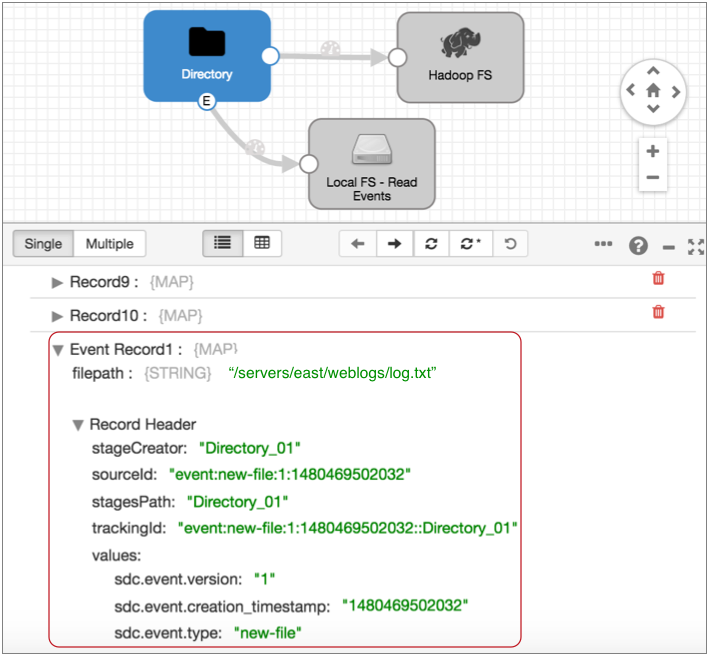
For example, the Directory origin below generates an event record as it starts reading a file for data preview:
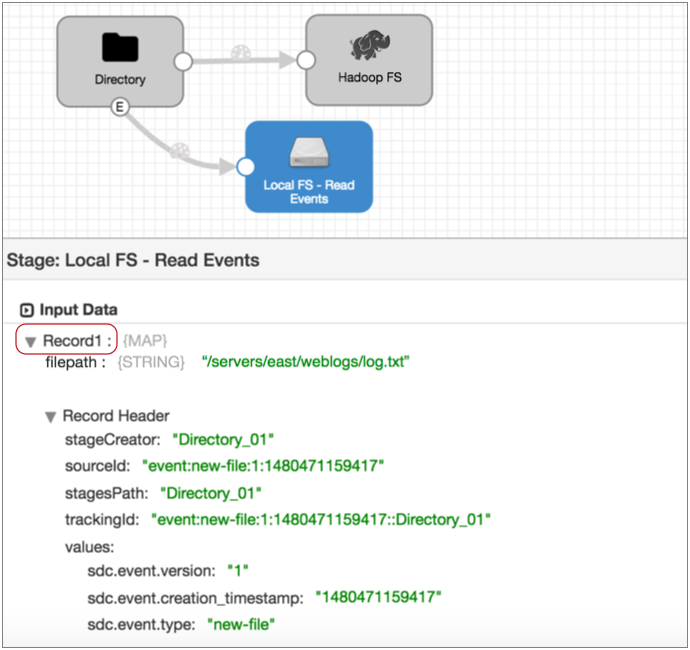
When you select the Local FS destination where the event record is written, you see that the same event record no longer displays the event record label. It is treated like any other record:
Executing Pipeline Events in Data Preview
You can enable pipeline event execution in data preview to test event processing.
When you enable pipeline event generation while previewing data, the event framework generates the pipeline start event when you start data preview and the stop event when you stop data preview. If you configured the pipeline to pass the events to executors or to event-consuming pipelines, the events are passed and trigger the additional processing.
To enable generating pipeline event execution during data preview, use the Enable Pipeline Execution data preview property.
Summary
- You can use the event framework in any pipeline where the logic suits your needs.
- The event framework generates pipeline-related events and stage-related events.
- You can use pipeline events in standalone pipelines.
- Pipeline events are generated when the pipeline starts and stops. For details, see Pipeline Event Generation.
- You can configure each pipeline event type to pass to a single executor or to another pipeline for more complex processing.
- Stage events are generated based on the processing logic of the stage. For a list of event-generating stages, see Stage Event Generation.
- Events generate event records to pass relevant information
regarding the event, such as the path to the file that was closed.
Stage-generated event records differ from stage to stage. For a description of stage events, see "Event Record" in the documentation for the event-generating stage. For a description of pipeline events, see Pipeline Event Records.
- In the simplest use case, you can route stage event records to a destination to save event information.
- You can route stage event records to an executor stage so it can perform a task
upon receiving an event.
For a list of logical event generation and executor pairings, see Logical Pairings.
- You can add processors to event streams for stage events or to consuming
pipelines for pipeline events.
For example, you might add an Expression Evaluator to add the event generation time to an event record before writing it to a destination. Or, you might use a Stream Selector to route different types of event records to different executors.
- When working with stage events, you cannot merge event streams with data streams.
- You can use the Dev Data Generator and To Event development stages to generate events for pipeline development and testing. For more information about the development stages, see Development Stages.
- In data preview, stage-generated event records display separately in the event-generating stage. Afterwards, they are treated like any standard record.
- You can configure data preview to generate and execute pipeline events.
For examples of how you might use the event framework, see the case studies earlier in this chapter.