Converting Data to the Parquet Data Format
This solution describes how to convert Avro files to the columnar format, Parquet.
Let's say that you want to store data on HDFS using the columnar format, Parquet. But Data Collector doesn't have a Parquet data format. How do you do it?
The event framework was created for exactly this purpose. The simple addition of an event stream to the pipeline enables the automatic conversion of Avro files to Parquet.
You can use the Spark executor to trigger a Spark application or the MapReduce executor to trigger a MapReduce job. This solution uses the MapReduce executor.
It's just a few simple steps:
- Create the pipeline you want to use.
Use the origin and processors that you need, like any other pipeline. And then, configure Hadoop FS to write Avro data to HDFS.
The Hadoop FS destination generates events each time it closes a file. This is perfect because we want to convert files to Parquet only after they are fully written.
Note: To avoid running unnecessary numbers of MapReduce jobs, configure the destination to create files as large as the destination system can comfortably handle.
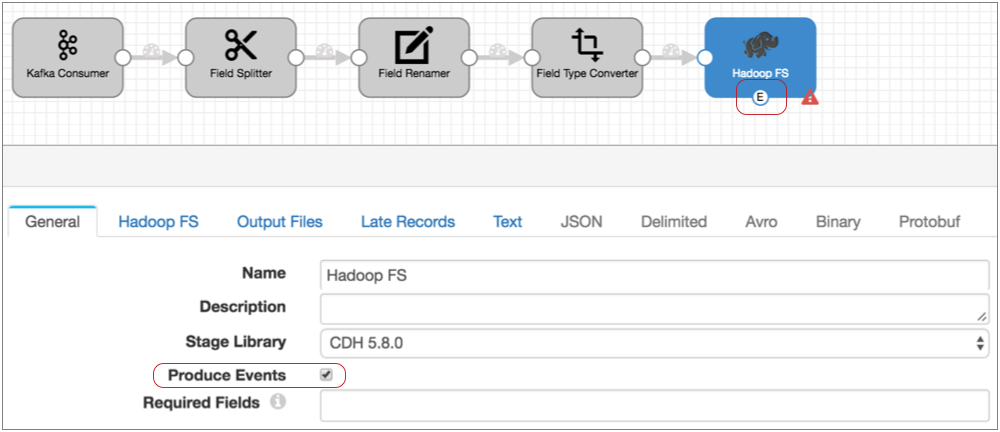
- Configure Hadoop FS to generate events.
On the General tab of the destination, select the Produce Events property.
With this property selected, the event output stream becomes available and Hadoop FS generates an event record each time it closes an output file. The event record includes the file path for the closed file.
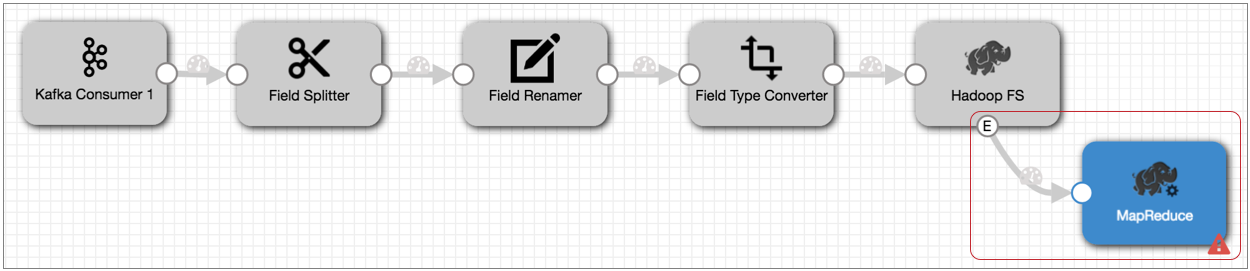
- Connect the Hadoop FS event output stream to a MapReduce executor.
Now, each time the MapReduce executor receives an event, it triggers the jobs that you configure it to run.
- Configure the MapReduce executor to run a job that converts the completed Avro
file to Parquet.
In the MapReduce executor, configure the MapReduce configuration details and select the Avro to Parquet job type. On the Avro Conversion tab, configure the file input and output directory information and related properties:
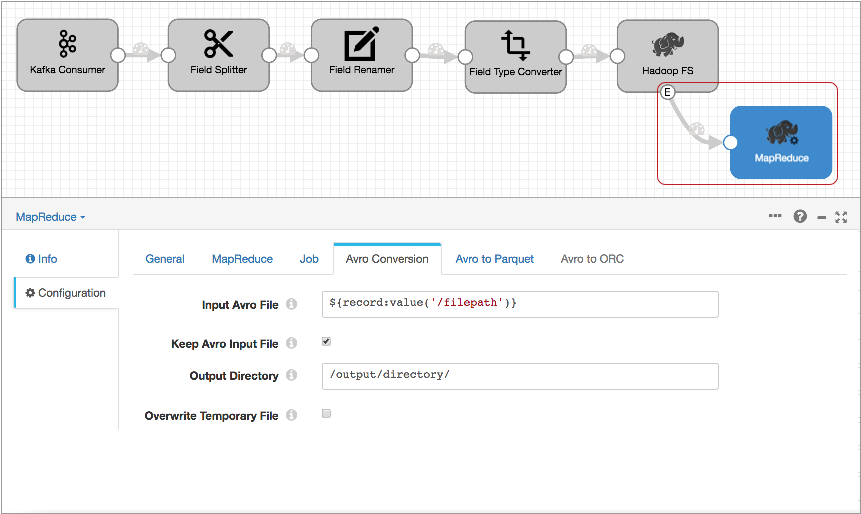
The Input Avro File property default,
${record:value('/filepath')}, runs the job on the file specified in the Hadoop FS file closure event record.Then, on the Avro to Parquet tab, optionally configure advanced Parquet properties.
With this event stream added to the pipeline, each time the Hadoop FS destination closes a file, it generates an event. When the MapReduce executor receives the event, it kicks off a MapReduce job that converts the Avro file to Parquet. Simple!