Oracle CDC Client
The Oracle CDC Client origin processes change data capture (CDC) information provided by Oracle LogMiner redo logs. This is the older Oracle change data capture origin. For new development, use the Oracle CDC origin. For information about supported versions, see Supported Systems and Versions in the Data Collector documentation.
You might use this origin to perform database replication. You can use a separate pipeline with the JDBC Query Consumer or JDBC Multitable Consumer origin to read existing data. Then start a pipeline with the Oracle CDC Client origin to process subsequent changes.
Oracle CDC Client processes data based on the commit number, in ascending order.
The origin includes CDC and CRUD information in record header attributes so generated records can be easily processed by CRUD-enabled destinations. For an overview of Data Collector changed data processing and a list of CRUD-enabled destinations, see Processing Changed Data.
When you configure Oracle CDC Client, you configure change data capture details, such as the schema and tables to read from, how to read the initial change, the dictionary source location, and the operations to include. You also specify the transaction window and LogMiner session windows to use.
You can configure the origin to buffer records locally or to use database buffers. Before using local buffers, verify that the required resources are available and specify the action to take for uncommitted transactions.
You can specify the behavior when the origin encounters an unsupported data type, and you can configure the origin to pass null values when it receives them from supplemental logging data. When the source database has high-precision timestamps, you can configure the origin to write string values rather than datetime values to maintain the precision.
You can specify JDBC connection information and user credentials. You can also use a connection to configure the origin. If the schema was created in a pluggable database, state the pluggable database name. You can configure custom properties that the driver requires.
You can configure advanced connection properties. To use a JDBC version older than 4.0, you specify the driver class name and define a health check query.
The origin can generate events for an event stream. For more information about dataflow triggers and the event framework, see Dataflow Triggers Overview.
When concerned about performance, as when processing very wide tables, you can consider several alternatives to the default origin behavior. You can use the alternate PEG parser or use multiple threads for parsing. Or, you can configure the origin to not parse SQL query statements so you can pass the queries to the SQL Parser processor to be parsed.
For a list of supported operations and a description of generated records, see Parse SQL, Supported Operations, and Generated Records.
LogMiner Dictionary Source
LogMiner provides dictionaries to help process redo logs. LogMiner can store dictionaries in several locations.
- Online catalog - Use the online catalog when table structures are not expected to change.
- Redo logs - Use redo logs when table structures are expected to change. When
reading the dictionary from redo logs, the Oracle CDC Client origin determines
when schema changes occur and refreshes the schema that it uses to create
records. The origin can also generate events for each DDL it reads in the redo
logs. Important: When using the dictionary in redo logs, make sure to extract the latest dictionary to the redo logs each time table structures change. For more information, see Task 4. Extract a LogMiner Dictionary (Redo Logs).
Note that using the dictionary in redo logs can have significantly higher latency than using the dictionary in the online catalog. But using the online catalog does not allow for schema changes.
For more information about dictionary options and configuring LogMiner, see the Oracle LogMiner documentation.
Oracle CDC Client Prerequisites
- Configure the database archiving mode.
- Enable supplemental logging for the database or tables.
- Create a user account with the required roles and privileges.
- To use the dictionary in redo logs, extract the LogMiner dictionary.
- Install the Oracle JDBC driver.
- CDB or multitenant database - A multitenant container database (CDB) that includes one or more pluggable databases (PDB).
- PDB or pluggable database - A database that is part of a CDB.
- Non-CDB database - A standalone database created on earlier versions of Oracle.
Task 1. Enable Database Archiving Mode
LogMiner provides access to database changes stored in redo log files that summarize database activity. The origin uses this information to generate records. LogMiner requires that the database be open, writable, and in ARCHIVELOG mode with archiving enabled.
- Oracle Standard databases
- Use the following steps to determine the status of the database and to
configure the database archiving mode:
- In a SQL shell, log into the database as a user with DBA privileges.
- Check the database logging mode.
For example:
select log_mode from v$database;If the command returns ARCHIVELOG, you can go to "Task 2. Enable Supplemental Logging".
If the command returns NOARCHIVELOG, continue with the following steps.
- Shut down the database.
For example:
shutdown immediate; - Start up and mount the database.
For example:
startup mount; - Enable archiving, open the database, and make it writable.
For example:
alter database archivelog; alter database open read write;
- Oracle RAC and Exadata databases
- Use the following steps to configure the database archiving mode and verify
the status of the database:
- In a Terminal session on one of the database nodes, stop and mount
the database.
For example:
srvctl stop database -d <database name> srvctl start database -d <database name> -o mount - In a SQL shell, log into the database as a user with DBA privileges
and configure the database.
For example:
alter database archivelog; - In the Terminal session, restart the database.
For example:
srvctl stop database -d <database name> srvctl start database -d <database name> - In the SQL shell, check if the database is in logging mode.
For example:
select log_mode from v$database;
- In a Terminal session on one of the database nodes, stop and mount
the database.
Task 2. Enable Supplemental Logging
To retrieve data from redo logs, LogMiner requires supplemental logging at a database level, table level, or a combination of both.
Enable at least primary key or "identification key" logging at a table level for each table that you want to use. With identification key logging, records include only the primary key and changed fields.
To enable supplemental logging for a table, you must first enable minimum supplemental logging for the database.
- Determine the logging that you want to enable.
- Before enabling supplemental logging, check if it is enabled for the database.
For example, you might run the following command on your CDB, then the pluggable database:
select supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all from v$database;If the command returns
YesorImplicitfor all three columns, then minimal supplemental logging is enabled, as well as identification key and full supplemental logging. You can skip to "Task 3. Create a User Account."If the command returns
YesorImplicitfor the first two columns, then supplemental and identification key logging are both enabled. If this is what you want, you can skip to "Task 3. Create a User Account." - Enable minimal supplemental logging. For example, you can run the following command from your CDB or from your non-CDB database:
alter database add supplemental log data; - Optionally, enable identification key logging, if needed.
When enabling identification key logging for a database, do so for the database that contains the schemas to be monitored.
To enable identification key logging for a pluggable database, you must also enable it for the CDB.When enabling identification key logging for individual tables, you don’t need to enable it for the CDB. According to Oracle, best practice is to enable logging for individual tables, rather than the entire CDB. For more information, see the Oracle LogMiner documentation.
For example, you can run the following command to apply the changes to just the container:Enable primary key or full supplemental identification key logging to retrieve data from redo logs. You do not need to enable both:alter session set container=<pdb>;- To enable primary key logging
- You can enable primary key identification key logging for individual tables or all tables in the database:
- To enable full supplemental logging
- You can enable full supplemental identification key logging for individual tables or all tables in the database:
- Submit the changes.
For example:
alter system archive log current;
Task 3. Create a User Account
Create a user account to use with the origin. You need the account to access the database through JDBC.
- 12c, 18c, 19c, or 21c CDB databases
- For Oracle, Oracle RAC, and Oracle Exadata 12c, 18c, 19c, and 21c CDB
databases, create a common user account. Common user accounts are created in
cdb$rootand must use the convention:c##<name>. - 12c, 18c, 19c, or 21c non-CDB databases
- For Oracle, Oracle RAC, and Oracle Exadata 12c, 18c, 19c, and 21c non-CDB
databases, create a user account with the necessary privileges:
- In a SQL shell, log into the database as a user with DBA privileges.
- Create the user account.
For example:
create user <user name> identified by <password>; grant create session, alter session, set container, logmining, select any dictionary, select_catalog_role, execute_catalog_role to <user name>; grant select on database_properties to <user name>; grant select on all_objects to <user name>; grant select on all_tables to <user name>; grant select on all_tab_columns to <user name>; grant select on all_constraints to <user name>; grant select on all_cons_columns to <user name>; grant select on v_$database to <user name>; grant select on gv_$database to <user name>; grant select on v_$instance to <user name>; grant select on gv_$instance to <user name>; grant select on v_$database_incarnation to <user name>; grant select on gv_$database_incarnation to <user name>; grant select on v_$log to <user name>; grant select on gv_$log to <user name>; grant select on v_$logfile to <user name>; grant select on gv_$logfile to <user name>; grant select on v_$archived_log to <user name>; grant select on gv_$archived_log to <user name>; grant select on v_$standby_log to <user name>; grant select on gv_$standby_log to <user name>; grant select on v_$logmnr_parameters to <user name>; grant select on gv_$logmnr_parameters to <user name>; grant select on v_$logmnr_logs to <user name>; grant select on gv_$logmnr_logs to <user name>; grant select on v_$logmnr_contents to <user name>; grant select on gv_$logmnr_contents to <user name>; grant select <db>.<table> to <user name>;Repeat the final command for each table that you want to monitor.
- 11g databases
- For Oracle 11g databases, create a user account with the necessary
privileges:
- In a SQL shell, log into the database as a user with DBA privileges.
- Create the user account.
For example:
create user <user name> identified by <password>; grant create session, alter session, execute_catalog_role, select any transaction, select any table to <user name>; grant select on gv_$database to <user name>; grant select on gv_$archived_log to <user name>; grant select on gv_$instance to <user name>; grant select on gv_$log to <user name>; grant select on v_$database to <user name>; grant select on v_$database_incarnation to <user name>; grant select on v_$logmnr_contents to <user name>; grant select on v_$archived_log to <user name>; grant select on v_$instance to <user name>; grant select on v_$log to <user name>; grant select on v_$logfile to <user name>; grant select on v_$logmnr_logs to <user name>; grant select on <db>.<table> to <user name>;Repeat the final command for each table that you want to mine.
Task 4. Extract a LogMiner Dictionary (Redo Logs)
When using redo logs as the dictionary source, you must extract the LogMiner dictionary to the redo logs before you start the pipeline. Repeat this step periodically to ensure that the redo logs that contain the dictionary are still available.
Oracle recommends that you extract the dictionary only at off-peak hours since the extraction can consume database resources.
alter session set container=cdb$root;
execute dbms_logmnr_d.build(options=> dbms_logmnr_d.store_in_redo_logs);
alter system archive log current;execute dbms_logmnr_d.build(options=> dbms_logmnr_d.store_in_redo_logs);
alter system archive log current;Task 5. Install the Driver
The Oracle CDC Client origin connects to Oracle through JDBC. You cannot access the database until you install the required driver.
Install the Oracle JDBC driver for the Oracle database version that you use. Install the
driver into the JDBC stage library, streamsets-datacollector-jdbc-lib, which includes the origin.
To use the JDBC driver with multiple stage libraries, install the driver into each stage library associated with the stages.
For information about installing additional drivers, see Install External Libraries in the Data Collector documentation.
Available Parsers
- Adaptive LL(*) parser
- Also known as the ALL(*) parser, this parser uses Context-Free Grammar (CFG) to process data. This is the default parser.
- Recursive descent parser
- Also known as the PEG parser, this parser uses Parsing Expression Grammar (PEG) to process data. Due to the simplicity of redo log statements, this parser can generally provide better performance.
Table Configuration
When you configure the Oracle CDC Client origin, you specify the tables with the change capture data that you want to process.
A table configuration defines a group of tables with the same table name pattern, that are from one or more schemas with the same name pattern.
You can define one or more table configurations.
Schema, Table Name, and Exclusion Patterns
To specify the tables, you define the schema, a table name pattern, and an optional table exclusion pattern.
When defining the schema and table name pattern, you can use LIKE syntax to define a set of tables within a schema or across multiple schemas. For more information about valid patterns for the LIKE syntax, see the Oracle documentation.
When needed, you can also use a regular expression as an exclusion pattern to exclude a subset of tables from the larger set.
SALES while excluding those that end with a dash
(-) and single-character suffix. You can use the following configuration to specify the
tables to process: - Schema:
sales - Table Name Pattern:
SALES% - Exclusion Pattern:
SALES.*-.
Initial Change
The initial change is the point in the LogMiner redo logs where you want to start processing. When you start the pipeline for the first time, the origin starts processing from the specified initial change. The origin only uses the specified initial change again when you reset the origin.
Note that Oracle CDC Client processes only change capture data. If you need existing data, you might use a JDBC Query Consumer or a JDBC Multitable Consumer in a separate pipeline to read table data before you start an Oracle CDC Client pipeline.
- From the latest change
- The origin processes all changes that occur after you start the pipeline.
- From a specified datetime
- The origin processes all changes that occurred at the specified datetime and
later. Use the following format:
DD-MM-YYYY HH24:MI:SS. - From a specified system change number (SCN)
- The origin processes all changes that occurred in the specified SCN and later. When using the specified SCN, the origin starts processing with the timestamp associated with the SCN. If the SCN cannot be found in the redo logs, the origin continues reading from the next higher SCN that is available in the redo logs.
Example
You want to process all existing data in the Orders table and then capture changed data, writing all data to Amazon S3. To read the existing data, you use a pipeline with the JDBC Query Consumer and Amazon S3 destination as follows:
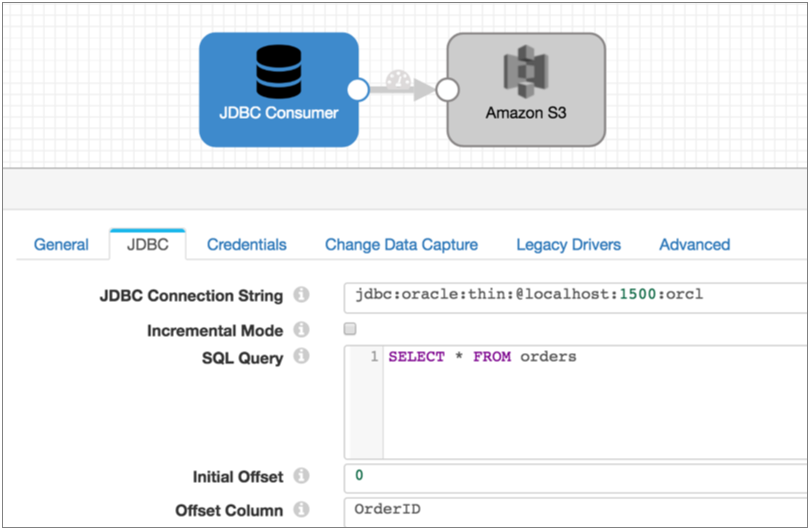
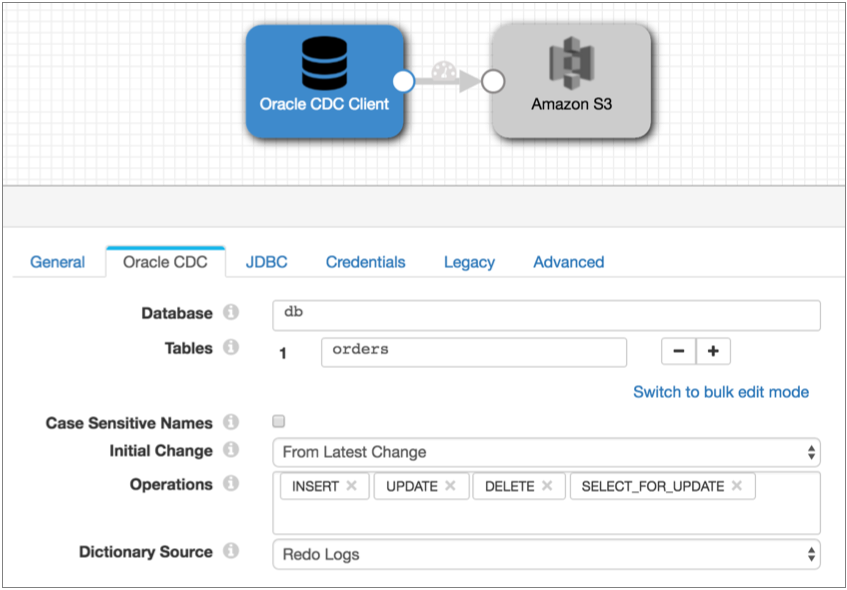
Once all existing data is read, you stop the JDBC Query Consumer pipeline and start the following Oracle CDC Client pipeline. This pipeline is configured to pick up changes that occur after you start the pipeline, but if you wanted to prevent any chance of data loss, you could configure the initial change for an exact datetime or earlier SCN:
Choosing Buffers
When processing data, the Oracle CDC Client can buffer data locally on the Data Collector machine or use Oracle LogMiner buffers:
- Local buffers
-
When using local buffers, the origin requests the transactions for the relevant tables and time period. The origin buffers the resulting LogMiner redo SQL statements until it verifies a commit for a transaction. After seeing a commit, it parses and processes the committed data.
The origin can buffer the redo SQL statements completely in memory or write them primarily to disk while using a small amount of memory for tracking.
By default, the origin uses local buffers. In general, using local buffers should provide better performance than Oracle LogMiner buffers.
Use local buffers to process large transactions or to avoid monopolizing the Oracle PGA. Buffer information in memory for better performance when Data Collector resources allow. Buffer information to disk to avoid monopolizing Data Collector resources.
- Oracle LogMiner buffers
- When using Oracle LogMiner buffers, the origin requests data from Oracle LogMiner for a particular time period. LogMiner then buffers all transactions for that time period for all tables in the database, rather than only the tables needed by the origin.
Local Buffer Resource Requirements
Before using local buffers, you should verify that the allocated resources are sufficient for the needs of the pipeline.
- In memory
- When buffering in memory, the origin buffers the LogMiner redo SQL statements returned by Oracle. It processes the data after receiving a commit for the statement.
- To disk
- When buffering to disk, the origin stores only the statement ID for each SQL
query in memory. Then it saves the queries to disk.
By default the origin buffers data to the directory specified by the system property,
java.io.tmpdir. You can configure the origin to buffer data to an existing directory on the Data Collector machine. The user who starts the pipeline must have read and write access to the directory.
For information about configuring the Data Collector heap size, see Java Heap Size in the Data Collector documentation.
Uncommitted Transaction Handling
You can configure how the Oracle CDC Client origin handles old uncommitted transactions when the origin uses local buffers.
When using local buffers, the Oracle CDC Client origin clears the buffers of old uncommitted transactions after each LogMiner session. Old uncommitted transactions are those that are older than the time specified for the Maximum Transaction Length property.
By default, the origin generates error records for the old uncommitted transactions. The origin converts each LogMiner redo SQL statement to a record and passes the record to the stage for error handling.
If you don't need error records for old uncommitted transactions, you can configure the origin to discard uncommitted transactions. This also reduces the overhead used to generate the error records.
For example, say the Maximum Transaction Length and the LogMiner Session Window properties are both set to one hour, and a transaction arrives in the last ten minutes of a LogMiner session. If the transaction remains uncommitted when the LogMiner session closes and the next session begins, the Oracle CDC origin retains the transaction for the next session. This is because the transaction is only ten minutes old and the maximum transaction length is an hour.
Now say the transaction is still uncommitted an hour later, when the next LogMiner session closes. Then, the transaction is considered an old uncommitted transaction because it is older than the maximum transaction length. By default, the origin generates an error record for the transaction. However, if you configure the origin to discard old uncommitted transactions, the origin simply discards the transaction instead.
To discard old uncommitted transactions, select the Discard Old Uncommitted Transactions property. This property is only available when you buffer changes locally.
JDBC Fetch Options
- JDBC Fetch Size for Current Window - Maximum number of rows to fetch and process together from an executed statement when the LogMiner session includes the current time.
- JDBC Fetch Size for Past Windows - Maximum number of rows to fetch and process together from an executed statement when the LogMiner session is entirely in the past.
CONTINUOUS_MINE option is enabled for LogMiner:- CONTINUOUS_MINE enabled
- When LogMiner has
CONTINUOUS_MINEenabled, set both fetch size properties to as small a value as possible. - CONTINUOUS_MINE disabled
- When LogMiner has
CONTINUOUS_MINEdisabled, set both fetch size properties to as large a value as your execution environment allows. For example, you might typically set both properties to between 10,000 - 20,000 or higher.
Include Nulls
When the Oracle LogMiner performs full supplemental logging, the resulting data includes all columns in the table with null values where no changes occurred. When the Oracle CDC Client processes this data, by default, it ignores null values when generating records.
You can configure the origin to include the null values in the record. You might need to include the null values when the destination system has required fields. To include null values, enable the Include Nulls property on the Oracle CDC tab.
Unsupported Data Types
You can configure how the origin handles records that contain unsupported data types. The origin can perform the following actions:
- Pass the record to the pipeline without the unsupported data types.
- Pass the record to error without the unsupported data types.
- Discard the record.
You can configure the origin to include the unsupported data types in the record. When you include unsupported types, the origin includes the field names and passes the data as unparsed strings, when possible.
The following Oracle data types are not supported by the Oracle CDC Client origin:
- Array
- Datalink
- Distinct
- Interval
- Java Object
- Nclob
- Other
- Ref
- Ref Cursor
- SQLXML
- Struct
- Time with Timezone
Conditional Data Type Support
- You can configure advanced properties to enable the origin to process Oracle Blob and Clob data. The origin converts Blob data to the Data Collector Byte Array data type, and Clob data to the Data Collector String data type.
- The origin treats Oracle Raw data as a Data Collector Byte Array data type.
- The origin converts Oracle Timestamp with Timezone data to the Data Collector Zoned Datetime data type. To maximize efficiency while providing more precision, the origin includes only the UTC offset with the data. It omits the time zone ID.
Processing Blob and Clob Columns
Though the Oracle CDC Client origin does not process Blob or Clob columns by default, you can configure the origin to process Blob and Clob columns when it buffers changes locally. You can also specify a limit to the size of the resulting Blob and Clob fields.
When processing Blob or Clob data, the origin treats Oracle operations on Blob or Clob columns as an update record. For example, when Clob data is trimmed in Oracle, the Oracle CDC Client origin generates a corresponding update record for the change.
The origin generates update records when the following Oracle operations are performed on Blob or Clob columns:
- LOB_WRITE
- LOB_ERASE
- LOB_TRIM
oracle.cdc.operation.lobColumnName- Name of the updated Blob or Clob field.oracle.cdc.operation.lobOperationName- Operation performed on the Blob or Clob field. Appears only when the field has been erased or trimmed. Possible values areERASEorTRIM.oracle.cdc.operation.lobLength- Contains different information depending on the operation performed:- When new data is written or trimmed, contains the new length of the Blob or Clob data.
- When data is erased, contains the length of the segment of the Blob or Clob data that was erased.
The length is in bytes for Blob fields and characters for Clob fields.
oracle.cdc.operation.lobOffset- Offset of the data that was erased, in bytes for Blob fields and characters for Clob fields. Appears only when the field has been erased.
ClobData and the original data,
abcdefg, has cde erased, leaving an updated value
of abfg. Then, the Oracle CDC Client origin generates an update record
and includes the following details in record header attributes:oracle.cdc.operation.lobColumnNameset toClobDataoracle.cdc.operation.lobOperationNameset toERASEoracle.cdc.operation.lobLengthset to 3oracle.cdc.operation.lobOffsetset to 2
To enable the origin to process Blob or Clob data, on the Advanced tab, click the Enable Blob and Clob Column Processing property.
To set a limit on the resulting field size, specify the maximum number of bytes and characters to use in the Maximum Lob Size property.
Parse SQL, Supported Operations, and Generated Records
The Oracle CDC Client origin generates records for the operation types that you specify. However, the origin reads all operation types from redo logs to ensure proper transaction handling.
Generated records contain fields in the same order as the corresponding columns in the database tables. The information included in generated records differs depending on whether the origin is configured to parse redo log SQL statements:
- Parsing SQL statements
- When the origin parses redo SQL statements, you can
configure it to create records for the following operations:
- INSERT
- DELETE
- UPDATE
- Not parsing SQL statements
- When the origin does not parse redo SQL statements, it
writes each LogMiner SQL statement to a field named
sql. The origin also generates field attributes that provide additional information about this field.
CRUD Operation Header Attributes
- sdc.operation.type
- The origin evaluates the Oplog operation type associated
with each entry that it processes. When appropriate, it writes the
operation type to the
sdc.operation.typerecord header attribute. - oracle.cdc.operation
- The origin also writes the CRUD operation type to an
oracle.cdc.operationattribute. This attribute was implemented in an earlier release and is supported for backward compatibility.
CDC Header Attributes
oracle.cdc.sequence.oracle- Includes sequence numbers that indicate the order in which statements were processed within the transaction. The sequence number is generated by Oracle. Use to keep statements in order within a single transaction.Note: When the origin uses local buffering, Oracle provides the default value of1for all records, so should not be used to order statements. Use theoracle.cdc.sequence.internalattribute when using local buffering.oracle.cdc.sequence.internal- Includes sequence numbers equivalent to those in the attribute above, but created by the origin. The sequence starts with 0 each time the pipeline starts.Like the attribute above, you can use these values to keep statements in order within a single transaction.
Best practice is to use this attribute only when using local buffering, when the
oracle.cdc.sequence.oracleattribute does not provide the expected data.
SQL Query Header Attributes
oracle.cdc.operationoracle.cdc.precisionTimestamp- Timestamp, to the nanosecond, when the database change occurred.Used when the database provides the timestamp in nanoseconds.
oracle.cdc.queryoracle.cdc.redoValueoracle.cdc.rowIdoracle.cdc.scnoracle.cdc.tableoracle.cdc.timestamp- Timestamp, to the second, when the change occurred.Used when the database provides the timestamp in seconds.
oracle.cdc.undoValueoracle.cdc.user
Blob and Clob Header Attributes
oracle.cdc.operation.lobColumnName- Name of the updated Blob or Clob field.oracle.cdc.operation.lobOperationName- Operation performed on the Blob or Clob field. Appears only when the field has been erased or trimmed. Possible values areERASEorTRIM.oracle.cdc.operation.lobLength- Contains different information depending on the operation performed:- When new data is written or trimmed, contains the new length of the Blob or Clob data.
- When data is erased, contains the length of the segment of the Blob or Clob data that was erased.
The length is in bytes for Blob fields and characters for Clob fields.
oracle.cdc.operation.lobOffset- Offset of the data that was erased, in bytes for Blob fields and characters for Clob fields. Appears only when the field has been erased.
Other Header Attributes
- Primary keys
-
When a table contains a primary key, the origin includes the following record header attribute:
jdbc.primaryKeySpecification- Provides a JSON-formatted string that lists the columns that form the primary key in the table and the metadata for those columns.For example, a table with a composite primary key contains the following attribute:jdbc.primaryKeySpecification = {{"<primary key column 1 name>": {"type": <type>, "datatype": "<data type>", "size": <size>, "precision": <precision>, "scale": <scale>, "signed": <Boolean>, "currency": <Boolean> }}, ..., {"<primary key column N name>": {"type": <type>, "datatype": "<data type>", "size": <size>, "precision": <precision>, "scale": <scale>, "signed": <Boolean>, "currency": <Boolean> } } }A table without a primary key contains the attribute with an empty value:jdbc.primaryKeySpecification = {}
For an update operation on a table with a primary key, the origin includes the following record header attributes:jdbc.primaryKey.before.<primary key column name>- Provides the old value for the specified primary key column.jdbc.primaryKey.after.<primary key column name>- Provides the new value for the specified primary key column.
Note: The origin provides the new and old values of the primary key columns regardless of whether the value changes. - Decimal fields
- When a record includes decimal fields, the origin includes the
following record header attributes for each decimal field in the record:
jdbc.<fieldname>.precisionjdbc.<fieldname>.scale
You can use the record:attribute or
record:attributeOrDefault functions to access the information
in the attributes. For more information about working with record header attributes,
see Working with Header Attributes.
Field Attributes
The Oracle CDC Client origin generates field attributes for columns converted to the Decimal or Datetime data types in Data Collector. The attributes provide additional information about each field.
- The Oracle Number data type is converted to the Data Collector Decimal data type, which does not store scale and precision.
- The Oracle Timestamp data type is converted to the Data Collector Datetime data type, which does not store nanoseconds.
| Data Collector Data Type | Generated Field Attribute | Description |
|---|---|---|
| Decimal | precision | Provides the original precision for every number column. |
| Decimal | scale | Provides the original scale for every number column. |
| Datetime | nanoSeconds | Provides the original nanoseconds for every timestamp column. |
You can use the record:fieldAttribute or
record:fieldAttributeOrDefault functions to access the information
in the attributes. For more information about working with field attributes, see Field Attributes.
Database Time Zone
- Same as Data Collector - Select when the database operates in the same time zone as Data Collector.
- Specific time zone - Select when the database operates in a different time zone from Data Collector.
The property must be set correctly to ensure that the appropriate changes are processed.
Change in Daylight Saving Time
A database time zone can be affected by a change in daylight saving time, based on whether the database uses an offset or a named time zone. An offset time zone is defined with a numeric value, such as -08:00, and is not affected by a change in daylight saving time. A named time zone is defined with a name, such as Brazil, America/Vancouver, or CET. Some named time zones are affected by a change in daylight saving time.
If the database operates in a time zone that is affected by daylight saving time, then the pipeline pauses processing during the time change window to ensure that all data is correctly processed. Pipelines can pause from 1.5 to 2.5 hours during the time change, depending on whether the daylight saving time change is forward or backward. After the time change completes, the pipeline resumes processing at the last-saved offset.
During the time change window, the pipeline state remains running, but the internal mining state of the pipeline is paused.
- Active - Pipeline is running and actively processing changes.
- Paused - Pipeline is running but paused during a time change window. The state lists the remaining paused time.
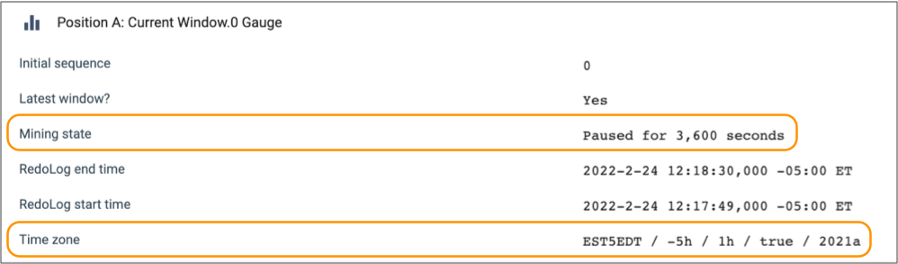
As you monitor a running Oracle CDC Client pipeline, you can also view the configured database time zone, and whether the time zone is affected by daylight saving time, as indicated by true or false. For example, the following stage statistics indicate that the pipeline has a Paused mining state, the remaining paused time is 3,600 seconds or one hour, and the origin is using the Eastern Standard Time (EST) time zone which does use daylight saving time:
Event Generation
The Oracle CDC Client origin can generate events that you can use in an event stream when the origin uses redo logs as the dictionary source. The origin does not generate events when using the online catalog as the dictionary source.
When you use redo logs as the dictionary source and enable event generation, the Oracle CDC Client generates events when it reads DDL statements. It generates events for ALTER, CREATE, DROP, and TRUNCATE statements.
When you start the pipeline, the origin queries the database and caches the schemas for all tables listed in the origin, and then generates an initial event record for each table. Each event record describes the current schema for each table. The origin uses the cached schemas to generate records when processing data-related redo log entries.
The origin then generates an event record for each DDL statement it encounters in the redo logs. Each event record includes the DDL statement and the related table in record header attributes.
The origin includes table schema information in the event record for new and updated tables. When the origin encounters an ALTER or CREATE statement, it queries the database for the latest schema for the table.
If the ALTER statement is an update to a cached schema, the origin updates the cache and includes the updated table schema in the event record. If the ALTER statement is older than the cached schema, the origin does not include the table schema in the event record. Similarly, if the CREATE statement is for a "new" table, the origin caches the new table and includes the table schema in the event record. Because the origin verifies that all specified tables exist when the pipeline starts, this can occur only when the table is dropped and created after the pipeline starts. If the CREATE statement is for a table that is already cached, the origin does not include the table schema in the event record.
- With the Email executor to send a custom email
after receiving an event.
For an example, see Sending Email During Pipeline Processing.
- With a destination to store event information.
For an example, see Preserving an Audit Trail of Events.
For more information about dataflow triggers and the event framework, see Dataflow Triggers Overview.
Event Records
| Record Header Attribute | Description |
|---|---|
| sdc.event.type | Event type. Uses one of the following types:
|
| sdc.event.version | Integer that indicates the version of the event record type. |
| sdc.event.creation_timestamp | Epoch timestamp when the stage created the event. |
| oracle.cdc.table | Name of the Oracle database table that changed. |
| oracle.cdc.ddl | The DDL statement that triggered the event. |
DROP and TRUNCATE event records include just the record header attributes listed above.
CREATE event records include the schema for the new table when the table has been dropped and recreated. ALTER event records include the table schema when the statement updates a cached schema. For more information about the behavior for CREATE and ALTER statements, see Event Generation.
For example, the following ALTER event record displays the three fields in an updated schema - NICK, ID, and NAME:
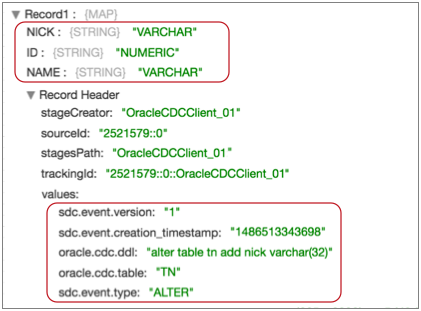
In the list of record header attributes, notice the DDL statement that added the NICK field, the name of the updated table, and the ALTER event type.
Multithreaded Parsing
When you configure the origin to use local buffering and to parse the SQL query, you can configure the Oracle CDC Client origin to use multiple threads to parse transactions. You can use multithreaded parsing with both the default Oracle CDC Client parser and the alternate PEG parser.
When performing multithreaded parsing, the origin uses multiple threads to generate records from committed SQL statements in a transaction. It does not perform multithreaded processing of the resulting records.
The Oracle CDC Client origin uses multiple threads for parsing based on the Parse Thread Pool Size property. When you start the pipeline, the origin creates the number of threads specified in the property. The origin connects to Oracle, creates a LogMiner session, and processes
When the origin processes a transaction, it reads and buffers all SQL statements in the transaction to an in-memory queue and waits for statements to be committed before processing them. Once committed, the SQL statements are parsed using all available threads and the original order of the SQL statements is retained.
The resulting records are passed to the rest of the pipeline. Note that enabling multithreaded parsing does not enable multithreaded processing – the pipeline uses a single thread for reading data.
Working with the SQL Parser Processor
For very wide tables, those with hundreds of columns, reading the redo logs and parsing the SQL query using the Oracle CDC Client origin may take longer than expected and can cause the Oracle redo logs to be rotated out before they are read. When this happens, data is lost.
To avoid this, you can use multiple pipelines and the SQL Parser processor. The first pipeline contains the Oracle CDC Client and an intermediate endpoint. Configure the origin to not parse the SQL query. The second pipeline passes records from the intermediate endpoint to the SQL Parser processor to both parse the SQL query and to update the fields. Using this approach, the origin can read the redo logs without waiting for the SQL Parser to finish and therefore no data is lost.
- Reads the change data logs.
- Generates records that contain only the SQL query.
- Generates events.
- Parses the SQL query.
- Generates CDC and CRUD record header attributes.
For more information about the SQL Parser processor, see SQL Parser.
Working with the Drift Synchronization Solution
If you use the Oracle CDC Client origin as part of a Drift Synchronization Solution for Hive pipeline, make sure to pass only records flagged for Insert to the Hive Metadata processor.
- Configure the Oracle CDC Client to process only Insert records.
- If you want to process additional record types in the pipeline, use a Stream Selector to route only Insert records to the Hive Metadata processor.
Data Preview with Oracle CDC Client
You might need to increase the Preview Timeout data preview property.
Due to the complex nature of the Oracle CDC Client origin, initiating preview can take longer than expected. If preview times out, try increasing the Preview Timeout property incrementally to allow the origin time to connect.
- To generate more than one preview record, set the Max Batch Wait Time property for the origin to a value greater than 0.
Configuring an Oracle CDC Client Origin
Configure an Oracle CDC Client origin to process LogMiner change data capture information from an Oracle database.
Before you use the origin, complete the prerequisite tasks. For more information, see Oracle CDC Client Prerequisites.
-
In the Properties panel, on the General tab, configure
the following properties:
General Property Description Name Stage name. Description Optional description. Produce Events When the origin uses redo logs as the dictionary source, can generate event records when the origin reads DDL statements. Use for event handling. On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
Note: The origin does not apply this error record handling to the following error codes:-
JDBC_85- The record has fields with unsupported field types. Configure the Unsupported Field Types property to determine how the origin handles these records. -
ORACLE_CDC_CLIENT_LOG_MINER_18- The transaction started before the set of transactions being considered. To discard these records, enable the Discard Old Uncommittted Transactions property.
-
On the Oracle CDC tab, configure the following change data
capture properties:
Oracle CDC Property Description Tables Tables to track. Specify related properties as needed. Using simple or bulk edit mode, click the Add icon to define another table configuration.
Schema Name Schema to use. You can enter a schema name or use LIKE syntax to specify a set of schemas. The origin submits the schema name in all caps by default. To use a lower or mixed-case name, select the Case-Sensitive Names property.
Table Name Pattern Table name pattern that specifies the tables to track. You can enter a table name or use LIKE syntax to specify a set of tables. The origin submits table names in all caps by default. To use lower or mixed-case names, select the Case-Sensitive Names property. Exclusion Pattern Optional table exclusion pattern to define a subset of tables to exclude. You can enter a table name or use a regular expression to specify a subset of tables to exclude. To view and configure this option, click Show Advanced Options.
Case-Sensitive Names Submits case-sensitive schema, table, and column names. When not selected, the origin submits names in all caps. Oracle uses all caps for schema, table, and column names by default. Names can be lower- or mixed-case only if the schema, table, or column was created with quotation marks around the name.
Initial Change Starting point for the read. When you start the pipeline for the first time, the origin starts processing from the specified initial change. The origin only uses the specified initial change again when you reset the origin. Use one of the following options:
- From Latest Change - Processes changes that arrive after you start the pipeline.
- From Date - Processes changes starting from the
specified date. Note: The DB Time Zone property must be set correctly to ensure that the appropriate changes are processed.
- From SCN - Processes changes starting from the specified system change number (SCN).
Start Date Datetime to read from when you start the pipeline. For a date-based initial change. Use the following format:
DD-MM-YYYY HH24:MI:SS.Start SCN System change number to start reading from when you start the pipeline. If the SCN cannot be found in the redo logs, the origin continues reading from the next higher SCN that is available in the redo logs. For an SCN-based initial change.
Operations Operations to include when creating records. All unlisted operations are ignored. Operations are supported based on whether the Parse SQL Query property is selected. For more information, see Parse SQL, Supported Operations, and Generated Records.
Dictionary Source Location of the LogMiner dictionary: - Redo logs - Use when schemas can change. Allows the origin to adapt to schema changes and to generate events for DDL statements.
- Online catalog - Use for better performance when schemas are not expected to change.
Buffer Changes Locally Determines the buffers that the origin uses. Select to use local Data Collector buffers. Clear to use Oracle LogMiner buffers. Generally, using local buffers will enhance pipeline performance. By default, the origin uses local buffers.
Buffer Location Location of local buffers: - In Memory
- On Disk
Before running the pipeline, note the local buffer resource requirements. For more information, see Local Buffer Resource Requirements.
Available when using local buffers.
Buffer Directory Directory where origin buffers data. Specify an existing directory on the Data Collector. The user who starts the pipeline must have read and write access to the directory. If you do not specify a directory, the origin uses the directory specified in the system property,
java.io.tmpdir.Available when buffer location is on disk.
Discard Old Uncommitted Transactions Discards old uncommitted transactions at the end of a LogMiner session instead of processing them into error records. Old uncommitted transactions are those that are older than the time specified for the Maximum Transaction Length property.
Available when using local buffers.
Unsupported Field Type Action taken when the origin encounters unsupported data types in the record: - Ignore and Send Record to Pipeline - The origin ignores unsupported data types and passes the record with only supported data types to the pipeline.
- Send Record to Error - The origin handles the record based on the error record handling configured for the stage. The error record contains only the supported data types.
- Discard Record - The origin discards the record.
For a list of unsupported data types, see Unsupported Data Types.
Add Unsupported Fields to Records Includes fields with unsupported data types in the record. Includes the field names and the unparsed string values of the unsupported fields, when possible. Include Nulls Includes null values in records generated from full supplemental logging that include null values. By default, the origin generates a record without null values. Convert Timestamp To String Enables the origin to write timestamps as string values rather than datetime values. Strings maintain the precision stored in the source system. For example, strings can maintain the precision of a high-precision Timestamp(6) field. When writing timestamps to Data Collector date or time data types that do not store nanoseconds, the origin stores any nanoseconds from the timestamp in a field attribute.
Maximum Transaction Length Time in seconds to wait for changes for a transaction. Enter the longest period of time that you expect a transaction to require. Transactions older than the specified time are treated as old uncommitted transactions each time a LogMiner session closes.
Default is
${ 1 * HOURS }which is 3600 seconds.Used for local buffers only.
LogMiner Session Window Time in seconds to keep a LogMiner session open. Set to larger than the maximum transaction length. Reduce when not using local buffering to reduce LogMiner resource use. Default is
${ 2 * HOURS }which is 7200 seconds.Parse SQL Query Parses SQL queries to generate records. If set to false, the origin writes the SQL query to a
sqlfield that can be parsed later by the SQL Parser processor.For more information, see Parse SQL, Supported Operations, and Generated Records.
By default, the origin parses the SQL queries.
Send Redo Query in Headers Includes the LogMiner redo query in the oracle.cdc.queryrecord header attribute.DB Time Zone Time zone of the database: - Same as Data Collector - Select when the database operates in the same time zone as Data Collector.
- Specific time zone - Select when the database operates in a different time zone from Data Collector.
The property must be set correctly to ensure that the appropriate changes are processed.
-
On the JDBC tab, configure the following JDBC
properties:
JDBC Property Description Connection Connection that defines the information required to connect to an external system. To connect to an external system, you can select a connection that contains the details, or you can directly enter the details in the pipeline. When you select a connection, Control Hub hides other properties so that you cannot directly enter connection details in the pipeline.
JDBC Connection String Connection string used to connect to the database. Note: If you include the JDBC credentials in the connection string, use the user account created for the origin. Common user accounts for Oracle and Oracle RAC 12c, 18c, 19c, and 21c CDB databases start withc##. For more information, see Task 3. Create a User Account.Max Batch Size (records) Maximum number of records processed at one time. Honors values up to the Data Collector maximum batch size. Default is 1000. The Data Collector default is 1000.
Batch Wait Time (secs) Number of seconds to wait before sending a partial or empty batch. PDB Name of the pluggable database that contains the schema you want to use. Use only when the schema was created in a pluggable database. Required for schemas created in pluggable databases.
Use Credentials Enables entering credentials. Use when you do not include credentials in the JDBC connection string. Additional JDBC Configuration Properties Additional JDBC configuration properties to use. To add properties, click Add and define the JDBC property name and value. Use the property names and values as expected by JDBC.
LogMiner Query Timeout (seconds) Maximum number of seconds that the origin waits for a LogMiner query to complete. Use 0 for no limit.
-
To enter JDBC credentials separately from the JDBC connection string, on the
Credentials tab, configure the following
properties:
Credentials Property Description Username User name for the JDBC connection. The user account must have the correct permissions or privileges in the database. Use the user account created for the origin. Common user accounts for Oracle and Oracle RAC 12c, 18c, 19c, and 21c CDB databases start with
c##.For more information, see Task 3. Create a User Account.
Password Password for the account. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores. For more information about credential stores, see Credential Stores in the Data Collector documentation. -
When using JDBC versions older than 4.0, on the Legacy
Drivers tab, optionally configure the following
properties:
Legacy Drivers Property Description JDBC Class Driver Name Class name for the JDBC driver. Required for JDBC versions older than version 4.0. Connection Health Test Query Optional query to test the health of a connection. Recommended only when the JDBC version is older than 4.0. -
On the Advanced tab, optionally configure advanced
properties.
The defaults for these properties should work in most cases:
Advanced Property Description JDBC Fetch Size for Current Window Maximum number of rows to fetch and process together from an executed statement when the LogMiner session includes the current time. Configure this property based on whether the
CONTINUOUS_MINEoption is enabled for LogMiner.Default is 1.
JDBC Fetch Size for Past Windows Maximum number of rows to fetch and process together from an executed statement when the LogMiner session is entirely in the past. Configure this property based on whether the
CONTINUOUS_MINEoption is enabled for LogMiner.Default is 1.
Time between Session Windows (ms) Milliseconds to wait after a LogMiner session has been completely processed, ensuring a minimum size for LogMiner session windows. Default is 5000.
Time after Session Window Start (ms) Milliseconds to wait after a LogMiner session window starts, allowing Oracle to finish setting up before processing begins. Default is 5000.
Minimum Lag from Database Time (sec) Minimum number of seconds between the time an operation occurs and the database time, before the origin processes the operation.
Default is ${1 * SECONDS}.
Use PEG Parser Enables use of the PEG parser instead of the default ALL(*) parser. Can typically improve performance. Parse Thread Pool Size Number of threads that the origin uses for multithreaded parsing. Available only when performing local buffering and parsing the SQL query. Can be used with both the default parser and PEG parser.
Disable Continuous Mine Disables the LogMiner CONTINUOUS_MINEoption. TheCONTINUOUS_MINEoption is available in Oracle and Oracle RAC 18c and earlier.Enable BLOB and CLOB Column Processing When the origin buffers changes locally, enables processing data in Blob and Clob columns. Tip: Be sure to specify a size limit or ensure that Data Collector has enough memory to process large Blob and Clob values before enabling Blob and Clob processing.Maximum LOB Size Maximum size for each Blob or Clob field. Allows up to the specified number of bytes for Blob fields and characters for Clob fields. Data over the specified size is replaced by a null value.
Scan Unsupported Operations Returns an Unsupportederror message when LogMiner encounters an unsupported operation. When this property is disabled, unsupported operations are ignored without raising an error.Default is disabled.
Maximum Pool Size Maximum number of connections to create. Default is 1. The recommended value is 1.
Minimum Idle Connections Minimum number of connections to create and maintain. To define a fixed connection pool, set to the same value as Maximum Pool Size. Default is 1.
Connection Timeout (seconds) Maximum time to wait for a connection. Use a time constant in an expression to define the time increment. Default is 30 seconds, defined as follows:${30 * SECONDS}Idle Timeout (seconds) Maximum time to allow a connection to idle. Use a time constant in an expression to define the time increment. Use 0 to avoid removing any idle connections.
When the entered value is close to or more than the maximum lifetime for a connection, Data Collector ignores the idle timeout.
Default is 10 minutes, defined as follows:${10 * MINUTES}Max Connection Lifetime (seconds) Maximum lifetime for a connection. Use a time constant in an expression to define the time increment. Use 0 to set no maximum lifetime.
When a maximum lifetime is set, the minimum valid value is 30 minutes.
Default is 30 minutes, defined as follows:${30 * MINUTES}Enforce Read-only Connection Creates read-only connections to avoid any type of write. Default is enabled. Disabling this property is not recommended.
Transaction Isolation Transaction isolation level used to connect to the database. Default is the default transaction isolation level set for the database. You can override the database default by setting the level to any of the following:
- Read committed
- Read uncommitted
- Repeatable read
- Serializable