Slowly Changing Dimension
The Slowly Changing Dimension processor generates updates to a Type 1 or Type 2 slowly changing dimension by evaluating change data against existing dimension data. Use the processor in a pipeline to update slowly changing dimension data stored in a Snowflake table.
When you configure a Slowly Changing Dimension processor, you specify the key columns used to match change and dimension data and the slowly changing dimension type. You can also specify the action to take when change rows have columns that are not included in the dimension table.
When working with a Type 2 dimension, you specify how the dimension tracks changes: active flag column, start and end timestamp columns, or version column. Then, you define the tracking columns to use. When using start and end timestamp columns, you can configure the processor to use a timestamp in the change rows instead of the processing time for start and end timestamps.
When you configure a slowly changing dimension pipeline, it's important to configure the origins and destinations appropriately. For more information, see Slowly Changing Dimension Pipeline.
Slowly Changing Dimension Pipeline
A slowly changing dimension pipeline compares change data against the data in a slowly changing dimension table, then writes the changes to the dimension, making all necessary updates to existing dimension data.
The simplest slowly changing dimension pipeline looks like this:
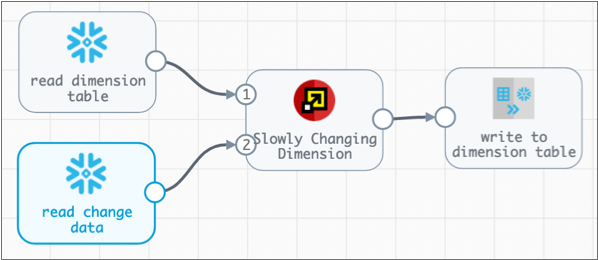
- Dimension origin - Reads data from the slowly changing dimension table. The data from this origin must flow into the first input for the Slowly Changing Dimension processor.
- Change origin - Reads data from a change data table. The data from this origin must flow into the second input for the Slowly Changing Dimension processor.
- Slowly Changing Dimension processor - Compares change data against master data. Flags change rows for insert or update. Adds tracking columns and performs other processing on change rows as needed.
- Dimension destination - Writes change data to the slowly changing dimension table. Updates existing dimension data as needed.
Data Processing
The Slowly Changing Dimension processor supports Type 1 and Type 2 slowly changing dimensions. The processor handles rows differently based on the selected slowly changing dimension type.
Type 1 Processing
A Type 1 slowly changing dimension keeps only the current dimension data. The dimension does not retain previous versions of the data.
When the values of specified key columns in a change row do not exist in the dimension table, the processor flags the change row for insert. When written to the dimension, the change row becomes a new row in the table.
When key column values in a change row match data in the dimension table, the processor flags the change row for update. When written to the dimension, the change row replaces the existing row.
For example, if the dimension table includes a row with a key column value of
005, then change row with a key column value of
005 replaces the existing row.
Type 2 Processing
As with Type 1 dimensions, when the key columns in a change row do not match data in the dimension table, the processor flags the change row for insert. When written to the dimension, the change row becomes a new row in the table.
When the key columns in a change row match data in the dimension table, the processor handles the row based on the specified tracking columns.
- Version column
- The dimension table includes a version column that you define in the processor. When key column values in a change row match data in the dimension table, the processor adds the version column to the change row and increments the existing version by one. No changes to existing dimension data are needed.
- Active flag column
- The dimension table includes an active flag column that you define in the
processor. You also specify the values used in the active column, such as
Y/N,true/false, or0/1. When needed, you can define custom values for the active flag column. - Timestamp columns
- The dimension table includes start and end timestamp columns that you define in the processor. A row is considered active when it does not include an end time.
Pipeline Configuration Guidelines
- Dimension and change data origins
- Configure the dimension origin and change data origin using the following
guidelines:
- Ensure that the change data origin passes rows in the appropriate
order. The Slowly Changing Dimension processor handles change data
in the order that it is received.
When necessary, you can use processors such as the Sort processor to order change data before passing it to the Slowly Changing Dimension processor.
- For Type 2 dimensions, ensure that the change data does not contain columns with the same names as the tracking columns specified in the processor.
- Typically, you do not enable the Cache Data property in the dimension or change data origin. This ensures that the
pipeline reads the latest updates in both the dimension table and
the change data table.
Similarly, avoid caching data in all processors that you add to the pipeline.
- Ensure that the change data origin passes rows in the appropriate
order. The Slowly Changing Dimension processor handles change data
in the order that it is received.
- Slowly Changing Dimension processor
- Configure the processor using the following guidelines:
-
- Link the dimension origin to the processor, then link the change
data origin. The first origin connects to the master data input, and
the second connects to the change data input. Important: The dimension origin must be connected to the master data input. If the origins are connected incorrectly, select the processor in the pipeline canvas. Then in the pop-up menu, select the Reorder icon:
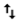 .
.For example, in the following pipeline, you can use the Reorder icon to correct the origin inputs:
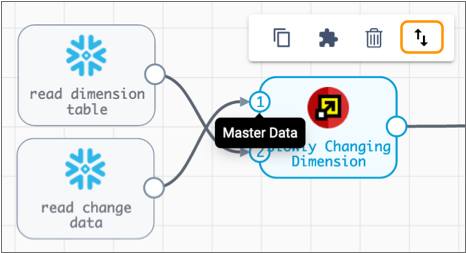
- On the Dimension tab, configure the SCD Type property.
- In the Key Columns property, list one or more
key columns to use when comparing change rows with master
rows.
For example, if the dimension uses a
storeIdcolumn as a primary key, add the column name to the Key Columns property. - For Type 2 dimensions, specify one or more of the following tracking columns: version, active flag, or timestamp.
- For the Behavior for New Columns property,
specify the action to take when change data includes additional
columns:
- Keep new columns - Adds new columns to the dimension table so data in new columns can be included in dimension data. Uses null values for rows and rows that do not include the new columns.
- Remove from change data - Removes columns from the change data that do not already exist in the dimension table.
- Link the dimension origin to the processor, then link the change
data origin. The first origin connects to the master data input, and
the second connects to the change data input.
- Dimension destination
- Configure the slowly changing dimension destination using the following
guidelines:
- Specify the name of the slowly changing dimension table.
- Set Write Mode to Propagate
updates from Slowly Changing Dimension
processor.Important: To process data correctly, the destination must be configured to use this write mode.
- Typically the dimension table already exists, but if it does not,
you can select Create Table to have the
destination create the table.
When enabled, the destination creates the table based on the structure of rows in the first batch of data.
- To allow the pipeline to add new columns to the dimension table,
select Data Drift Enabled. If you do not want
the table structure to change, disable the property.
If the Slowly Changing Dimension processor has the Behavior for New Columns property set to
Keep new columns, then enable data drift handling so the destination can add new columns to the dimension table.
Example
Say you want to update a Type 2 slowly changing dimension that uses start and end timestamp columns to indicate which rows are active.
Source Data
store dimension includes the following rows:| storeid | city | state | start_date | end_date |
|---|---|---|---|---|
| CA-0001 | San Francisco | CA | 1996-03-09 00:00:00.000 | null |
| CA-0002 | Los Angeles | CA | 2010-07-08 00:00:00.000 | null |
| MD-0001 | Rockville | MD | 2000-11-10 00:00:00.000 | null |
| MD-0001 | Bethesda | MD | 1995-01-01 00:00:00.000 | 2000-11-10 00:00:00.000 |
Null values in the end_date column indicate that the first three
rows are active stores. The end_date value for the last row
indicates that the store in Bethesda closed in 2000. The time portion of the
timestamps are set to 00:00:00.000 because the time was not
originally included in the data.
| storeid | city | state |
|---|---|---|
| CA-0001 | Colma | CA |
| MD-0001 | Germantown | MD |
| GA-0001 | Atlanta | GA |
This indicates that CA-0001 moved from San Francisco to Colma, MD-0001 moved from Rockville to Germantown, and a new store opened in Atlanta.
Pipeline Configuration
- Create an origin for the dimension data and an origin for the change data,
and disable caching for both origins.
Then, link both origins to the Slowly Changing Dimension processor, starting with the dimension origin so it connects to the master data input.
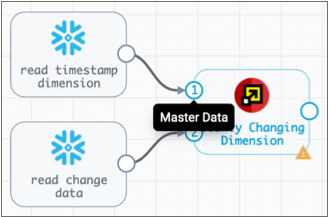 Important: The dimension origin must be connected to the master data input. If the origins are connected incorrectly, select the processor in the pipeline canvas. Then in the pop-up menu, select the Reorder icon:.
Important: The dimension origin must be connected to the master data input. If the origins are connected incorrectly, select the processor in the pipeline canvas. Then in the pop-up menu, select the Reorder icon:. - Configure the Slowly Changing Dimension processor to perform a Type 2
dimension update using the
start_dateandend_datetimestamp columns, as follows: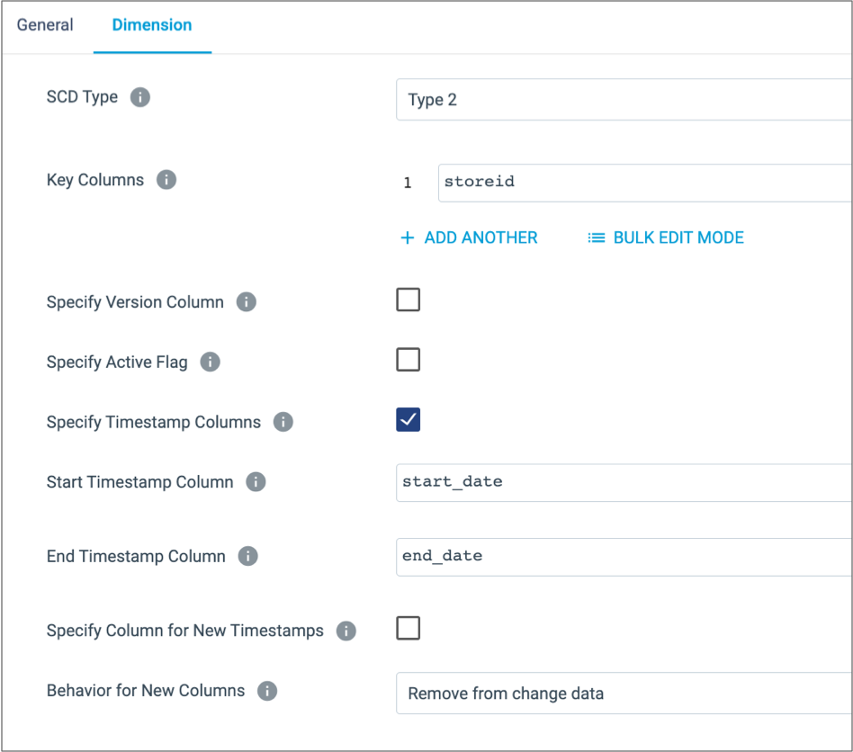
- Configure the destination to write to the dimension table and to use the Propagate updates from Slowly Changing Dimension processor write mode.
Pipeline Processing
When you run the
pipeline, the Slowly Changing Dimension processor compares the dimension data with
the change data. It adds the start_date and
end_date columns to the change data, and populates the
start_date column with the time of processing.
end_date columns for the closed San Francisco and
Rockville stores. The updated dimension table contains the following data:| storeid | city | state | start_date | end_date |
|---|---|---|---|---|
| CA-0001 | Colma | CA |
2022-12-16 15:03:28.527 |
null |
| GA-0001 | Atlanta | GA |
2022-12-16 15:03:28.527 |
null |
| MD-0001 | Germantown | MD |
2022-12-16 15:03:28.527 |
null |
| CA-0002 | Los Angeles | CA | 2010-07-08 00:00:00.000 | null |
| CA-0001 | San Francisco | CA | 1996-03-09 00:00:00.000 |
2022-12-16 15:03:28.527 |
| MD-0001 | Rockville | MD | 2000-11-10 00:00:00.000 |
2022-12-16 15:03:28.527 |
| MD-0001 | Bethesda | MD | 1995-01-01 00:00:00.000 | 2000-11-10 00:00:00.000 |
Configuring a Slowly Changing Dimension Processor
Configure a Slowly Changing Dimension processor as part of a slowly changing dimension pipeline that updates a Type 1 or Type 2 slowly changing dimension. Before you configure a slowly changing dimension pipeline, consider the processing that you want to achieve.
-
On the General tab, configure the following
properties:
General Property Description Name Stage name. Description Optional description. Cache Data Caches processed data. -
On the Dimension tab, configure the following
properties:
Dimension Property Description SCD Type Type of slowly changing dimension to work with: - Type 1 - The dimension contains only active rows.
- Type 2 - The dimension contains active rows and earlier versions of those rows for historical reference.
Key Columns One or more columns in change rows used to determine if a matching row exists in the dimension table. You can enter column names or select columns from preview data. Specify Version Column Enables specifying a version column. Version Column Name of the version column in the dimension data. You can enter the column name or select a column from preview data. Specify Active Flag Enables specifying an active flag column. Active Flag Column Name of the active flag column in the dimension data. You can enter the column name or select a column from preview data. Specify Timestamp Columns Enables specifying start and end timestamp columns. Start Timestamp Column Name of the start timestamp column in the dimension data. You can enter the column name or select a column from preview data. End Timestamp Column Name of the end timestamp column in the dimension data. You can enter the column name or select a column from preview data. Specify Column for New Timestamps Enables specifying a timestamp column in change data to use as the start and end timestamp values, instead of the pipeline processing time. The specified timestamp column is removed from the change data.
Calculated Timestamp Column Timestamp column in change data to use. This column is removed from change data after rows are evaluated. You can enter the column name or select a column from preview data. Behavior for New Columns Action to take when change data includes columns that do not exist in the dimension table: - Keep for newest rows and set to null for previous rows
- Remove from change data
Tip: When keeping new columns, enable data drift in the pipeline destination to allow it to update the dimension table.