Designing the Data Flow
You can branch and merge streams in a pipeline. When appropriate, you can also have multiple parallel streams.
Branching Streams
When you connect a stage to multiple stages, all data passes to all connected stages.
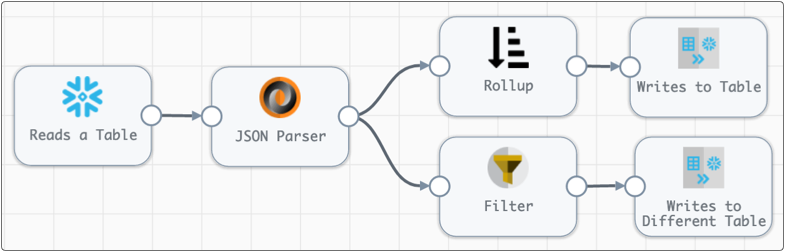
For example, in the following pipeline, all data read by the origin passes to the JSON Parser processor. Then the results of the parsing is passed to both branches, one performs a Snowflake group by rollup before writing to a target table, the other filters out data based on a condition before writing to a different table:
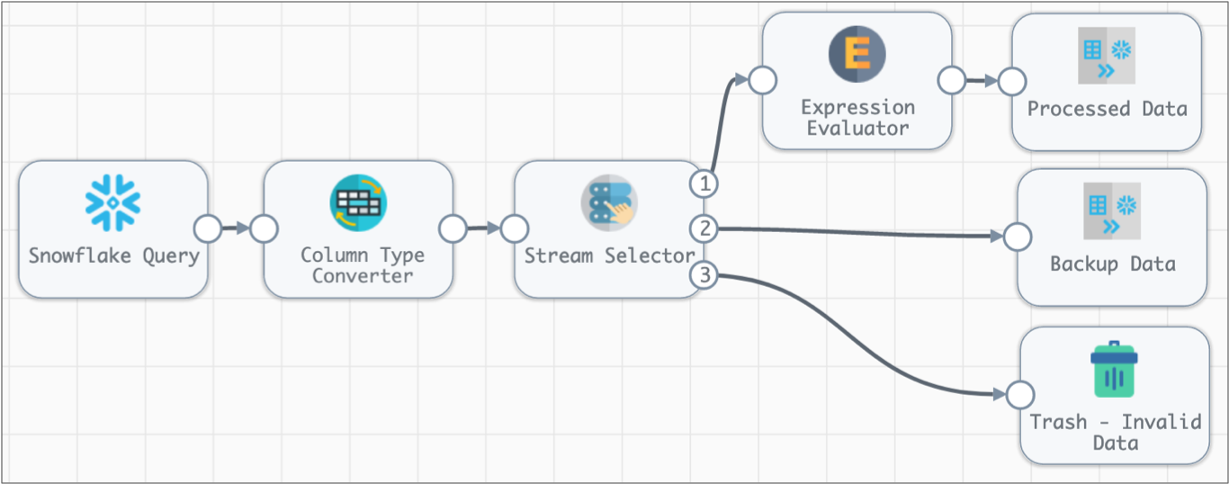
If you wanted to route data to different streams based on a condition, you can use the Stream Selector processor, as follows:
Merging Streams
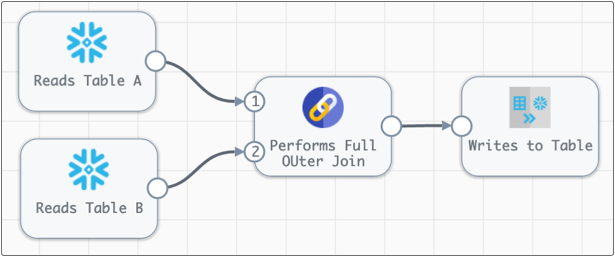
- Join processor - Joins data from two different tables based on the specified conditions and join types.
- Union processor - Merges data from multiple streams into a single stream based on the specified merge operation and column handling.
For example, the following pipeline uses a Join processor to perform a full outer join of the data from the two origins: