Validation
Control Hub performs two types of validation in the pipeline canvas:
- Implicit validation
- Implicit validation occurs by default as Control Hub saves your changes when you build pipelines and fragments. Implicit validation lists missing or incomplete configuration, such as an unconnected stage or a required property that has not been configured.
- Explicit validation
- Explicit validation occurs when you click the Validate icon, run a preview, or start a draft run of the pipeline. Explicit validation becomes available when implicit validation passes. You can use explicit validation when you build pipelines.
Spark for Transformer Validation
When you click the Validate icon to perform an explicit validation of a Transformer pipeline, you choose the Spark libraries used to validate the pipeline:
- Embedded Spark libraries
- When you validate using embedded Spark libraries, the pipeline is validated without communicating with the Spark installation on the local Transformer machine or on the cluster.
- Configured cluster manager
- When you validate using the configured cluster manager, the pipeline is validated using the Spark cluster configured for the pipeline.
In most cases, you'll want to validate a pipeline using the configured Spark cluster so that Transformer uses the same validation as when you start the pipeline.
Validating a Pipeline
Explicitly validate a pipeline to check all configured values for validity and to verify whether the pipeline can run as configured.
-
With a pipeline open in the canvas, click the Validate
icon:
 .
.
When validating a Transformer pipeline, choose the Spark libraries used to validate the pipeline.
If the validation fails, the canvas displays a link to the validation errors and displays error icons on the stages that encountered the errors, as follows:
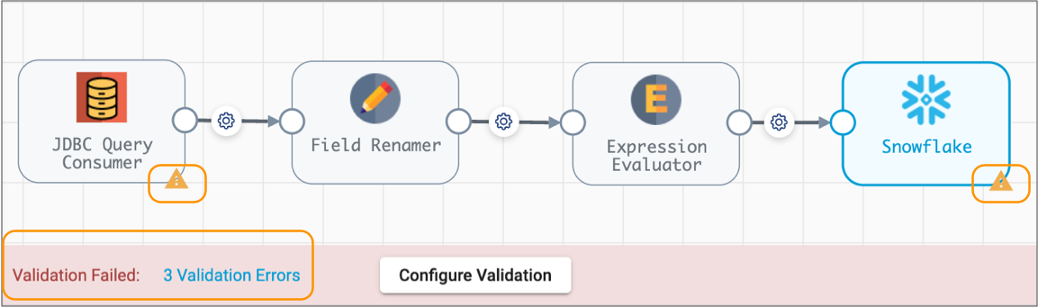
- Click the Validation Errors link to review all errors.
- Resolve each error, and then click the Validate icon again.
- If the validation fails due to a timeout error, click Configure Validation.
- In the Validation Configuration dialog box, increase the validation timeout value, and then click Validate.