Fragment Configuration
Like a pipeline, you can use any stage available in the authoring engine in the fragment -- from origins to processors, destinations, and executors.
You can configure runtime parameters in pipeline fragments to enable more flexible use of the fragment. You can also configure data rules and alerts, and data drift rules and alerts, to provide runtime notifications.
You can use data preview to help design and test the fragment, and use a test origin to provide data for data preview.
When the fragment is ready, publish the fragment using the Check In icon: ![]() . After you publish a fragment, you can use
the fragment in pipelines and use explicit validation in the pipeline to validate the
fragment.
. After you publish a fragment, you can use
the fragment in pipelines and use explicit validation in the pipeline to validate the
fragment.
Creating Pipeline Fragments
You can create a pipeline fragment based on a blank canvas or based on selected stages in a pipeline.
Using a Blank Canvas
Create a pipeline fragment from a blank canvas when you want to build the entire fragment from scratch.
To create a fragment from a blank canvas, click in the Navigation panel, and then click the Create New
Pipeline Fragment icon: ![]() .
.
Define the Pipeline Fragment
Define the fragment essentials, including the fragment name and the type of engine for the fragment.
-
Enter the following information to define the fragment:
Define Pipeline Fragment Property Description Name Name of the fragment. Use a brief name that informs your team of the fragment use case.
Description Optional description. Use the description to add additional details about the fragment use case.
Engine Type Type of engine for the fragment. Select the engine type to use for your fragment use case: - Data Collector - Runs streaming data pipelines that continuously read, process, and write data as soon as the data becomes available. Data Collector pipelines can read from and write to a large number of heterogeneous origins and destinations. The pipelines perform record-based data transformations.
- Transformer - Runs data processing pipelines run on Apache Spark. Because Transformer pipelines run on Spark deployed on a cluster, the pipelines can perform set-based transformations such as joins, aggregates, and sorts on the entire data set.
- Transformer for Snowflake - Generates SQL queries based on your pipeline configuration and passes the queries to Snowflake for execution. Snowflake pipelines read from and write to Snowflake tables using Snowpark DataFrame-based processing.
For more information, see Comparing IBM StreamSets Pipelines and "Comparing Snowflake and Other StreamSets Engines" in the Transformer for Snowflake documentation.
-
Click one of the following buttons:
- Cancel - Cancels creating the fragment and exits the wizard.
- Next - Saves the fragment definition and continues.
Configure the Pipeline Fragment
Transformer for Snowflake fragments do not require an authoring engine when your organization uses the hosted Transformer for Snowflake engine. When this is the case, the pipeline fragment wizard skips this step for Transformer for Snowflake fragments.
-
Select the authoring engine to use for pipeline fragment design.
The selected authoring engine determines the stages and functionality that display in the pipeline canvas.
By default, Control Hub selects an accessible authoring engine that you have read permission on and that has the most recent reported time. To select another engine, click Click here to select.
In the Select an Authoring Engine window, select an accessible engine, and then click Save to return to the pipeline fragment wizard.
An accessible engine is an engine that is running, that can communicate with Control Hub, and that can be reached by the web browser. For more information and tips on troubleshooting inaccessible engines, see Accessible Engines.
-
Click one of the following buttons:
- Back - Returns to the previous step in the wizard.
- Save & Next - Saves the fragment configuration and continues.
- Save & Open in Canvas - Saves the fragment and opens a blank canvas. You can share the fragment with others at a later time.
Share the Pipeline Fragment
By default, the pipeline fragment can only be seen by you. Share the fragment with other users and groups to grant them access to it.
- In the Select Users and Groups field, type a user email address or a group name.
-
Select users or groups from the list, and then click
Add.
The added users and groups display in the User / Group table.
-
Modify permissions as needed. By default, each added user or group is granted
both of the following permissions:
- Read - View the fragment configuration details and version history. Use the fragment in a pipeline. Export the fragment.
- Write - Design and publish the fragment. Create and remove tags for the pipeline. Delete fragment versions. Publish an updated version of the fragment.
For more information, see Pipeline Fragment Permissions.
-
Click one of the following buttons:
- Back - Returns to the previous step in the wizard.
- Save & Open in Canvas - Saves the fragment and opens a blank canvas.
- Save & Exit - Saves the fragment and exits the wizard, displaying the draft fragment in the Fragments view.
Using Pipeline Stages
Create a pipeline fragment from one or more pipeline stages when you want to reuse a portion of the logic from an existing pipeline.
Define the Pipeline Fragment
Define the fragment essentials, including the fragment name and an optional description.
-
Enter the following information to define the fragment:
Define Pipeline Fragment Property Description Name Name of the fragment. Use a brief name that informs your team of the fragment use case.
Description Optional description. Use the description to add additional details about the fragment use case.
Engine Type Type of engine for the fragment. Determined by the pipeline engine type. Cannot be edited.
Copied Stages Stages to include in the fragment. Determined by the stages selected in the pipeline canvas. Cannot be edited.
-
Click one of the following buttons:
- Cancel - Cancels creating the fragment and exits the wizard.
- Next - Saves the fragment definition and continues.
Configure the Pipeline Fragment
Transformer for Snowflake fragments do not require an authoring engine when your organization uses the hosted Transformer for Snowflake engine. When this is the case, the pipeline fragment wizard skips this step for Transformer for Snowflake fragments.
-
Select the authoring engine to use for pipeline fragment design.
The selected authoring engine determines the stages and functionality that display in the pipeline canvas.
By default, Control Hub selects an accessible authoring engine that you have read permission on and that has the most recent reported time. To select another engine, click Click here to select.
In the Select an Authoring Engine window, select an accessible engine, and then click Save to return to the pipeline fragment wizard.
An accessible engine is an engine that is running, that can communicate with Control Hub, and that can be reached by the web browser. For more information and tips on troubleshooting inaccessible engines, see Accessible Engines.
-
Click one of the following buttons:
- Back - Returns to the previous step in the wizard.
- Save & Next - Saves the fragment configuration and continues.
- Save & Open in Canvas - Saves the fragment as a draft and opens the fragment in the canvas. You can share the fragment with others at a later time.
Share the Pipeline Fragment
By default, the pipeline fragment can only be seen by you. Share the fragment with other users and groups to grant them access to it.
- In the Select Users and Groups field, type a user email address or a group name.
-
Select users or groups from the list, and then click
Add.
The added users and groups display in the User / Group table.
-
Modify permissions as needed. By default, each added user or group is granted
both of the following permissions:
- Read - View the fragment configuration details and version history. Use the fragment in a pipeline. Export the fragment.
- Write - Design and publish the fragment. Create and remove tags for the pipeline. Delete fragment versions. Publish an updated version of the fragment.
For more information, see Pipeline Fragment Permissions.
-
Click one of the following buttons:
- Back - Returns to the previous step in the wizard.
- Save & Open in Canvas - Saves the fragment as a draft and opens the fragment in the canvas.
- Save & Publish - Saves the fragment permissions and continues so that you can publish the fragment.
- Save & Exit - Saves the fragment as a draft and opens the original pipeline in the canvas.
Publish the Pipeline Fragment
Publish the fragment so that you can use the fragment in a pipeline.
You can publish the fragment only if it meets the validation requirements to be published.
-
In the Check In step, enter a commit message.
As a best practice, state what changed in this version so that you can track the commit history of the fragment.
-
Click one of the following buttons:
- Cancel - Cancels publishing the fragment.
- Publish and Next - Publishes the fragment and
continues with the sharing step. Share the fragment with other users and
groups, and then click Save & Exit to continue
with fragment parameter configuration.
Or, you can share the fragment with others at a later time. For details, see Pipeline Fragment Permissions.
- Publish and Close - Publishes the fragment and continues with fragment parameter configuration.
-
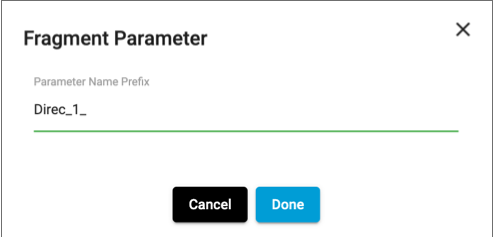
Specify a prefix for the names of runtime parameters in the fragment as needed,
and then click Done.
For more information, see Prefix for Runtime Parameters.
The original pipeline displays in the canvas, replacing the individual stages with the newly published fragment.
Fragment Input and Output
A published pipeline fragment displays in a pipeline as a fragment stage, with the input and output streams of the fragment stage representing the input and output streams of the fragment logic.
A fragment must include at least one open input or output stream. You cannot use a complete pipeline as a fragment.
When designing a pipeline fragment, consider carefully the number of input and output streams that you want to use. After you publish a fragment, you cannot change the number of input or output streams. This helps ensure that pipelines that use the fragment are not invalidated when you update the fragment.
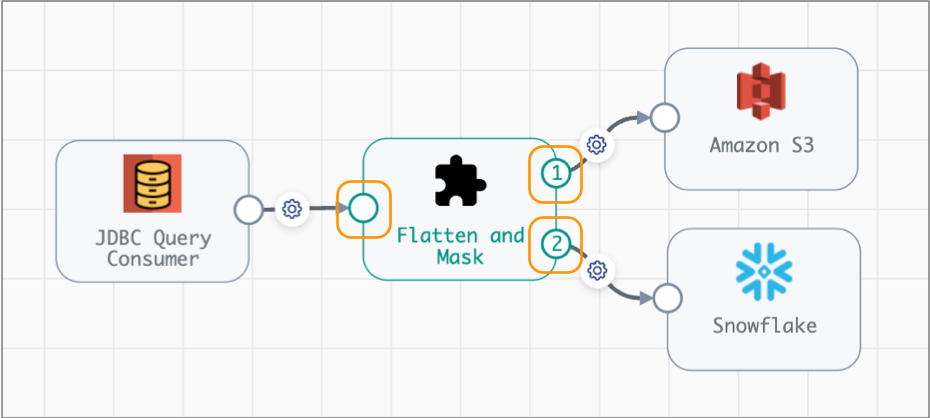
You can, however, change what the input and output streams represent. For example, the following Flatten and Mask fragment begins with one processor and ends with two processors. The input and output streams are highlighted below:
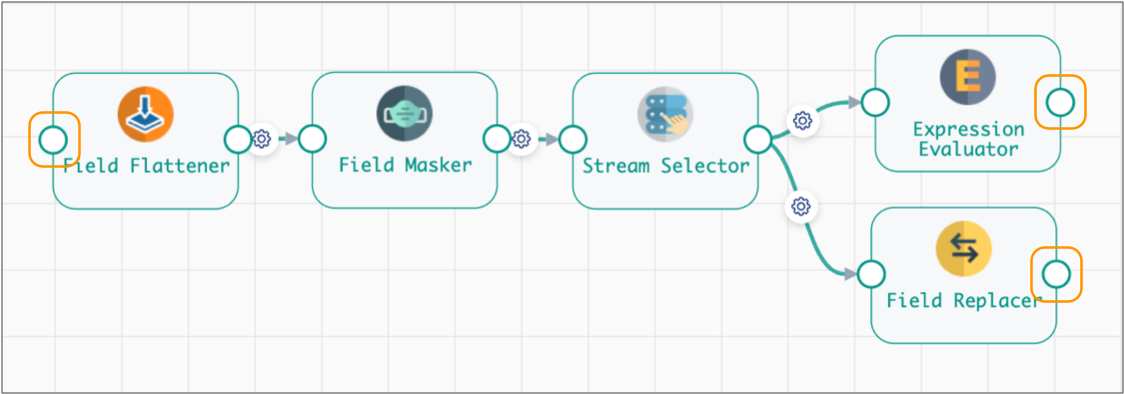
When you configure a pipeline, the Flatten and Mask fragment displays as a single fragment stage by default. The highlighted input and output streams of the Flatten and Mask fragment stage, represent the input and output streams of the fragment logic:
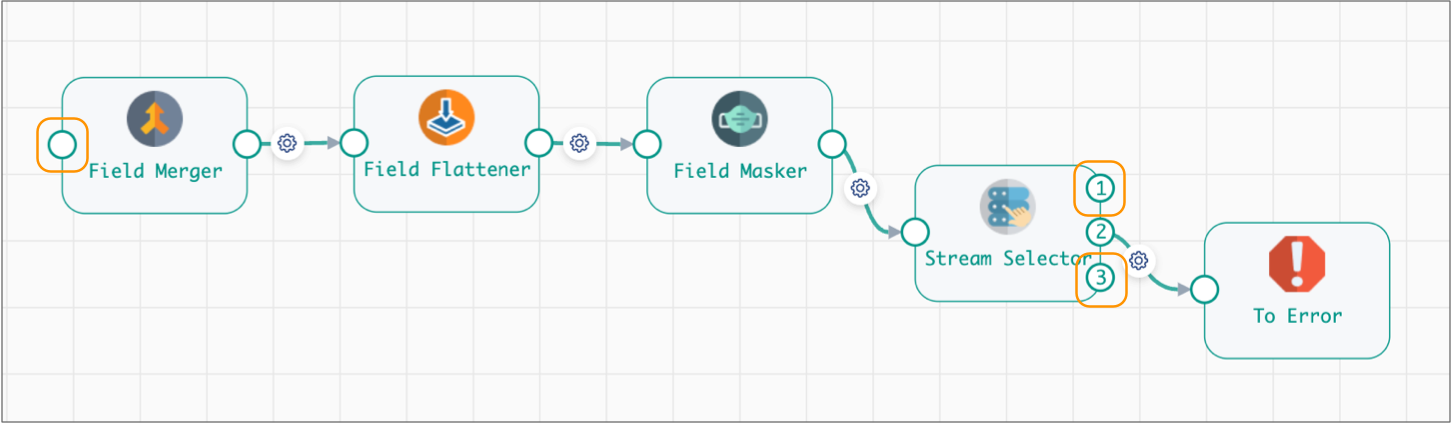
Subsequent versions of the Flatten and Mask fragment can change dramatically if needed, but must still include one input stream and two output streams.
For example, the following Flatten and Mask version begins with a new Field Merger processor, and the processors after the Stream Selector have been removed. The Stream Selector also has an additional output stream that sends qualifying records to the pipeline for error handling. But despite these changes, the number of input and output streams remains the same, so these changes are valid:
Execution Mode
- Batch
- Streaming
Define the execution mode for a Transformer fragment in the fragment properties.
The execution mode that you select determines the pipelines that you can use the fragment in. For example, batch fragments can only be used in batch pipelines.
You can edit a fragment to change its execution mode. But be aware that changing the fragment execution mode can make the fragment version invalid for pipelines that use the previous fragment version.
For more information about Transformer execution modes, see the Transformer documentation.
Data and Data Drift Rules and Alerts
When you configure a Data Collector pipeline fragment, you can configure data rules and alerts, and data drift rules and alerts. When you use the fragment in a pipeline, the pipeline inherits the rules and alerts.
If you delete the fragment from the pipeline, the rules and alerts defined in the fragment are deleted as well.
For more information about data and data drift rules and alerts, see the Data Collector documentation.
Runtime Parameters
You can configure runtime parameters in pipeline fragments to enable more flexible use of the fragment.
- In a fragment - You define and call runtime parameters and set their default values.
- In a pipeline - You can override the default values for any runtime parameters defined in an included fragment.
- In a job - You can override the values for any runtime parameter defined in the pipeline.
For example, you might create a fragment with a Directory origin that calls the runtime
parameter FilePath to retrieve the directory to read. In the fragment,
you set a default value for the FilePath parameter. In the pipeline,
you can set a different value for the directory, such as one directory for a development
pipeline and a different directory for a production pipeline. In jobs that include the
pipeline, you can set yet another value for the directory, such as one directory for the
European file server and a different directory for the Asian file server.
Prefix for Runtime Parameters
When adding a fragment to a pipeline, you can specify a prefix for the names of runtime parameters in the fragment. The prefix applies to any runtime parameters in the fragment, including those added later during a fragment update.
- Same values for runtime parameters - To use the same values for the runtime parameters in each fragment instance, enter the same prefix or remove the prefix for those fragment instances.
- Different values for runtime parameters - To use different values for the runtime parameters in each fragment instance, enter a unique prefix for those fragment instances.
For example, let's say that you create a fragment with a Local FS destination that calls the runtime parameter DirTemplate to define the directory to write to. You add two instances of the fragment to the same pipeline, defining a unique parameter name prefix so that the first fragment instance names the parameter Local_01_DirTemplate and the second names the parameter Local_02_DirTemplate. You can then define a different parameter value for each fragment instance so that each instance writes to a different directory. Otherwise, if you remove the prefix for each fragment instance, then both instances use a parameter named DirTemplate with the same value.
When adding a fragment, the pipeline inherits all the runtime parameters in the fragment with their default values and adds the prefix to the names of the runtime parameters. You can override the default value for a runtime parameter in the pipeline properties. You can also use the runtime parameter with the prefix elsewhere in the pipeline. From the pipeline, you cannot change how the fragment calls the runtime parameter, as you cannot edit the fragment from within the pipeline.
If you publish changes to fragments, you can update any pipelines that use that fragment to use the new version of the fragment. The update adds any new runtime parameters to the pipeline with the prefix specified for the pipeline, but the update does not change the default values for any existing runtime parameters in the pipeline.
Removing a Fragment with Parameters
When you remove a fragment with runtime parameters from a pipeline, the parameters are deleted from the pipeline if no remaining fragments share the same prefix as the removed fragment.
For example, if a pipeline includes a single fragment that uses the prefix
Fragment_1_ and you remove the fragment from the pipeline, all
parameters with that prefix are deleted from the pipeline. However, if the pipeline
includes multiple fragment instances that use the Fragment_1_ prefix
and you remove one fragment instance, then parameters with that prefix remain in the
pipeline.
If you define parameters in the pipeline and use the same parameter prefix used for a fragment in the pipeline, then those pipeline parameters are also deleted from the pipeline when you remove the fragment.
Fragment_1_ so that the fragment names the parameter
Fragment_1_DirTemplate. You then define a new parameter in
the pipeline named Fragment_1_LogPath. When you remove the
fragment from the pipeline, both the Fragment_1_DirTemplate and
Fragment_1_LogPath parameters are deleted from the
pipeline.Using Runtime Parameters
Use runtime parameters in pipeline fragments to support reuse of the fragment with different configurations.
In a pipeline fragment, you define runtime parameters and configure stages to call the runtime parameters. You can add the fragment to a pipeline and override the default values for the runtime parameters. In jobs for pipelines that contain the fragment, you can set different values for the runtime parameters.
-
Define the runtime parameter in the fragment properties.
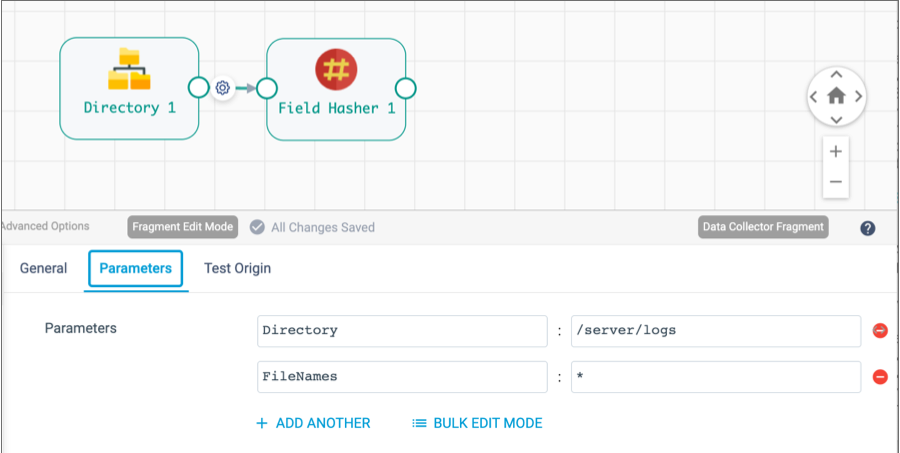
You specify the runtime parameter and default value on the Parameters tab of the pipeline fragment properties.
For example, the following image shows the Parameters tab of a fragment with two runtime parameters defined:
-
To use the runtime parameter in a stage, configure the stage property to call
the runtime parameter.
Enter the name of the runtime parameter in an expression, as follows:
${<runtime parameter name>}The following example uses runtime parameters to define the Files Directory and File Name Pattern properties in the Directory origin:
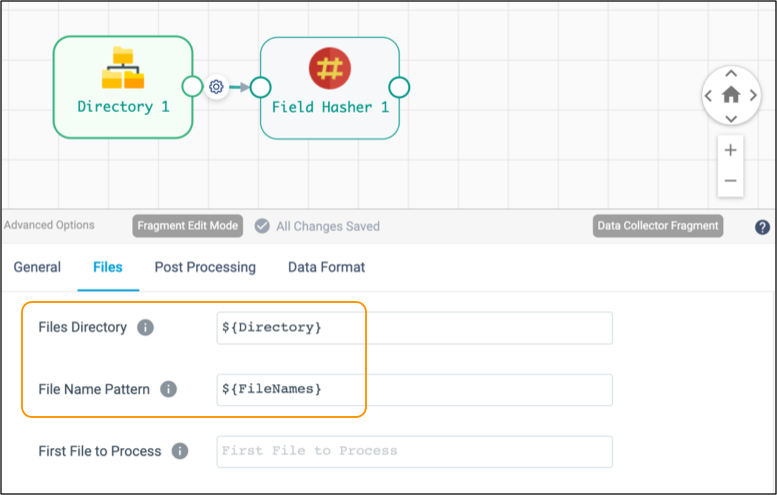
- Publish the fragment to make the fragment available to pipelines.
-
Add the fragment to a pipeline, specifying a prefix for the runtime parameters
in the fragment, as needed.
Specify a prefix based on how you want to handle runtime parameters when you reuse the same fragment in a pipeline:
- Same values for runtime parameters - To use the same values for the runtime parameters in each fragment instance, enter the same prefix or remove the prefix for those fragment instances.
- Different values for runtime parameters - To use different values for the runtime parameters in each fragment instance, enter a unique prefix for those fragment instances.
The pipeline inherits the runtime parameters with the default values defined in the fragment and adds the prefix to the names of the runtime parameters.
-
In the pipeline, override the runtime parameter values as needed.
You can configure the values for runtime parameters on the Parameters tab of the pipeline properties. For example, if you add a fragment and specify
Direc_1_as the prefix, you might override the runtime parameters, as follows: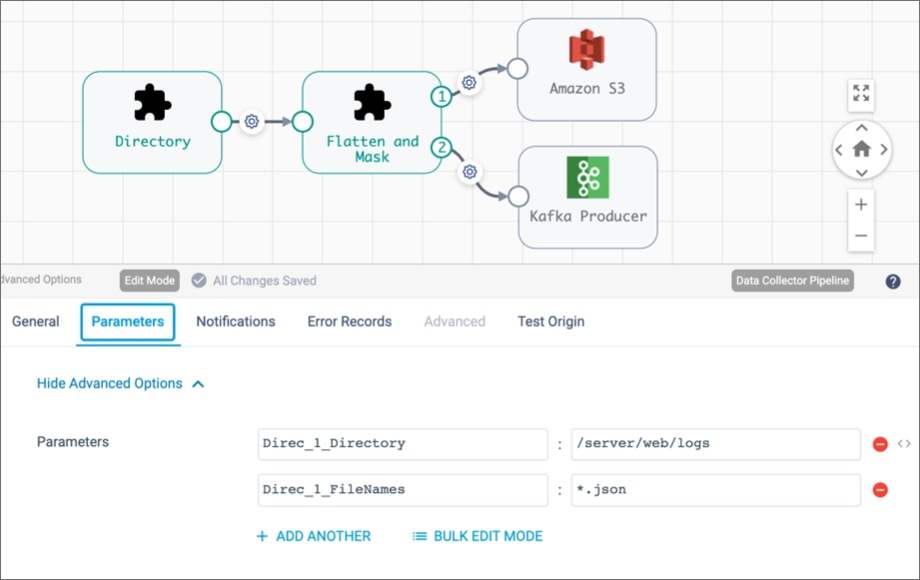
-
In any job created for the pipeline, review and override the runtime parameter
values as needed.
In the Create Job or Edit Job wizard, click Next until you reach the Define Runtime Parameters step, and then override the values as needed, as follows:
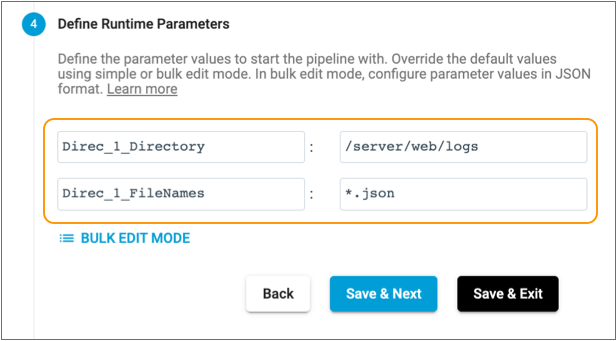
Creating Additional Streams
When you configure a Data Collector or Transformer fragment, you can use the Dev Identity processor to create an open input or output stream.
The Dev Identity processor is a development stage that performs no processing, it simply passes a record to the next processor unchanged. Though typically, you would not use the Dev Identity processor in a production pipeline, it can be useful in a pipeline fragment to create additional input or output streams.
For example, let's say you have several connected processors in a fragment that ends with a destination stage, resulting in a single input stream and no output streams, as follows:
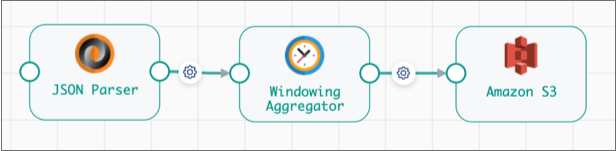
But in addition to writing the data to the Amazon S3 destination in the fragment, you want to pass the data processed by the JSON Parser to the pipeline for additional processing.
To create an output stream for the fragment, connect the JSON Parser processor to a Dev Identity processor, and leave the Dev Identity processor unconnected, as follows:
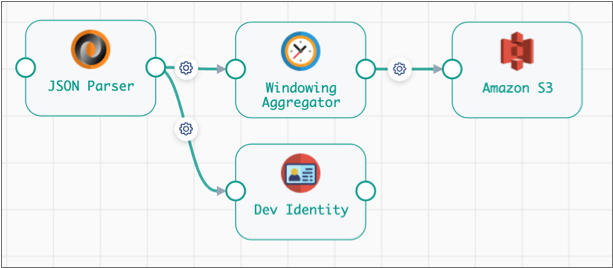
The resulting fragment stage includes an output stream that passes records processed by the JSON Parser to the pipeline:

With the fragment expanded, you can see how the Dev Identity processor passes data from the JSON Parser in the fragment to the additional branch defined in pipeline:
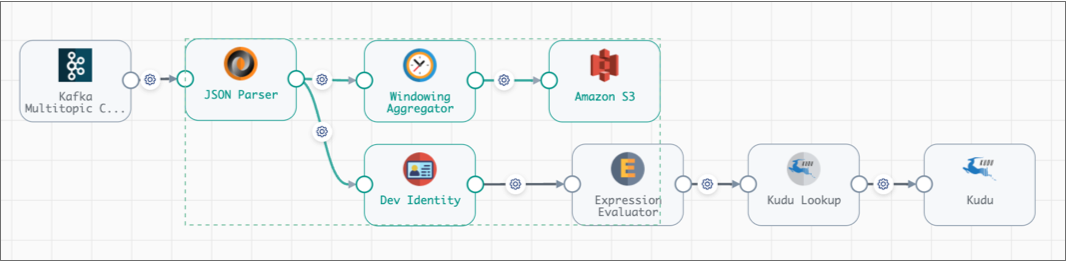
Data Preview
You can use data preview to help develop or test a pipeline fragment.
As with data preview for a pipeline, when you preview a fragment, Control Hub passes data through the fragment and allows you to review how the data passes and changes through each stage.
For a Data Collector fragment, you can use a test origin to provide source data for data preview. This can be especially useful when working with a fragment that does not include an origin. When the fragment contains an origin, you can also use the origin to provide source data for the preview.
For more information about test origins in Data Collector pipelines and fragments, see Test Origin for Preview in the Data Collector documentation.
Preview works the same for all engine types - Data Collector, Transformer, and Transformer for Snowflake. However, there are some behavior differences for each type. For more information, see Previewing Pipelines and Fragments.
Explicit Validation
At this time, you cannot use explicit validation when designing pipeline fragments. To perform validation for a fragment, publish the fragment and validate the fragment in a test pipeline.
In a test pipeline, you can connect a fragment to additional stages to create a complete pipeline, then use explicit validation.
- Connect a development origin to any fragment input streams.
- Connect any fragment output streams to a Trash destination.
- Use the Validate icon to validate the pipeline and fragment.
For example, say you want to validate the processing logic of the following Flatten and Mask fragment:
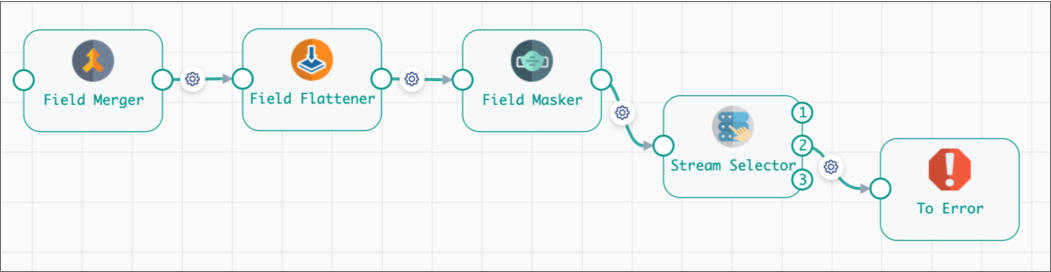
To test fragment processing, publish the fragment and add it to a pipeline.
To create a pipeline that passes implicit validation, you connect a Dev Raw Data Source - or any development origin - to the fragment input stream, then connect the fragment output streams to Trash destinations as follows:
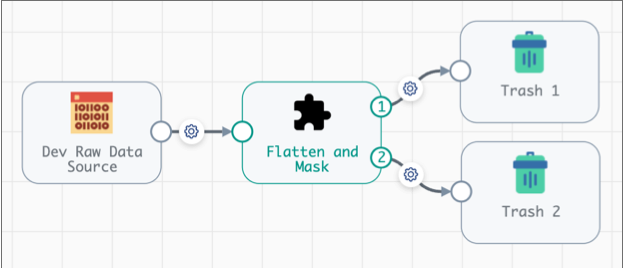
When you validate the pipeline, validation error messages display and are highlighted in the associated stage, as with any pipeline:
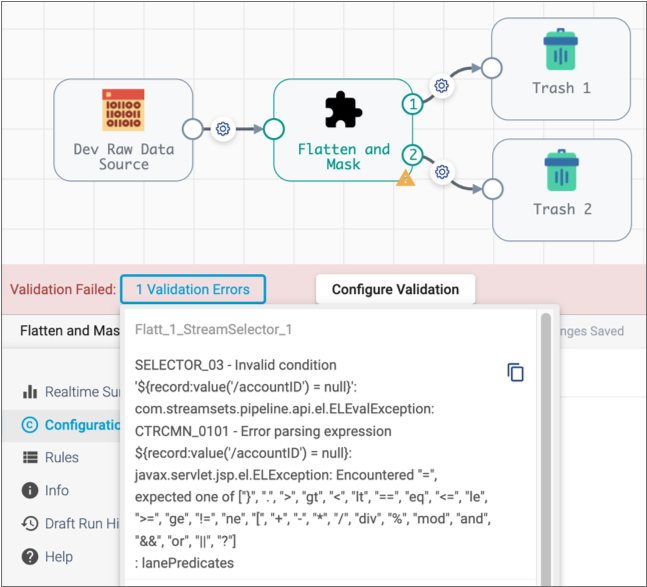
To view the stage with the problem, expand the fragment and review the stage properties:
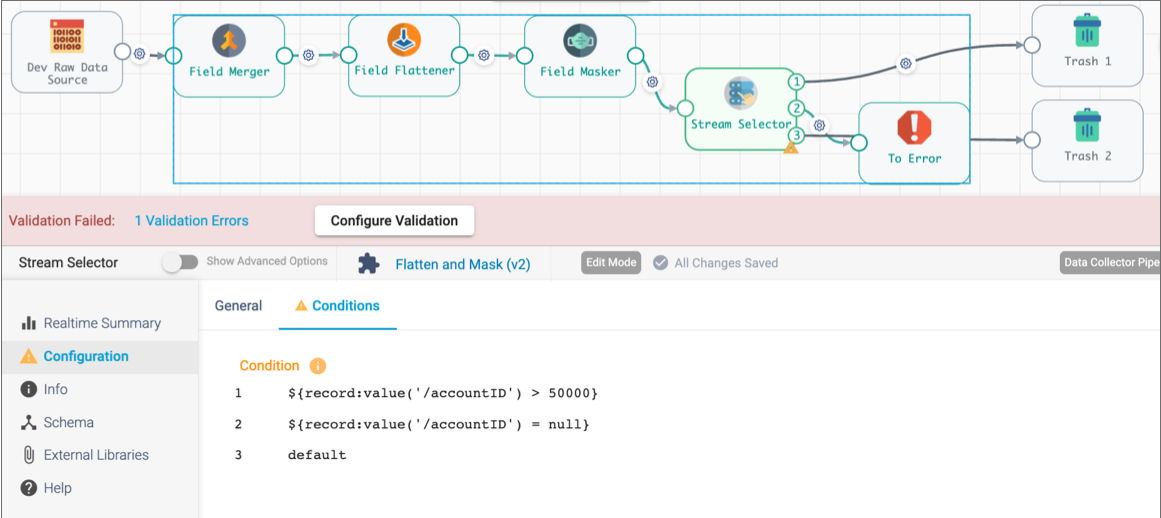
In this case, the Stream Selector conditions are invalid, so you can edit the fragment to update the expressions in the processor, then republish the fragment, update the pipeline to use the latest fragment version, and then validate the pipeline again.
Fragment Publishing Requirements
A fragment must meet several validation requirements to be published.
- At least one input or output stream must remain unconnected.
You cannot use a complete pipeline as a pipeline fragment.
- All stages in the fragment must be connected.
The pipeline canvas cannot include any unconnected stages when you publish the fragment.
- The number of input and output streams cannot change between fragment
versions.
When first published, the number of input and output streams in a fragment is defined. All subsequent versions must maintain the same number of input and output streams. This helps prevent invalidating pipelines that use the fragment.