Understanding Transformer for Snowflake
Transformer for Snowflake enables designing and performing complex processing with Snowflake data without writing SQL queries or templates.
For example, say you want to pivot a column to create columns for all distinct values and then aggregate the results. When using the Pivot command in a SQL query, you need to determine all values that exist in the column to be pivoted, then manually list each value in the query, along with the aggregate command. When you use Transformer for Snowflake, you simply add a Pivot processor to your pipeline, select the option to use all distinct values for the pivot, and select the aggregation type to perform.
Transformer for Snowflake performs DataFrame-based processing using Snowpark client libraries. You do not have to set up Snowpark in your Snowflake account to use Transformer for Snowflake.
Because Transformer for Snowflake is hosted on Control Hub, you can take advantage of robust enterprise features integral to Control Hub, such as permissions and version control.
To use Transformer for Snowflake, simply sign up with IBM StreamSets, provide your Snowflake credentials, and you are ready to design pipelines.
Transformer for Snowflake tag when you post your
question. To provide suggestions and feedback, add a new idea at https://ibm-data-and-ai.ideas.ibm.com/?project=SSETS.How It Works
To process Snowflake data using Transformer for Snowflake, you create a Transformer for Snowflake pipeline that represents the data to read, the processing you want to perform, and the tables to write to. Then, you create a job to run the pipeline.
When you run the job, Transformer for Snowflake generates a SQL query based on your pipeline configuration and passes the query to Snowflake for execution. Since Snowflake performs the work, all data processing occurs within Snowflake. When you run a job for a Transformer for Snowflake pipeline, your data never leaves Snowflake.
Snowflake data only enters Control Hub if you preview data during pipeline development. If you want to prevent your data from leaving Snowflake servers, you can disable this feature for your organization. For more information about data preview, see the Control Hub documentation.
Understanding Snowflake Pipelines
Transformer for Snowflake pipelines enable you to process Snowflake data without writing a SQL query or template.
When you configure a Transformer for Snowflake pipeline, you specify the Snowflake URL and the warehouse, database, and schema to use. Then, you configure stages to represent the data processing to perform.
In the pipeline, you define one or more origins to represent the Snowflake data to read. You add processors to represent the processing, such as joining or aggregating data. You can optionally add executors to perform tasks in Snowflake based on the data flow. Then, you configure one or more destinations to represent the Snowflake tables to write to. The destinations can create tables if they do not exist. They can even compensate for data drift by adding columns to Snowflake tables based on the data in the pipeline.
During pipeline development, you can use data preview to see how your pipeline configuration processes data, and use this information to improve your pipeline. For more information about previewing a pipeline, see the Control Hub documentation.
When your pipeline is ready, you create a job to run the pipeline. When you run the job, Transformer for Snowflake generates a SQL query based on your pipeline configuration and passes it to Snowpark for processing. The job uses securely stored user credentials to access your Snowflake account.
Unlike other pipelines, which can work with read from and write to different systems, Transformer for Snowflake pipelines are optimized to read from and write to Snowflake. Also, Transformer for Snowflake pipelines always perform batch processing. That is, they process all available data, and then stop.
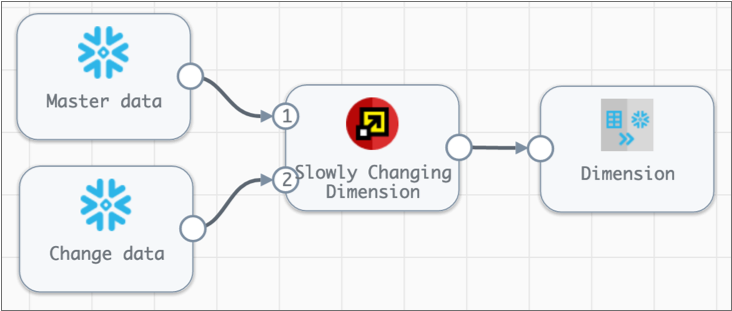
A Snowflake pipeline can be as simple or as complex as you need it to be. For example, the following pipeline compares change data with master data and then performs a Type 2 update of a slowly changing dimension:
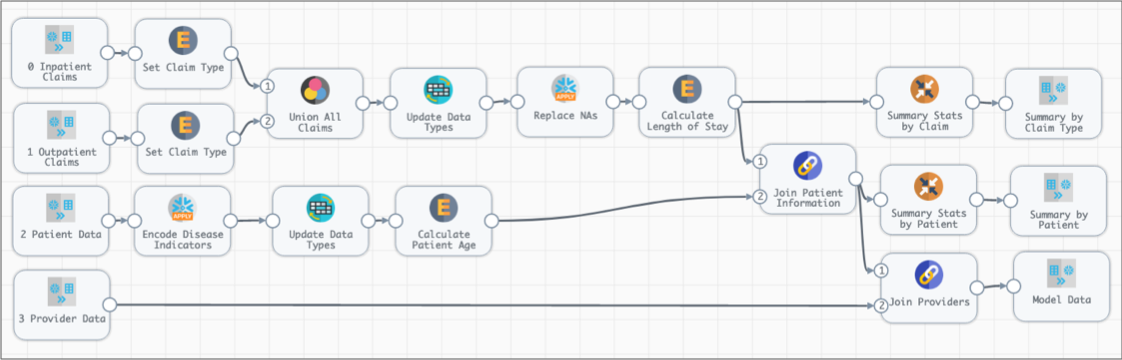
In contrast, the following pipeline prepares data to generate a model for provider fraud. It merges in-patient and out-patient claims after setting the claim type, then performs some additional processing before generating aggregate data summaries. The pipeline also processes patient information and joins it with claim and provider details to generate modeling data: