SQL Server 2019 Big Data Cluster
You can run Transformer pipelines using Spark deployed on SQL Server 2019 Big Data Cluster (BDC). Transformer supports SQL Server 2019 Cumulative Update 5 or later. SQL Server 2019 BDC uses Apache Livy to submit Spark jobs.
You specify the Livy endpoint, as well as the user name and password to access the cluster through the endpoint. When you start the pipeline, Transformer uses these credentials to launch the Spark application. You also define the staging directory within the cluster to store the StreamSets libraries and resources needed to run the pipeline.
Note the minimum Spark recommendations for running pipelines on SQL Server 2019 BDC.
mssql-mleap-lib-assembly-1.0.jar file from the
following HDFS ZIP file: /system/spark/spark_libs.zip. This issue
should be fixed in the next SQL Server 2019 BDC release.The following image displays a pipeline configured to run using Spark deployed on SQL Server 2019 BDC at the specified Livy endpoint:
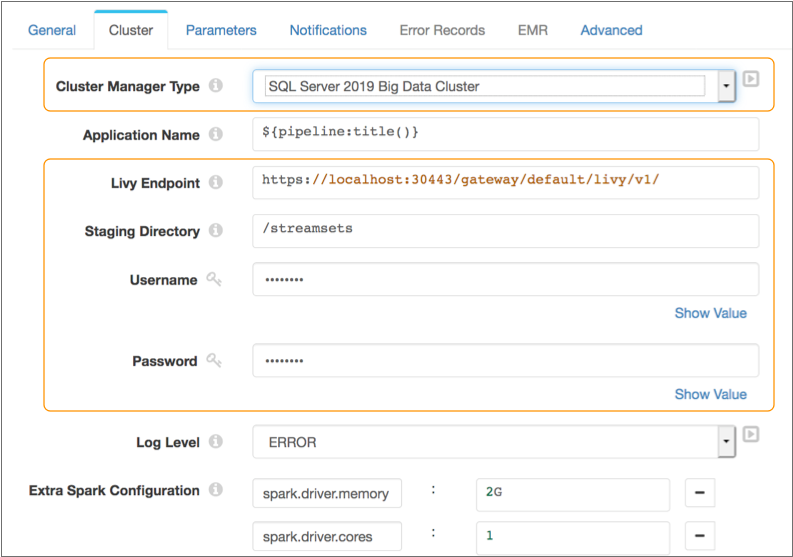
Transformer Installation Location
When you use SQL Server 2019 BDC as a cluster manager, Transformer must be installed in a location that allows submitting Spark jobs to the cluster.
StreamSets recommends installing Transformer in the Kubernetes pod where SQL Server 2019 BDC is located.
Recommended Spark Settings
The following table lists the minimum Spark settings recommended when running pipelines on SQL Server 2019 BDC. You can configure these properties on the cluster or in the pipeline:
| Spark Property | Recommended Minimum Setting |
|---|---|
| spark.driver.memory | 4 GB |
| spark.driver.cores | 1 |
| spark.executor.instances or
spark.dynamicAllocation.minExecutors |
5 |
| spark.executor.memory | 4 GB |
| spark.executor.cores | 1 |
Retrieving Connection Information
- Livy endpoint
- The SQL Server 2019 BDC Livy endpoint enables submitting Spark jobs. You can retrieve the Livy endpoint using the command line or using a client application such as Azure Data Studio. For information about using the command line, see the SQL Server 2019 BDC documentation.

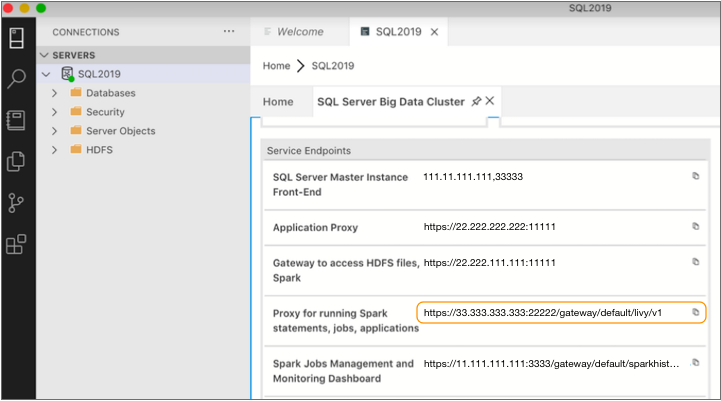
- User name and password
- For the user name, use the SQL Server 2019 BDC controller user name, which can submit Spark jobs through the Livy endpoint. When you start the pipeline, Transformer uses these credentials to launch the Spark application.
Staging Directory
To run pipelines on SQL Server 2019 BDC, Transformer must store files in a staging directory on SQL Server 2019 BDC.
You can configure the root directory to use as the staging directory. The default staging directory is /streamsets.
Pipelines that run on different clusters can use the same staging directory as long as the pipelines are started by the same Transformer instance. Pipelines that are started by different instances of Transformer must use different staging directories.
- Files that can be reused across pipelines
- Transformer stores files that can be reused across pipelines, including Transformer libraries and external resources such as JDBC drivers, in the following location:
- Files specific to each pipeline
- Transformer stores files specific to each pipeline, such as the pipeline JSON file and resource files used by the pipeline, in the following directory: