Amazon EMR
You can run Transformer pipelines using Spark deployed on an Amazon EMR cluster. Transformer supports several EMR versions. For a complete list, see Cluster Compatibility Matrix.
To run a pipeline on an EMR cluster, in the pipeline properties, you configure the pipeline to use EMR as the cluster manager type, then configure the cluster properties.
When you configure a pipeline to run on an EMR cluster, you can specify an existing Spark cluster, have Transformer provision a cluster, or have AWS Service Catalog provision a cluster.
Terminating a provisioned cluster after the pipeline stops is a cost-effective method of running a Transformer pipeline. Running multiple pipelines on a single existing cluster can also reduce costs.
To store the Transformer libraries and resources needed to run the pipeline, you define an S3 staging URI and a staging directory within the cluster.
You can configure the pipeline to use an instance profile or AWS access keys to authenticate with the EMR cluster. When you start the pipeline, Transformer uses the specified instance profile or AWS access key to launch the Spark application. You can also configure server-side encryption for data stored in the staging directory.
You can configure the maximum number of retry attempts for failed requests and related properties. You can also use a connection to configure the pipeline.
The following image shows part of the Cluster tab of a pipeline configured to run on an EMR cluster:
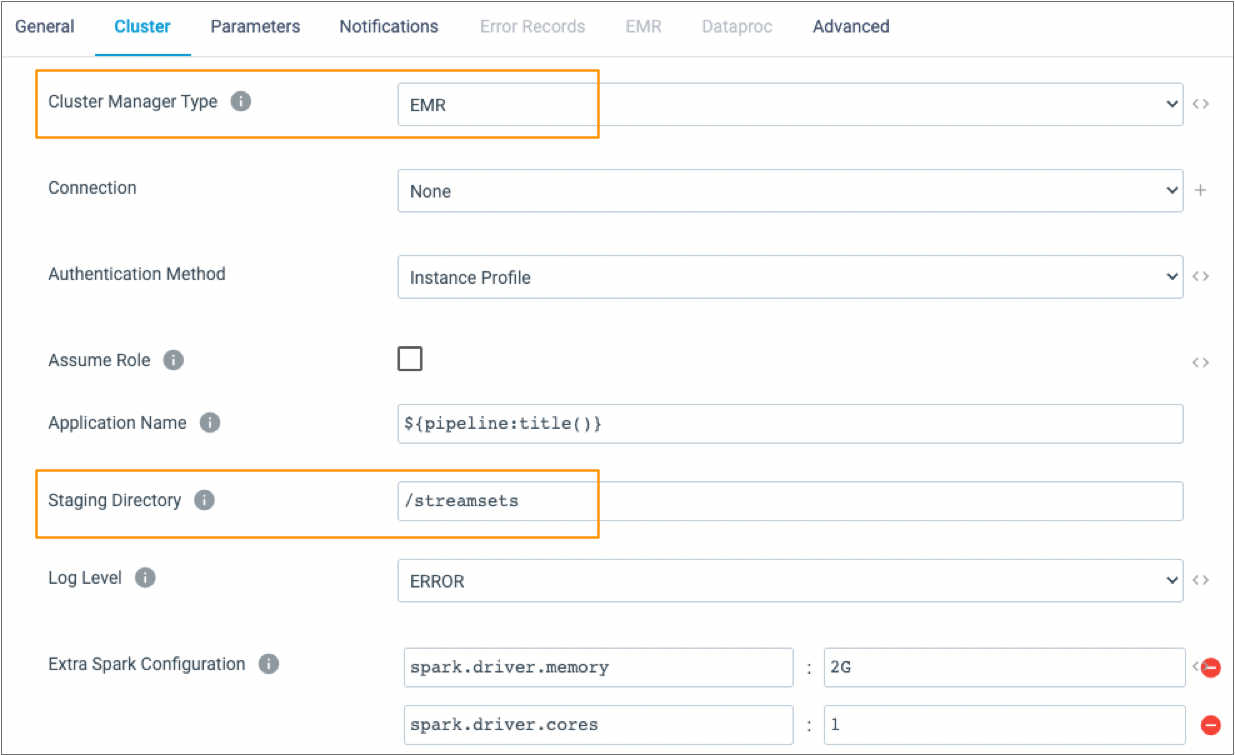
Transformer Installation Location
When you use EMR as a cluster manager, Transformer must be installed in a location that allows submitting Spark jobs to the cluster.
StreamSets recommends installing Transformer on an Amazon EC2 instance.
Authentication Method
You can specify the authentication method that Transformer uses to connect to an EMR cluster. When you start the pipeline, Transformer uses the specified instance profile or AWS access key to launch the Spark application.
- Instance profile
- When Transformer runs on an Amazon EC2 instance that has an associated instance profile, Transformer uses the instance profile credentials to automatically authenticate with AWS.
- AWS access keys
- When Transformer does not run on an Amazon EC2 instance or when the EC2 instance doesn’t have an instance profile, you can authenticate using an AWS access key pair. When using an AWS access key pair, you specify the access key ID and secret access key to use.
- None
- You can optionally choose to connect anonymously using no authentication.
You can also temporarily assume a specified role to connect to the Amazon EMR cluster. For more information, see Assume Another Role.
Server-Side Encryption
You can configure an EMR cluster to use Amazon Web Services server-side encryption (SSE). When configured for server-side encryption, Transformer passes required server-side encryption configuration values to Amazon S3. Amazon S3 uses the values to encrypt files loaded to the Amazon S3 staging directory.
- Amazon S3-Managed Encryption Keys (SSE-S3)
- When you use server-side encryption with Amazon S3-managed keys, Amazon S3 manages the encryption keys for you.
- AWS KMS-Managed Encryption Keys (SSE-KMS)
- When you use server-side encryption with AWS Key Management Service (KMS), you specify the Amazon resource name (ARN) of the AWS KMS master encryption key that you want to use.
For more information about using server-side encryption to protect data in Amazon S3, see the Amazon S3 documentation.
KMS Requirements
When you use server-side encryption with AWS Key Management Service (KMS), you must ensure that the appropriate permissions are granted.
- kms:ListKeys
The nodes must also have the following permission for the KMS master encryption key that you use:
- kms:GetPublicKey
- kms:Decrypt
- kms:DescribeKey
- kms:Encrypt
Kerberos Stage Limitations
Transformer can communicate securely with an EMR cluster that uses Kerberos authentication by default.
- File stages
- Hive stages
- Kafka stages
- Kudu stages
Force Stopping an EMR Job
When necessary, you can force jobs to stop. When forcing a job to stop, Transformer often stops processes before they complete, which can lead to unexpected results.
When you force stop an EMR job, Transformer first tries to stop the Spark job through the YARN service in the cluster. If the YARN service is reachable, it stops the job. If the YARN service is not reachable, Transformer sends a new step to the EMR cluster with the stop command.
As a result, if the YARN service is not reachable, Transformer can only force stop an EMR job when all of the following are true:
-
The Step Concurrency property in the pipeline is set to 2 or higher.
-
A step becomes available.
If the YARN service is not reachable and all three requirements above are not met, then Transformer cannot force stop the job.
Existing Cluster
You can configure a pipeline to run on an existing EMR cluster. When doing so, you specify the cluster to use by cluster ID or by cluster name or optional tags.
When an EMR cluster runs a Transformer pipeline, Transformer libraries are stored on the S3 staging URI and directory so they can be reused.
To run a pipeline on an existing EMR cluster, on the Cluster tab of the pipeline properties, set the Define Cluster Start Option property to Existing Cluster. Then, specify the cluster to use.
For best practices for configuring a cluster, see the Amazon EMR documentation.
Specifying a Cluster
When you configure pipeline properties for an existing EMR cluster, you specify the cluster to use by cluster ID, by default. If you prefer, you can specify the cluster using the cluster name and optional tags.
The cluster name property is case-sensitive. If your EMR account has access to more than one cluster by the same name, define tags to differentiate between the clusters.
To specify the cluster by ID, on the Cluster tab, enter the cluster ID in the Cluster ID property.
To specify the cluster by name and tags, on the Cluster tab, enable the Cluster by Name and Tags property. Then, specify a case-sensitive cluster name in the Cluster Name property.
To add optional tags, in the Cluster Tags property, click Add, then define a tag name and value for each tag that you want to define.
Transformer Provisioned Cluster
You can configure a pipeline to run on a cluster provisioned by Transformer. When Transformer provisions a cluster, Transformer creates a new EMR Spark cluster upon the initial run of a pipeline based on the specified properties. You can optionally have Transformer terminate the cluster after the pipeline stops.
When using a cluster provisioned by Transformer, you specify cluster details such as the EMR version, the instance types to create, and the ID of the subnet to create the cluster in. You can define bootstrap actions to execute before processing data. You also indicate whether to terminate the cluster after the pipeline stops.
You can define the number of EC2 instances that the cluster uses to process data. The minimum is 2. To improve performance, you might increase that number based on the number of partitions that the pipeline uses. You can also configure the pipeline to save log data to a different location to avoid losing that data when the cluster terminates.
Optionally, you can specify an SSH key to access the cluster nodes for monitoring or troubleshooting. Make sure that the security group assigned to the EMR cluster allows access to the EC2 nodes. Or, you can use a bootstrap action to set up SSH on the provisioned cluster instead of specifying the SSH key.
To run a pipeline on a cluster provisioned by Transformer, on the Cluster tab of the pipeline properties, set the Define Cluster Start Option property to Provision New Cluster. Then, define the cluster configuration properties.
For a full list of provisioning properties, see Configuring a Pipeline. For best practices for configuring a cluster, see the Amazon EMR documentation.
Bootstrap Actions
When you have Transformer provision an EMR cluster, you can define bootstrap actions to execute before processing data. You might use bootstrap actions to perform tasks such as installing a driver on the cluster or creating directories and setting permissions on them.
To use bootstrap actions, you can define the scripts to use in the cluster configuration properties or you can specify bootstrap actions scripts stored on Amazon S3.
When you specify more than one bootstrap action, place them in the order that you want them to run. If a bootstrap action fails to execute, Transformer cancels the cluster provisioning and stops the job.
For more information about EMR bootstrap actions, see the EMR documentation.
Example
You can use a bootstrap action to set up SSH on the provisioned cluster.
#!/bin/bash
cat > /tmp/authorized_keys << EOF
<PUBLIC_SSH_KEY>
EOF
sudo sh -c 'mv /tmp/authorized_keys /home/ec2-user/.ssh/authorized_keys'
sudo sh -c 'chown ec2-user:ec2-user /home/ec2-user/.ssh/authorized_keys'
sudo sh -c 'chmod 600 /home/ec2-user/.ssh/authorized_keys'You could alternatively save the script on S3 and specify the script location in the Bootstrap Actions cluster configuration property.
Transformer-Provisioned Cluster Names
<clusterPrefix>::<pipelineId>Where clusterPrefix is defined by the Cluster Prefix pipeline property,
and pipelineId is generated by Transformer.
- AWS tag name:
streamsets-emr-provision - AWS tag value: Transformer-generated pipeline ID
When you do not configure the pipeline to terminate the cluster, Transformer uses the pipeline ID and AWS tag to locate the cluster for subsequent pipeline runs.
AWS Service Catalog Provisioned Cluster
You can configure a pipeline to run on an EMR cluster provisioned by AWS Service Catalog. When provisioning a cluster, AWS Service Catalog creates a new EMR Spark cluster within a new AWS Service Catalog product upon the initial run of a pipeline. Before using AWS Service Catalog to provision a cluster, complete the prerequisite tasks.
When using a cluster provisioned by AWS Service Catalog, you specify the product ID and version name. You can specify the name for the provisioned cluster, or you can have AWS Service Catalog generate the name.
When available, you can specify parameters to pass to AWS Service Catalog. The parameter names and values must correspond to parameters allowed by your product template. For more information, see the AWS documentation. You can also have AWS Service Catalog terminate the provisioned cluster and AWS Service Catalog product when the pipeline stops.
To run a pipeline on a cluster provisioned by AWS Service Catalog, on the Cluster tab of the pipeline properties, set the Define Cluster Start Option property to AWS Service Catalog. Then, define the cluster configuration properties.
For more information about AWS Service Catalog, see the AWS documentation.
AWS Service Catalog Prerequisites
To enable AWS Service Catalog to provision an EMR cluster to run a pipeline, you must add a product to AWS Service Catalog for the cluster that you want to create.
- Use AWS CloudFormation to create a template for the EMR cluster.
- Register the EMR cluster template as a product with an AWS Service Catalog portfolio.
For information about adding a product and creating a product template, see the AWS documentation.
AWS Service Catalog Provisioned Cluster Names
EMR clusters provisioned by AWS Service Catalog are named based on the AWS Service Catalog template for the product used to provision the cluster.
The cluster also includes an AWS tag that is defined as follows:
- AWS tag name:
streamsets-service-catalog - AWS tag value: Transformer-generated pipeline ID
When you do not configure the pipeline to terminate the cluster, Transformer uses the AWS tag to locate the cluster for subsequent pipeline runs.
S3 Staging URI and Directory
To run pipelines on an EMR cluster, Transformer must store files on Amazon S3.
Transformer stores libraries in the following location: <S3 staging URI>/<staging
directory>.
- Staging Directory
- S3 Staging URI
When a pipeline runs on an existing cluster, you might configure pipelines to use the same S3 staging URI and staging directory. This allows EMR to reuse the common files stored in that location. Pipelines that run on different clusters can also use the same staging locations as long as the pipelines are started by the same Transformer instance. Pipelines started by different Transformer instances must use different staging locations.
When a pipeline runs on a provisioned cluster, using the same location is best practice, but not required.
- Files that can be reused across pipelines
- Transformer stores files that can be reused across pipelines, including Transformer libraries and external resources such as JDBC drivers, in the following location:
- Files specific to each pipeline
- Transformer stores files specific to each pipeline, such as the pipeline JSON file and resource files used by the pipeline, in the following directory:
Monitoring EMR Pipelines
transformer.emr.monitoring.max.retry- Defines how many times Transformer retries retrieving monitoring information. Default is 3.transformer.emr.monitoring.retry.base.backoff- Defines the minimum number of seconds to wait between retries. Default is 15.transformer.emr.monitoring.retry.max.backoff- Defines the maximum number of seconds to wait between retries. Default is 300, which is 5 minutes.
If Transformer cannot access monitoring information within the specified retries, it assumes that the Spark job for the pipeline is not running and stops the pipeline.
When needed, you can configure these properties in the Transformer configuration properties of the deployment.