Hadoop YARN
You can run Transformer pipelines using Spark deployed on a Hadoop YARN cluster. Transformer supports several distributions of Hadoop YARN. For a complete list, see Cluster Compatibility Matrix.
Before running a pipeline on a Hadoop YARN cluster, ensure all requirements are met.
When you configure a pipeline to run on a Hadoop YARN cluster, you configure the deployment mode used for the launched application. By default, Transformer uses the user who starts the pipeline as the proxy user to launch the Spark application and access files in the Hadoop system. If you enable Transformer to use Kerberos authentication or Hadoop impersonation, you can override the default proxy user that launches the Spark application.
The following image displays a pipeline configured to run on Spark deployed to a Hadoop YARN cluster:
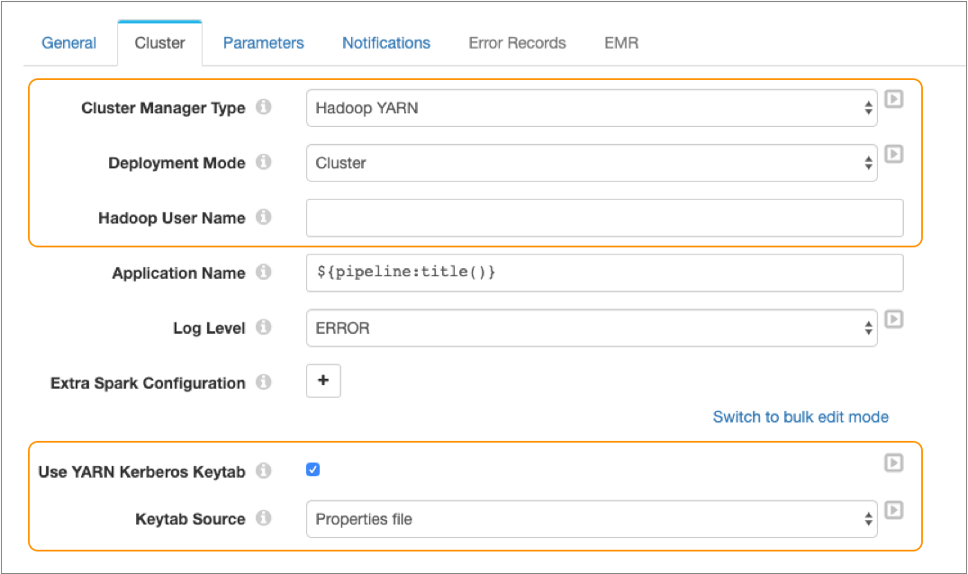
Notice how this pipeline is configured to run in cluster deployment mode. The Hadoop user name is not defined because the pipeline is configured to use Kerberos authentication.
Deployment Mode
Cluster pipelines on Hadoop YARN can use one of the following deployment modes:
- Client
-
In client deployment mode, the Spark driver program is launched on the local machine outside of the cluster. Use client mode when the Transformer machine is physically co-located with the cluster worker machines.
- Cluster
- In cluster deployment mode, the Spark driver program is launched remotely on one of the worker nodes inside the cluster. Use cluster mode when the Transformer machine is physically located far from the worker machines. In this case, using cluster mode minimizes network latency between the drivers and the executors.
For more information about deployment modes, see the Apache Spark documentation.
Transformer Proxy Users
To ensure that Transformer pipelines run as expected, ensure that all Transformer proxy users have permissions on the required directories.
By default, Transformer uses the user who starts a pipeline as a proxy user to launch the Spark application and to access files in the Hadoop system.
When the Hadoop YARN cluster uses Kerberos authentication, you must enable proxy users for Kerberos in the Transformer installation. Or, you can configure individual pipelines to use a Kerberos principal and keytab to override the default proxy user.
When Transformer uses Hadoop impersonation without Kerberos authentication, you can configure a Hadoop user in individual pipelines to override the default proxy user, the user who starts the pipeline.
You can use a Transformer configuration property to prevent overriding the proxy user. This option is highly recommended. It ensures that the user who starts the pipeline is always used as the proxy user and prevents users from entering a different user name in pipeline properties.
Kerberos Authentication
When the Hadoop YARN cluster uses Kerberos authentication, Transformer uses the user who starts the pipeline as the proxy user to launch the Spark application and to access files in the Hadoop system, unless you configure a Kerberos principal and keytab for the pipeline.
Using a Kerberos principal and keytab enables Spark to renew Kerberos tokens as needed, and is strongly recommended.
For example, you should configure a Kerberos principal and keytab for long-running pipelines, such as streaming pipelines, so that the Kerberos token can be renewed by Spark. If Transformer uses a proxy user for a pipeline that runs for longer than the maximum lifetime of the Kerberos token, the Kerberos token expires and the proxy user cannot be authenticated.
For more information about submitting Spark applications to Hadoop clusters that use Kerberos authentication, see the Apache Spark documentation.
Enabling Kerberos for Hadoop YARN Clusters
When a Hadoop YARN cluster uses Kerberos authentication, Transformer uses the user who starts the pipeline as the proxy user to launch the Spark application and to access files in the Hadoop system, unless you configure a Kerberos principal and keytab for the pipeline. The Kerberos keytab source can be defined in the Transformer properties file or in the pipeline configuration.
Using a Kerberos principal and keytab enables Spark to renew Kerberos tokens as needed, and is strongly recommended.
Before pipelines can use proxy users or use the keytab source defined in the Transformer properties file, you must enable these options in the Transformer installation.
Enabling Proxy Users
Before pipelines can use proxy users with Kerberos authentication, you must install
the required Kerberos client packages on the Transformer machine and then configure the environment variables used by the K5start
program.
-
On Linux, install the following Kerberos client packages on the Transformer machine:
krb5-workstationkrb5-clientK5start, also known askstart
- Copy the keytab file that contains the credentials for the Kerberos principal to the Transformer machine.
-
Define the
following environment variables on the Transformer machine.
Environment Variable Description TRANSFORMER_K5START_CMD Absolute path to the K5startprogram on the Transformer machine.TRANSFORMER_K5START_KEYTAB Absolute path and name of the Kerberos keytab file copied to the Transformer machine. TRANSFORMER_K5START_PRINCIPAL Kerberos principal to use. Enter a service principal. - Restart Transformer.
Enabling the Properties File as the Keytab Source
Before pipelines can use the keytab source defined in the Transformer configuration properties, you must configure a Kerberos keytab and principal for Transformer.
-
Copy the keytab file that contains the credentials for the Kerberos principal
to the Transformer machine.
The default location is the Transformer configuration directory, $TRANSFORMER_CONF.
-
In Control Hub, edit the deployment. In the
Configure Engine section, click Advanced
Configuration. Then, click Transformer
Configuration.
Configure the following Kerberos properties in the file:
Kerberos Property Description kerberos.client.principal Kerberos principal to use. Enter a service principal. kerberos.client.keytab Path and name of the Kerberos keytab file copied to the Transformer machine. Enter an absolute path or a path relative to the $TRANSFORMER_CONFdirectory. - Restart Transformer.
Using a Keytab for Each Pipeline
Configure pipelines to use a Kerberos keytab and specify the source of the keytab. When you do not specify a keytab source, Transformer uses the user who starts the pipeline to launch the Spark application and to access files in the Hadoop system.
When using a keytab, Transformer uses the Kerberos principal to launch the Spark application and to access files in the Hadoop system. Transformer also includes the keytab file with the launched Spark application so that the Kerberos token can be renewed by Spark.
- Transformer configuration properties
- The pipeline uses the same Kerberos keytab and principal configured for Transformer in the Transformer configuration properties.
- Pipeline configuration - file
- The pipeline uses the Kerberos keytab file and principal configured for the pipeline. Store the keytab file on the Transformer machine.
- Pipeline configuration - credential store
- The pipeline uses the Kerberos keytab file and principal configured for the
pipeline. Add the Base64-encoded keytab to a credential store, and then use
a credential function to retrieve the keytab from the credential
store.Note: Be sure to remove unnecessary characters, such as newline characters, before encoding the keytab.
Hadoop Impersonation Mode
When the Hadoop YARN cluster is configured for impersonation but not for Kerberos authentication, you can configure the Hadoop impersonation mode that Transformer uses when performing tasks in the Hadoop system.
- As the user defined in the pipeline properties - When configured, Transformer uses the specified Hadoop user to launch the Spark application and to access files in the Hadoop system.
- As the currently logged in Transformer user who starts the pipeline - When no Hadoop user is defined in the pipeline properties, Transformer uses the user who starts the pipeline.
The system administrator can configure Transformer to
always use the user who starts the pipeline by enabling the
hadoop.always.impersonate.current.user property in the Transformer
configuration properties. When enabled, configuring a Hadoop user within a pipeline is not allowed.
Configure Transformer to always impersonate as the user who starts the pipeline when you want to prevent access to data in Hadoop systems by the pipeline-level property.
For example, say you use roles, groups, and pipeline permissions to ensure that only authorized operators can start pipelines. You expect that the operator user accounts are used to access all external systems. But a pipeline developer can specify an HDFS user in a pipeline and bypass your attempts at security. To close this loophole, configure Transformer to always use the user who starts the pipeline to read from or write to Hadoop systems.
To always use the user who starts the pipeline, in the Transformer
configuration properties, uncomment the hadoop.always.impersonate.current.user property and
set it to true.
Lowercasing User Names
When Transformer impersonates Hadoop users to perform tasks in Hadoop systems, you can also configure Transformer to lowercase all user names before passing them to Hadoop.
When the Hadoop system is case sensitive and the user names are lower case, you might use this property to lowercase mixed-case user names that might be returned.
To lowercase user names before passing them to Hadoop, in the Transformer
configuration properties, uncomment the hadoop.always.lowercase.user property and set it to
true.
Working with HDFS Encryption Zones
Hadoop systems use the Hadoop Key Management Server (KMS) to obtain encryption keys. To enable access to HDFS encryption zones while using proxy users, configure KMS to allow the same user impersonation as you have configured for HDFS.
hadoop.kms.proxyuser.<user>.groupshadoop.kms.proxyuser.<user>.hosts
Where <user> is either the Hadoop user defined in the Hadoop User
Name pipeline property, or the user who started Transformer if a Hadoop user is not defined.
For example, with tx as the user specified in the Hadoop User Name
pipeline property, the following properties allow users in the Ops group access to the
encryption zones:
<property>
<name>hadoop.kms.proxyuser.tx.groups</name>
<value>Ops</value>
</property>
<property>
<name>hadoop.kms.proxyuser.tx.hosts</name>
<value>*</value>
</property>Note that the asterisk (*) indicates no restrictions.
For more information about configuring KMS proxyusers, see the KMS documentation for the Hadoop distribution that you are using. For example, for Apache Hadoop, see KMS Proxyuser Configuration.