Cloudera Data Engineering
You can run Transformer pipelines using Spark deployed on an existing Cloudera Data Engineering (CDE) virtual cluster. Transformer supports several CDE versions. For a complete list, see Cluster Compatibility Matrix.
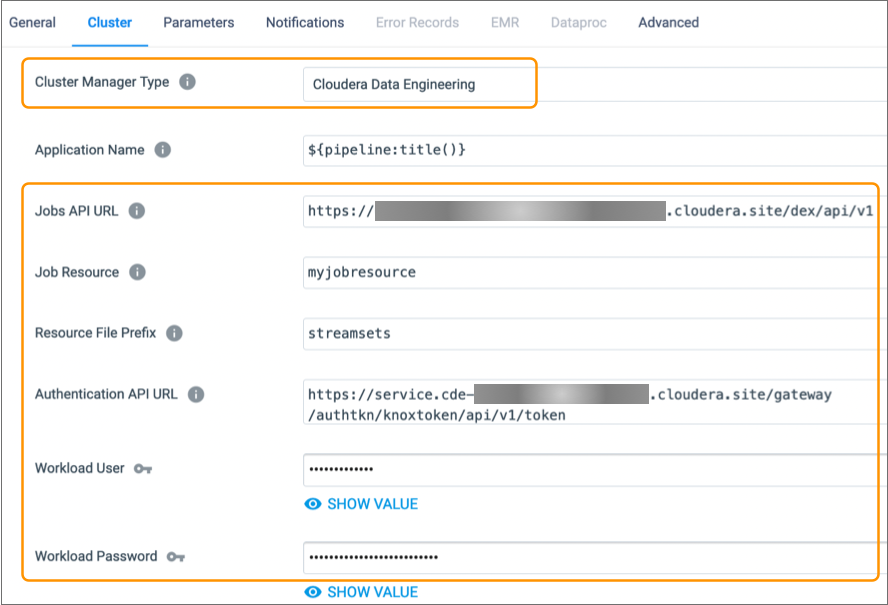
To run a pipeline on a CDE virtual cluster, configure the pipeline to use Cloudera Data Engineering as the cluster manager type on the Cluster tab of the pipeline properties.
When you configure a pipeline to run on a CDE cluster, you specify a jobs API URL, an authentication API URL, a workload user and password, and the log level to use. You also specify a job resource and a resource file prefix for pipeline-related files.
When configuring the pipeline, be sure to include only the supported stages.
The following image shows the Cluster tab of a pipeline configured to run on a Cloudera Data Engineering cluster:
Supported Stages
Transformer does not support using all available stages in pipelines that run on Cloudera Data Engineering clusters.
- AWS cluster-provided libraries
- Basic
- File
- Hive
- Kafka cluster-provided libraries
Job Resource and Resource File Prefix
To run pipelines on a Cloudera Data Engineering cluster, Transformer stores resource files in the Cloudera Data Engineering job resource that you specify in the pipeline properties.
streamsets, which results in a directory-like
structure to the file name, as
follows:streamsets/<file name>- Files that can be reused across pipelines
- Transformer stores files in the job resource that can be reused across pipelines,
including Transformer libraries and external resources such as JDBC drivers. Reusable files
include the Transformer version in the name, as
follows:
<resource file prefix>/<Transformer version>/<file name> - Files specific to each pipeline
- Transformer stores files in the job resource that are specific to each pipeline, such
as the pipeline JSON file. Pipeline-specific files include the pipeline ID
and run ID, as
follows:
<resource file prefix>/<pipelineId>/<runId>/<file name>
Amazon S3 and HDFS Prerequisites
- Amazon S3
- To read from or write to Amazon S3, complete the following tasks:
- In Cloudera Data Engineering, ensure that the workload user
specified in the CDE pipeline properties has a role mapping that
includes the following permissions for the Amazon S3 bucket
specified in the Amazon S3 stage:
- s3:ListBucket
- s3:GetBucketLocation
- s3:GetObject
- s3:PutObject
- s3:DeleteObject
- In the Amazon S3 origin or destination, on the Advanced tab, add one
of the following Spark properties to the Additional Configuration
property:
- For Spark 3.x clusters, add the
spark.kerberos.access.hadoopFileSystemsproperty and set it to the Amazon S3 bucket to access. For example:s3://<s3-bucket-name>
- For Spark 3.x clusters, add the
- In Cloudera Data Engineering, ensure that the workload user
specified in the CDE pipeline properties has a role mapping that
includes the following permissions for the Amazon S3 bucket
specified in the Amazon S3 stage:
- HDFS
- To read from or write to HDFS, on the File tab of the Files origin or
destination, add the following Spark properties to the Additional
Configuration property:
- Add one of the following properties based on the Spark version that
the cluster uses:
- For Spark 3.x clusters, add the
spark.kerberos.access.hadoopFileSystemsproperty and set it to the HDFS file system to access. For example:hdfs://<hdfs-host>:<port>
- For Spark 3.x clusters, add the
- To avoid connection errors, also add the
spark.hadoop.fs.defaultFSproperty and set it to the same HDFS file system as above. - To avoid Kerberos errors, add both of the following properties, and
set them to your HDFS principal:
spark.hadoop.dfs.datanode.kerberos.principalspark.hadoop.dfs.namenode.kerberos.principal
- Add one of the following properties based on the Spark version that
the cluster uses: