Databricks
You can run Transformer pipelines using Spark deployed on a Databricks cluster. Transformer supports several Databricks versions. For a complete list, see Cluster Compatibility Matrix.
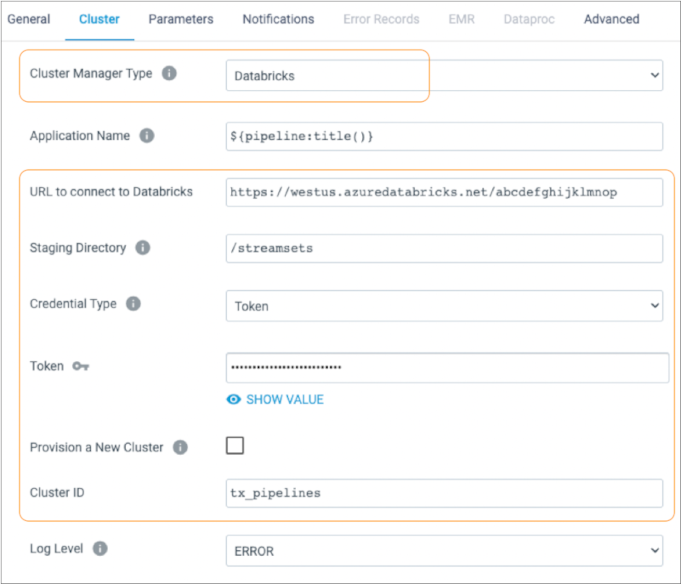
To run a pipeline on a Databricks cluster, configure the pipeline to use Databricks as the cluster manager type on the Cluster tab of pipeline properties.
Transformer uses the Databricks REST API to perform tasks on Databricks clusters, such as submitting an ephemeral Databricks job to run the pipeline. Databricks retains details about ephemeral jobs for 60 days. When necessary, access job details while they are available.
To use Google stages in pipelines running on a Databricks cluster, you must configure specific Spark properties.
When you configure a pipeline to run on a Databricks cluster, you can specify an existing interactive cluster to use or you can have Transformer provision a job cluster to run the pipeline.
In pipelines that use an existing interactive cluster, you must specify any extra Spark configuration properties in Databricks. This requires you to restart the cluster. For details about specifying Spark configuration properties, see the Databricks documentation.
For both interactive and provisioned clusters, you define the staging directory within the Databricks File System (DBFS) to store the StreamSets libraries and resources needed to run the pipeline. You also specify the URL and credentials used to connect to your Databricks account. When you start a pipeline, Transformer uses these credentials to launch the Spark application.
The following image displays a pipeline configured to run on Spark deployed to an existing Databricks cluster on Microsoft Azure:
Spark Properties for Google Stages
To use Google stages in pipelines running on a Databricks cluster, you must configure specific Spark properties.
In pipelines that use existing clusters, you must configure the Spark properties in Databricks. For details, see the Databricks documentation. In pipelines that provision clusters, you can configure the properties in the Extra Spark Configuration property of the pipeline.
| Spark Property | Description |
|---|---|
| spark.hadoop.google.cloud.auth.service.account.enable | Flag that indicates whether to enable the Google Cloud authentication service. Set to true. |
| spark.hadoop.fs.gs.auth.service.account.email | Client email address. |
| spark.hadoop.fs.gs.project.id | Project ID. |
| spark.hadoop.fs.gs.auth.service.account.private.key | Private key. |
| spark.hadoop.fs.gs.auth.service.account.private.key.id | Private key ID. |
Existing Cluster
You can configure a pipeline to run on an existing Databricks interactive cluster.
When a Databricks cluster runs a Transformer pipeline, Transformer libraries are installed on the cluster so they can be reused. Pipelines from different versions of Transformer cannot run on the same Databricks cluster.
For example, say you have a cluster that previously ran pipelines built on Transformer 5.8.0. When you build new pipelines using Transformer 6.0.0, the new pipelines cannot run on that cluster.
In this situation, you can run the pipeline on a different existing cluster or configure the pipeline to provision a cluster. If the existing cluster no longer runs pipeline from the older Transformer version, you can uninstall the older Transformer libraries from the cluster and use the cluster to run pipelines from the newer Transformer version.
To run a pipeline on an existing Databricks cluster, clear the Provision a New Cluster property on the Cluster tab, then specify the ID of the cluster to use. You must configure any extra Spark configuration properties in Databricks. This requires you to restart the cluster. For details about specifying Spark configuration properties, see the Databricks documentation.
Uninstalling Transformer Libraries
For example, say you have a cluster that previously ran pipelines built on Transformer 5.8.0. When you build new pipelines using Transformer 6.0.0, the new pipelines cannot run on that cluster.
To enable a cluster to run pipelines from a different version of Transformer, uninstall the existing Transformer libraries from the cluster. Perform this task when you no longer want to run pipelines from the other version of Transformer.
The following details are provided for your convenience. If the Databricks workflow changes, please check the Databricks documentation for updated steps.
-
In the Databricks Workspace, click the cluster name, then click the
Libraries tab.
The libraries list displays the names and source directory of each library installed on the cluster.The Transformer libraries are those installed from the staging directory specified in your pipelines. For example, if you used the default
/streamsetsstaging directory, then you might see a list of libraries as follows:dpfs://streamsets/<transformer version>/streamsets-transformer-dist-<version>.jar dbfs://streamsets/<transformer version>/streamsets-transformer-<library name>-<version>.jar dbfs://streamsets/<transformer version>/streamsets-scala-compiler-<version>.jar ... - Locate and select the Transformer libraries in the list.
-
Click Uninstall, then click
Confirm.
You must restart the cluster to remove the library.
-
Return to the cluster details page, then click Restart,
then Confirm.
After you restart the cluster, you can run pipelines from a different version of Transformer.
Provisioned Cluster
You can configure a pipeline to run on a provisioned cluster. When provisioning a cluster, Transformer creates a new job cluster on the initial run of a pipeline.
You can provision a cluster that uses an instance pool. You can configure the cluster to execute cluster-scoped init scripts before processing data. You can optionally have Transformer terminate the cluster after the pipeline stops.
To provision a cluster for the pipeline, use the Provision a New Cluster property on the Cluster tab of the pipeline properties. Then, define the cluster configuration to use.
Cluster-Scoped Init Scripts
When you provision a Databricks cluster, you can specify cluster-scoped init scripts to execute before processing data. You might use init scripts to perform tasks such as installing a driver on the cluster or creating directories and setting permissions for them.
- DBFS from Pipeline - Databricks File System (DBFS) init script defined in the pipeline. When provisioning the cluster, Transformer temporarily stores the script in DBFS and removes it after the pipeline run.
- DBFS from Location - Databricks File System init script stored on Databricks.
- S3 from Location - Amazon S3 init script stored on AWS. Use only when provisioning a Databricks cluster on AWS.
- ABFSS from Location - Azure init script stored on Azure Blob File System (ABFS).
Use only when provisioning a Databricks cluster on Azure.Note: To use this option, you must provide an access key to access the init script.
When you specify more than one init script, place them in the order that you want them to run. If a script fails to run, Transformer cancels the cluster provisioning and stops the job.
You can use any valid Databricks cluster-scoped init script. For more information about Databricks cluster-based init scripts, see the Databricks documentation.
Configure cluster-scoped init script properties on the Cluster tab of the pipeline properties. After you select the Provision a New Cluster property, you can configure the init script properties.
Access Keys for ABFSS Init Scripts
To use Azure cluster-scoped init scripts stored on Azure Blob File System, you must provide an ADLS Gen2 access key for the storage account where the scripts are located. When using init scripts stored in different storage accounts, provide an access key for each storage account.
- On the Cluster tab of the pipeline properties, in the Extra Spark Configuration
property, add the following property:
spark.hadoop.fs.azure.account.key.<storage-account-name>.dfs.core.windows.net<storage-account-name>is the name of the Azure Data Lake Storage Gen2 storage account where the script is located. - Set the value of the property to the access key to the Azure Data Lake Storage
Gen2 storage account.
For steps on finding the access key for your storage account, see Get an Azure ADLS Access Key in the Azure Databricks documentation.
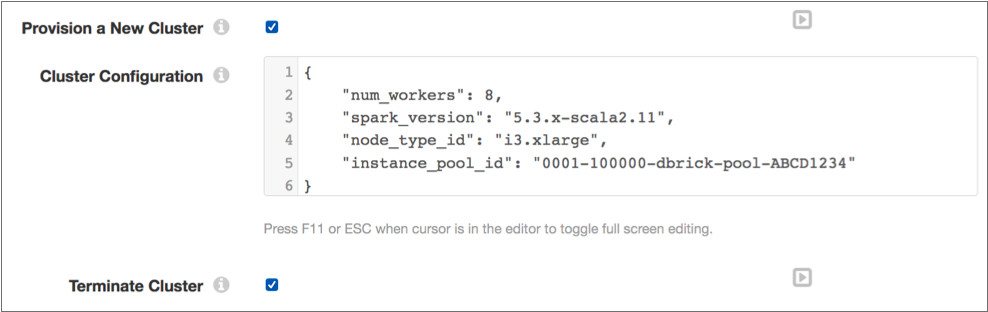
Cluster Configuration
When provisioning a cluster for a pipeline, Databricks creates a new Databricks job cluster upon the initial run of a pipeline. You define the Databricks cluster properties to use in the Cluster Configuration pipeline property. Transformer uses Databricks default values for all Databricks cluster properties that are not defined in the Cluster Configuration pipeline property.
When needed, you can override the Databricks default values by defining additional
cluster properties in the Cluster Configuration pipeline property. For example, to
provision a cluster that uses an instance pool, you can add and define the
instance_pool_id property in the Cluster Configuration property.
When defining cluster configuration properties, use the property names and values as expected by Databricks. The Cluster Configuration property defines cluster properties in JSON format.
| Databricks Cluster Property | Description |
|---|---|
| num_workers | Number of worker nodes in the cluster. |
| spark_version | Databricks Runtime and Apache Spark version. |
| node_type_id | Type of worker node. |
For information about other Databricks cluster properties, see the Databricks documentation.
Using an Instance Pool
When you configure the pipeline to provision a new Databricks cluster, you can have the provisioned cluster use an existing instance pool.
To have the provisioned cluster use an
instance pool, include the Databricks instance_pool_id property in the
Cluster Configuration pipeline property, and set it to the instance pool ID that you
want to use.
For example, the following set of properties provisions a cluster to run the pipeline that uses the specified instance pool, then terminates the cluster after the pipeline stops:
Locating Properties in Databricks
To locate the valid cluster configuration property names and values, launch your Databricks workspace and view the properties used to create a job cluster.
- In the side bar of the Databricks Workspace, click the Jobs icon and then click Create Job.
-
In the job details page, click Edit next to the cluster
specifications:

-
In the Configure Cluster page, select the desired values,
and then click JSON to view the specifications in JSON
format.
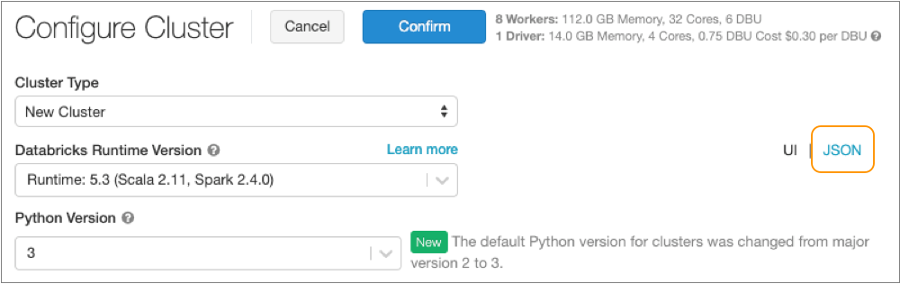
The following image displays a sample cluster configuration in JSON format:
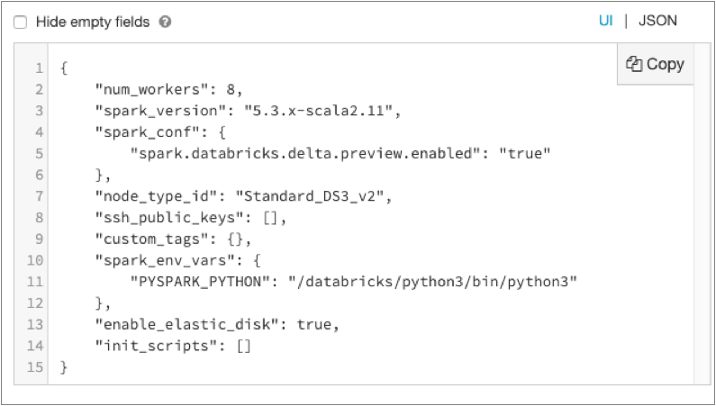
Use the property names and values displayed in the JSON page to define the cluster configuration properties and values for a Transformer pipeline. You can add all properties except for
init_scriptsto a pipeline cluster configuration.For example, the following image displays the Cluster Configuration property for a Transformer pipeline. The property contains the entire JSON for the job cluster, with the
init_scriptsproperty removed: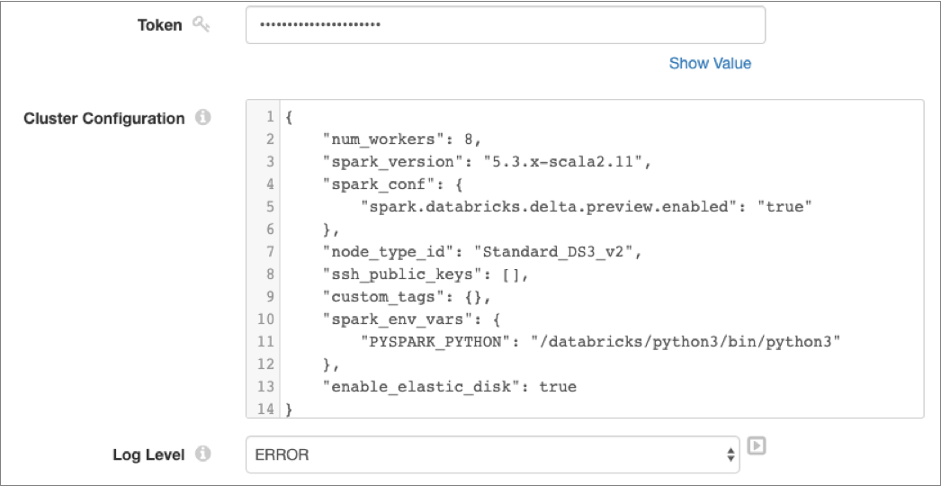
Staging Directory
To run pipelines on a Databricks cluster, Transformer must store files in a staging directory on Databricks File System (DBFS).
You can configure the root directory to use as the staging directory. The default staging directory is /streamsets.
When a pipeline runs on an existing interactive cluster, configure pipelines to use the same staging directory so that each job created within Databricks can reuse the common files stored in the directory. Pipelines that run on different clusters can use the same staging directory as long as the pipelines are started by the same Transformer instance. Pipelines that are started by different instances of Transformer must use different staging directories. Different Transformer instances cannot send pipelines to the same cluster.
When a pipeline runs on a provisioned job cluster, using the same staging directory for pipelines is best practice, but not required.
- Files that can be reused across pipelines
- Transformer stores files that can be reused across pipelines, including Transformer libraries and external resources such as JDBC drivers, in the following location:
- Files specific to each pipeline
- Transformer stores files specific to each pipeline, such as the pipeline JSON file and resource files used by the pipeline, in the following directory:
Caching Runtime Resource Files
You can configure Transformer to cache runtime resource files for reuse. Runtime resources are values that you define in an external file and call from within a pipeline, such as connection information for a JDBC driver.
By default, Transformer uploads runtime resource files to the following location for each pipeline run: /<staging_directory>/staging/<pipelineId>/<runId>. After a pipeline run completes, Transformer removes the files from the directory.
If your pipelines use only a few runtime resource files, the default behavior is appropriate. If your pipelines use large numbers of runtime resource files, then uploading and removing them for each pipeline run can be time consuming.
You can configure Transformer to cache runtime resource files so they can be reused by multiple pipelines and across multiple pipeline runs. When enabled, Transformer caches runtime resource files in the following location:
/<staging directory>/<engine ID>/externalResources
The first time that you run a pipeline with a large number of runtime resource files, the pipeline will take longer to initialize as it uploads those files to the directory.
To enable Transformer to cache runtime resource files for Databricks pipelines, uncomment the
transformer.databricks.external.resources.cache property in the Transformer configuration properties of the
deployment, and set the property to true.
Limiting Staging Directory Access
You can configure Transformer to temporarily lock the Databricks workspace to limit access to staging directories in the workspace by other Transformer engines. In most cases, limiting access to the Databricks workspace is not necessary.
Transformer accesses the staging directory defined in a pipeline each time a pipeline starts. Databricks can generate timeout errors when different Transformer engines try to access staging directories in the same Databricks workspace at the same time, and when those pipelines require uploading a large number of runtime resources files. Errors can also occur when the Databricks workspace is otherwise heavily loaded.
You might prevent this by staggering the start times of pipelines with large numbers of runtime resource files to upload, or by caching runtime resource files so Transformer does not need to upload the files with each pipeline run.
However, if Databricks timeout errors persist, you can address the issue by configuring Transformer to lock the Databricks workspace when a pipeline starts. Transformer releases the lock after submitting the Spark job for the pipeline.
-
In the Transformer configuration properties of the
deployment, uncomment and configure the following properties:
Transformer Configuration Property Description transformer.databricks.global.staging.lock.enabled Set to trueto enable locking the Databricks workspace so only one pipeline can start on the cluster at a time.Default is false.
transformer.databricks.global.staging.lock.directory Location to store temporary files that contain lock details. Default is /streamsets.
Do not specify a directory that is used by individual pipelines to upload resources, such as /streamsets/<transformer version> or /streamsets/staging/<pipelineId>/<runId>.
transformer.databricks.global.staging.lock.sync.time Milliseconds between lock updates. Default is 1000 milliseconds, or one second.
Adjust this value with care. Reducing this time can prevent locks from performing correctly. Dramatically increasing it can impact pipeline performance.
transformer.databricks.global.staging.lock.min.time Minimum amount of time to wait to acquire a lock, in milliseconds. Default is 3000 milliseconds, or three seconds.
transformer.databricks.global.staging.lock.max.time Maximum amount of time to wait to acquire a lock, in milliseconds. Default is 180000, or three minutes.
- When needed, perform the same step for any additional Transformer deployments that access the same Databricks workspace.
Retrying Pipelines
transformer.databricks.run.max.retries- Defines how many times Transformer retries a Databricks pipeline after it fails to start. Default is 2.transformer.databricks.run.retry.interval- Defines the number of milliseconds to wait between retries. Default is 10,000, which is 10 seconds.
When needed, you can configure these properties in the Transformer configuration properties of the deployment.
Accessing Databricks Job Details
When you run a Databricks pipeline, Transformer submits an ephemeral job to the Databricks cluster. An ephemeral job is one that runs only once and does not count towards the Databricks job limit. However, job details do not display in the Databricks job menu.
Databricks retains details for ephemeral jobs for 60 days. Use one of the following methods to access details about a Databricks job:
- After the job completes, on the History tab of the job, click View Summary for the job run. Use the Databricks Job URL link that displays in the Job Metrics Summary.
- Use the
jobs/runs/getDatabricks API to check the run state of the workloads.