SQL Parser
The SQL Parser parses a SQL query in a string field. When parsing a query, the processor generates fields based on the fields defined in the SQL query and specifies the CRUD operation, table, and schema information in record header attributes.
Use the processor to parse SQL queries written to a field when the Oracle CDC Client origin is configured to skip parsing. This avoids the possibility of redo logs switching before they can be processed. For more information, see Using Multiple Pipelines.
When you configure a SQL Parser, you define the field that contains the SQL query to parse and the target field where the processor adds the fields from the SQL query. The processor adds the fields to the target field as subfields.
You can specify that the processor connects to the database to resolve unknown field types. You can also use a connection to configure the processor.
As in the Oracle CDC Client origin, you can enable multithreaded parsing to improve performance. Note that enabling multithreaded parsing does not enable multithreaded batch processing – the pipeline uses a single thread.
If your database is case-sensitive, you can configure the processor to interpret case-sensitive schema, table, and column names.
The processor also includes CDC and CRUD information in record header attributes so records can be easily processed by CRUD-enabled destinations.
Using Multiple Pipelines
When a database contains very wide tables, the Oracle CDC Client origin requires more time to read the change data and to parse SQL queries due to the large amounts of information it now has to process. Note that reading the change data is bound by I/O constraints while parsing the SQL queries is bound by CPU constraints.
Redo logs can switch quite frequently. If it takes longer to read the change data and parse the SQL queries than it does for the redo logs to switch, data is lost.
One solution is to use the SQL Parser processor and multiple pipelines. The first pipeline contains the origin and an intermediate endpoint, like a local file system or Kafka. Configure the origin to not parse SQL queries by clearing the Parse SQL Query property. The second pipeline passes records from the intermediate endpoint to the SQL Parser processor to parse the SQL query and to update the fields.
The reason for multiple pipelines is that pipelines are synchronous by default. If the Oracle CDC Client origin and the SQL Parser processor are in the same pipeline, the origin reads data only after the pipeline completes processing the previous batch. This results in the same problem where redo logs can switch before the pipeline finishes processing the data.
Using an intermediate endpoint makes the pipeline asynchronous. Meaning, one pipeline can process a batch independent of the other. Using this approach, the origin can read the redo logs without waiting for the SQL Parser to finish and therefore no data is lost.
Example
You want to create two pipelines and use the SQL Parser to process the SQL queries instead of the Oracle CDC Client. The first pipeline contains the Oracle CDC Client and an intermediate endpoint, like Kafka. For example:
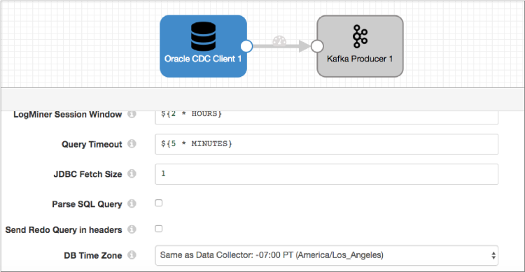
The second pipeline reads records from the intermediate endpoint and passes the records to the SQL Parser processor. The processor parses the SQL query located in the /sql field, and then the JDBC processor writes the data to the final destination.
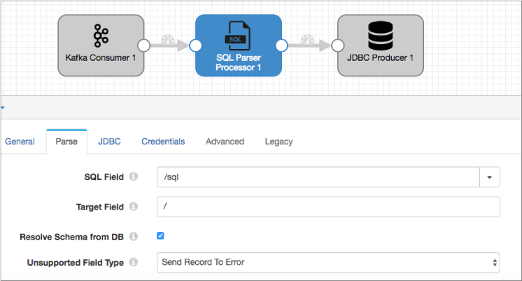
Resolving the Schema
For INSERT operations, you specify where the new fields are to be added as subfields. Use Resolve Schema from DB to resolve all field types. If you do not select this option, all fields are returned as strings in the form they are in the SQL query.
streamsets-datacollector-jdbc-lib, which includes the processor.To use the JDBC driver with multiple stage libraries, install the driver into each stage library associated with the stages.
For more information about installing additional drivers, see Install External Libraries.
Use Case Sensitive Names when your database contains case-sensitive schema, table, and column names. If you do not select this option, the SQL Parser processor submits names in all uppercase.
Unsupported Data Types
You can configure how the processor handles records that contain unsupported data types. The processor can perform the following actions:
- Pass the record to the pipeline without the unsupported data types.
- Pass the record to error without the unsupported data types.
- Discard the record.
You can configure the processor to include the unsupported data types in the record. When you include unsupported types, the processor includes the field names and passes the data as unparsed strings, when possible.
The SQL Parser does not support the same Oracle data types that the Oracle CDC Client does not support. For a complete list of unsupported data types, see Oracle CDC Client Unsupported Data Types.
Generated Records
The SQL Parser processor parses a SQL query in a field and creates fields based on the query. The processor adds the fields to the record as subfields of a target field, adding the subfields in the same order as the corresponding columns in the database tables.
The processor includes the CRUD operation type in the
sdc.operation.type record header attribute. This enables
CRUD-enabled destinations to determine the operation type to use when processing
records. The processor also generates field attributes for some columns that provide
additional information about the field.
/sql field as the field that contains the SQL query. The
/sql field contains the following SQL
query:INSERT INTO "sdc"."mc"("Part", "Cost") VALUES('levers', 250)| Field | Value |
|---|---|
| Part | levers |
| Cost | 250 |
- INSERT
- UPDATE
- DELETE
CRUD Operation Header Attributes
Like the Oracle CDC Client, the SQL Parser specifies the operation type in both of the following record header attributes:
- sdc.operation.type
- The SQL Parser evaluates the Oplog operation type associated with each entry
that it processes and, when appropriate, it writes the operation type to the
sdc.operation.typerecord header attribute. - oracle.cdc.operation
- The SQL Parser also writes the Oplog CRUD operation type to the
oracle.cdc.operationrecord header attribute.
For more information, see Oracle CDC Client CRUD Operation Header Attributes.
CDC Header Attributes
TABLE_NAMETABLE_SCHEM
The SQL Parser processor overwrites the sql.table header attribute if it
exists or creates it if it does not.
jdbc.<columnName>.precisionjdbc.<columnName>.scale
These are table column names, not field names. For example, if the column name is
part, then the headers are jdbc.part.precision and
jdbc.part.scale.
Other Header Attributes
The SQL Parser processor can also provide record header attributes about primary keys.
When a table contains a primary key, the processor indules the following record header attribute:
jdbc.primaryKeySpecification- Provides a JSON-formatted string that lists the columns that form the primary key in the table and the metadata for those columns.For example, a table with a composite primary key contains the following attribute:jdbc.primaryKeySpecification = {{"<primary key column 1 name>": {"type": <type>, "datatype": "<data type>", "size": <size>, "precision": <precision>, "scale": <scale>, "signed": <Boolean>, "currency": <Boolean> }}, ..., {"<primary key column N name>": {"type": <type>, "datatype": "<data type>", "size": <size>, "precision": <precision>, "scale": <scale>, "signed": <Boolean>, "currency": <Boolean> } } }A table without a primary key contains the attribute with an empty value:jdbc.primaryKeySpecification = {}
For an update operation on a table with a primary key, the processor includes the following record header attributes:
jdbc.primaryKey.before.<primary key column name>- Provides the old value for the specified primary key column.jdbc.primaryKey.after.<primary key column name>- Provides the new value for the specified primary key column.
Field Attributes
The SQL Parser processor generates field attributes for columns converted to the Decimal or Datetime data types in Data Collector. The attributes provide additional information about each field.
- The Oracle Number data type is converted to the Data Collector Decimal data type, which does not store scale and precision.
- The Oracle Timestamp data type is converted to the Data Collector Datetime data type, which does not store nanoseconds.
| Data Collector Data Type | Generated Field Attribute | Description |
|---|---|---|
| Decimal | precision | Provides the original precision for every number column. |
| Decimal | scale | Provides the original scale for every number column. |
| Datetime | nanoSeconds | Provides the original nanoseconds for every timestamp column. |
You can use the record:fieldAttribute or
record:fieldAttributeOrDefault functions to access the information
in the attributes. For more information about working with field attributes, see Field Attributes.
Configuring an SQL Parser Processor
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
-
On the Parse tab, configure the following
properties:
SQL Parser Property Description SQL Field Name of the field containing the SQL query. Target Field Field in which fields generated by the SQL query are added as subfields. You can specify an existing field or a new field as the target field. If you specify an existing field, the processor adds the fields from the SQL query as subfields, overwriting any content in the existing field. If you specify a new field, the processor creates the field and adds the fields from the SQL query as subfields.
The processor adds the subfields in the same order as the corresponding columns in the database tables.
Parsing Thread Pool Size Number of threads to use for parsing SQL statements in parallel.
Multithreaded parsing improves performance. Multithreaded parsing works the same as multithreaded parsing in the Oracle CDC Client origin. For details, see Multithreaded Parsing.
To balance performance and resource usage, set to twice the number of cores available in the machine hosting Data Collector
Set to 0 to use as many threads as there are available cores in the machine hosting Data Collector.
The default value is 1, which results in no multithreaded parsing.
Resolve Schema from DB Queries the database to resolve the schema and to resolve fields to their correct data type. If you do not select this option, all fields are returned as strings in the form they are in the SQL query.
When you select this option, you must install JDBC drivers for the database and configure the JDBC connection properties. For more information about installing additional drivers, see Install External Libraries.
Unsupported Field Type Determines the behavior when the processor encounters unsupported data types in the record: - Send Record to Pipeline - The processor ignores unsupported data types and passes the record with only supported data types to the pipeline.
- Send Record to Error - The processor handles the record based on the error record handling configured for the stage. The error record contains only the supported data types.
- Discard Record - The processor discards the record.
The SQL Parser processor does not support the same Oracle data types that the Oracle CDC Client origin does not support. For a list of unsupported data types, see Unsupported Data Types.
Add Unsupported Fields to Records Includes fields with unsupported data types in the record. Includes the field names and the unparsed string values of the unsupported fields, when possible.
Case Sensitive Names Enables using case-sensitive schema, table, and column names. When not enabled, the processor changes all names to uppercase. Date Format Format for date fields in the incoming SQL. Timestamp With Local Timezone Format Format for fields of type Timestamp with Local Timezone. Zoned DateTime Format Format for the date, datetime, or time data if they are using zoned datetime format.
For example, you can use yyyy-MM-dd'T'HH:mm:ssX[VV] for datetime values with a UTC offset and time zone. If the datetime value does not include a UTC offset, the stage uses the minimum offset for the specified time stamp.
DB Time Zone Time zone of the database. Specify when the database operates in a different time zone from Data Collector. -
On the JDBC tab, configure the following properties when
the Resolve Schema from DB property is enabled on the
Parse tab.
JDBC Property Description Connection Connection that defines the information required to connect to an external system. To connect to an external system, you can select a connection that contains the details, or you can directly enter the details in the pipeline. When you select a connection, Control Hub hides other properties so that you cannot directly enter connection details in the pipeline.
To create a new connection, click the Add New Connection icon:
 . To view and edit the details of the
selected connection, click the Edit
Connection icon:
. To view and edit the details of the
selected connection, click the Edit
Connection icon:  .
.JDBC Connection String Connection string used to connect to the database. Use Credentials Enables entering credentials. Use when you do not include credentials in the JDBC connection string. Additional JDBC Configuration Properties Additional JDBC configuration properties to use. To add properties, click Add and define the JDBC property name and value. Use the property names and values as expected by JDBC.
-
If you configured the origin to enter JDBC credentials separately from the JDBC
connection string on the JDBC tab, then configure the
following properties on the Credentials tab:
Credentials Property Description Username User name for the JDBC connection. The user account must have the correct permissions or privileges in the database. Password Password for the account. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores.