HTTP Client
The HTTP Client processor sends requests to an HTTP resource URL and writes responses to records. For information about supported versions, see Supported Systems and Versions.
The newer Web Client processor provides much of the same functionality as the HTTP Client processor. It also provides functionality not available in the HTTP Client processor. For more information, see Comparing Web Client and HTTP Client Processors.
For each request, the processor writes data from the response to the specified output field. When the response contains multiple values, the processor can write either the first value, all values to a list in a single record, or all values to separate records.
You can use the HTTP Client processor to perform a range of standard requests or you can use an expression to determine the request for each record.
When you configure the HTTP Client, you define the resource URL, optional headers, and method to use. For some methods, you can specify the request body and default content type.
You can configure the actions to take based on the response status and configure pagination properties to enable processing large volumes of data from paginated APIs.
You can configure the processor to include response header fields in the record as a set of record header attributes or as a map in a record field. You can configure the processor to log request and response information. And you can write the resolved request URL to the Data Collector log.
You can also configure the timeout, request transfer encoding, and authentication type. You can optionally use an HTTP proxy and configure SSL/TLS properties.
You can also configure the processor to use the OAuth 2 protocol to connect to an HTTP service.
HTTP Method
- GET
- PUT
- POST
- DELETE
- HEAD
- PATCH
- Expression - An expression that evaluates to one of the other methods.
Expression Method
The Expression method allows you to write an expression that evaluates to a standard HTTP method. Use the Expression method to generate a workflow. For example, you can use an expression that performs a lookup (GET) or passes data to the server (PUT) based on the data in a field.
Headers
- Headers
- Additional Security Headers
You can define headers in either property. However, only additional security headers support using credential functions to retrieve sensitive information from supported credential stores.
If you define the same header in both properties, additional security headers take precedence.
Per-Status Actions
By default, the HTTP Client processor accepts only responses that include a 2xx success status code. When the response includes any other status code, such as a 4xx or 5xx status code, by default, the processor generates an error and handles the record based on the error record handling configured for the stage.
You can configure the processor to perform one of several actions when it encounters an unsuccessful status code, that is, any non-2xx status code.
- Retry with linear backoff
- Retry with exponential backoff
- Retry immediately
- Cause the stage to fail and stop the pipeline
- Generate errors
When defining the retry with linear or exponential backoff action, you also specify the backoff interval to wait in milliseconds. When defining any of the retry actions, you specify the maximum number of retries. If the stage receives a 2xx status code during a retry, then it processes the response. If the stage doesn't receive a 2xx status code after the maximum number of retries, then the stage enters its error handling routine.
You can add multiple status codes and configure a specific action for each code.
You can also configure the stage to generate records for all unsuccessful statuses that are not added to the Per-Status Actions list. You then specify the output field name that stores the error response body for those records.
For example, if the stage receives a 400 Bad Request code,
you want the pipeline to process the response body that contains the description of the
error. When configuring the stage, you do not add an action for the 400 status code
because you don't need the stage to retry the request. You select the Records for
Remaining Statuses property and then use the default value outErrorBody
as the name of the error response body field.
Pass Records after Retry or Timeout Failures
You can configure the HTTP Client processor to pass input records downstream when you configure per-status actions or timeout options.
For example, you might configure the processor to pass a record downstream after all timeout retries fail. Or, you might configure a per-status action to pass a record downstream after all retries fail after receiving a 503 Service Unavailable code.
- When you configure the Action for Status property or the Action for Timeout
property to one of the retry options.
When you enable the Pass Records property, the processor passes the input record downstream after it reaches the configured maximum number of retries.
- When you configure the Action for Status property or the Action for Timeout
property to Generate Errors.
When you enable the Pass Records property, the processor generates a stage error instead of an error record, and passes the input record downstream.
Record Header Attributes for Passed Records
When you pass an input record downstream using one of the Pass Records properties, the processor adds the following record header attributes to the record:
| Record Header Attribute | Description |
|---|---|
| httpClientError | Error message generated by the processor, such
as:
|
| httpClientStatus | Error status that triggers the record to be passed. This is the first HTTP status code that exceeds the defined number of retries. |
| httpClientLastAction | Per-status action or timeout action that the processor is
configured to perform:
|
| httpClientTimeoutType | Timeout type causing the record to be passed:
|
| httpClientRetries | Number of retries that were attempted for the error status in httpClientStatus. |
Pagination
The HTTP Client processor can use pagination to retrieve a large volume of data from a paginated API.
When configuring the HTTP Client processor to use pagination, use the pagination type supported by the API of the HTTP client. You will likely need to consult the documentation for the origin system API to determine the pagination type to use and the properties to set.
The HTTP Client processor supports the following common pagination types:
- Link in HTTP Header
- After processing the current page, uses the link in the HTTP header to access
the next page. The link in the header can be an absolute URL or a URL relative
to the resource URL configured for the stage. For example, let's say you
configure the following resource URL for the
stage:
https://myapp.com/api/objects?page=1 - Link in Response Field
- After processing the current page, uses the link in a field in the response body
to access the next page. The link in the response field can be an absolute URL
or a URL relative to the resource URL configured for the stage. For example,
let's say you configure the following resource URL for the
stage:
http://myapp.com/api/tickets.json?start_time=138301982 - By Page Number
- Begins processing with the specified initial page, and then requests the
following page. Use the
${startAt}variable in the resource URL as the value of the page number to request. - By Offset Number
- Begins processing with the specified initial offset, and then requests the
following offset. Use the
${startAt}variable in the resource URL as the value of the offset number to request.
For the link in response field pagination type, you must define a stop condition that determines when there are no more pages to process. For all other pagination types, the stage stops reading when it returns a page that does not contain any more records.
When you use any pagination type, you must specify a result field path and can choose whether to include all other fields in the record.
Page or Offset Number
When using page number or offset number pagination, the API of the HTTP client typically requires that you include a page or offset parameter at the end of the resource URL. The parameter determines the next page or offset of data to request.
The name of the parameter used by the API varies. For example, it
might be offset, page, start, or
since. Consult the documentation for the origin system API to
determine the name of the page or offset parameter.
The HTTP Client processor provides a ${startAt} variable that you can
use in the URL as the value of the page or offset. For example, your resource URL might
be any of the following:
http://webservice/object?limit=15&offset=${startAt}https://myapp.com/product?limit=5&since=${startAt}https://myotherapp.com/api/v1/products?page=${startAt}
When the pipeline starts, the HTTP Client stage uses the value
of the Initial Page/Offset property as the
${startAt} variable value. After the stage reads a page of results,
the stage increments the ${startAt} variable by one if using page
number pagination or by the number of records read from the page if using offset number
pagination.
https://myapp.com/product?limit=5&since=${startAt}https://myapp.com/product?limit=5&since=0${startAt} variable by 5, such that the next resource URL is
resolved to:https://myapp.com/product?limit=5&since=5The second page of results also includes 5 items, starting at the 5th item.
Result Field Path
When using any pagination type, you must specify the result field path. The result field path is the location in the response that contains the data that you want to process.
The result field path must be a list or array.
{
"count":"1023",
"startAt":"2",
"maxResults":"2",
"total":"6",
"results":[
{
"firstName":"Joe",
"lastName":"Smith",
"phone":"555-555-5555"
},
{
"firstName":"Jimmy",
"lastName":"Smott",
"phone":"333-333-3333"
},
{
"firstName":"Joanne",
"lastName":"Smythe",
"phone":"777-777-7777"
}
]
}The processor creates records from the result field path based on how you configure the Multiple Values Behavior property on the HTTP tab:
- First value only
- When configured to write the first value only, the processor creates the
following single record from this sample
data:
{ "firstName":"Joe", "lastName":"Smith", "phone":"555-555-5555" } - All values as a list
- When configured to write all values to a list in a single record, the
processor creates the following single record from this sample
data:
[ { "firstName":"Joe", "lastName":"Smith", "phone":"555-555-5555" }, { "firstName":"Jimmy", "lastName":"Smott", "phone":"333-333-3333" }, { "firstName":"Joanne", "lastName":"Smythe", "phone":"777-777-7777" } ] - Split into multiple records
- When configured to write all values, each to a separate record, the processor creates three records from this sample data:
Keep All Fields
When using any pagination type, you can configure the processor to keep all fields in addition to those in the specified result field path. The resulting record includes all fields in the original structure and the result field path that includes the data.
By default, the processor returns only the data within the specified result field path.
For example, say we use the same sample data as above, with /results for the result field path. And we configure the processor to keep all fields. The processor creates records from the result field path based on how you configure the Multiple Values Behavior property on the HTTP tab:
- First value only
- When configured to write the first value only, the processor creates the
following single record that keeps the existing record structure and the
first set of data in the /results
field:
{ "count":"1023", "startAt":"2", "maxResults":"2", "total":"6", "results":{ "firstName":"Joe", "lastName":"Smith", "phone":"555-555-5555" } } - All values as a list
- When configured to write all values to a list in a single record, the
processor creates the following single record that keeps the existing record
structure with each set of data in the /results field:
[ { "count":"1023", "startAt":"2", "maxResults":"2", "total":"6", "results":{ "firstName":"Joe", "lastName":"Smith", "phone":"555-555-5555" } }, { "count":"1023", "startAt":"2", "maxResults":"2", "total":"6", "results":{ "firstName":"Jimmy", "lastName":"Smott", "phone":"333-333-3333" } }, { "count":"1023", "startAt":"2", "maxResults":"2", "total":"6", "results":{ "firstName":"Joanne", "lastName":"Smythe", "phone":"777-777-7777" } } ] - Split into multiple records
- When configured to write all values, each to a separate record, the processor generates three records that keep the existing record structure, and includes one set of data in the /results field:
Pagination Examples
Let's look at some examples of how you might configure the supported pagination types.
Example for Link in HTTP Header
link:<https://myapp.com/api/objects?page=2>; rel="next",
<https://myapp.com/api/objects?page=9>; rel="last"So after the HTTP Client processor reads the first page of results, it can use the next link in the HTTP header to read the next page.
https://myapp.com/api/objects?page=1Then, you set the Multiple Values Behavior property to write all values to a list in a single record or all values to separate records.
{
"total":"2000",
"limit":"10",
"results":[
{
"firstName":"Joe",
"lastName":"Smith"
},
...
{
"firstName":"Joanne",
"lastName":"Smythe"
}
]
}On the Pagination tab of the
stage, you simply set Pagination Mode to link in HTTP header, and
then you set the result field path to the /results field:
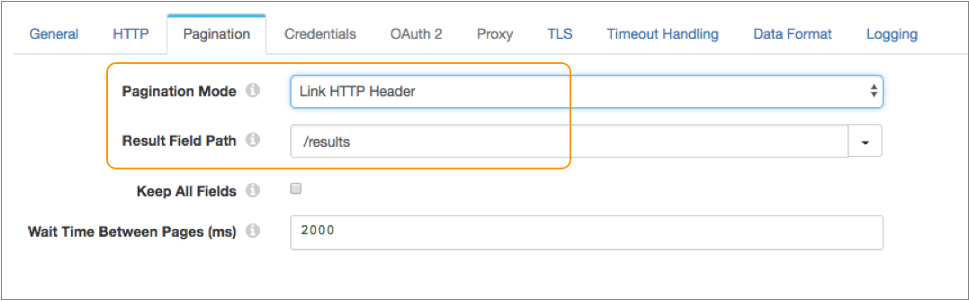
Example for Link in Response Field
The API of the HTTP client uses a field in the response body to access the next page. It requires that you include a timestamp in the resource URL indicating which items you want to start reading.
http://myapp.com/api/tickets.json?start_time=138301982Then, you set the Multiple Values Behavior property to write all values to a list in a single record or all values to separate records.
{
"ticket_events":[
{
"ticket_id":27,
"timestamp":138561439,
"via":"Email"
},
...
{
"ticket_id":30,
"timestamp":138561445,
"via":"Phone"
}
]
"next_page":"http://myapp.com/api/tickets.json?start_time=1389078385",
"count":1000,
"end_time":1389078385
}On the Pagination tab of
the stage, you set Pagination Mode to link in response field, and
set the next page link field to the /next_page field.
${record:value('/count') < 1000}Then you set the result field path to the
/ticket_events field:
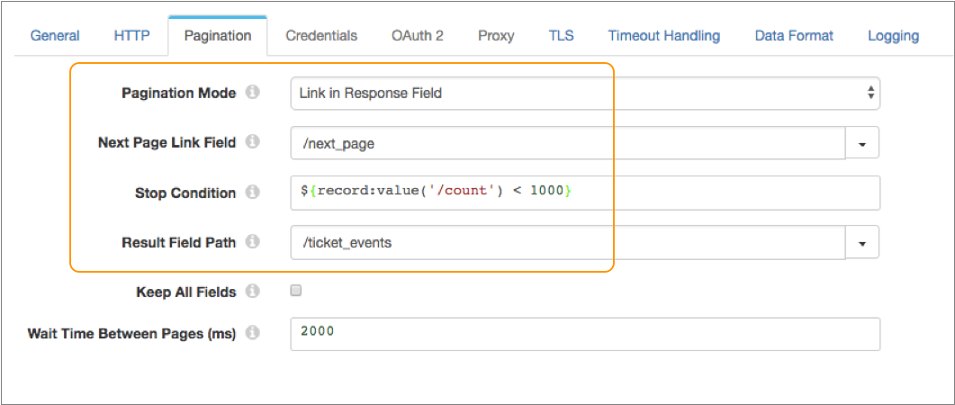
Example for Page Number
The API of the HTTP client uses page number pagination. It requires that you include a page parameter in the URL that specifies the page number to return from the results.
${startAt}
variable:https://myotherapp.com/api/v1/products?page=${startAt}Then, you set the Multiple Values Behavior property to write all values to a list in a single record or all values to separate records.
{
"total":"2000",
"items":[
{
"item":"pencil",
"cost":"2.00"
},
...
{
"item":"eraser",
"cost":"1.10"
}
]
}On the Pagination tab of the
stage, you set Pagination Mode to by page number. You want to
begin processing from the first page in the results, so you set the initial page to 0.
Then you set the result field path to the /items field:
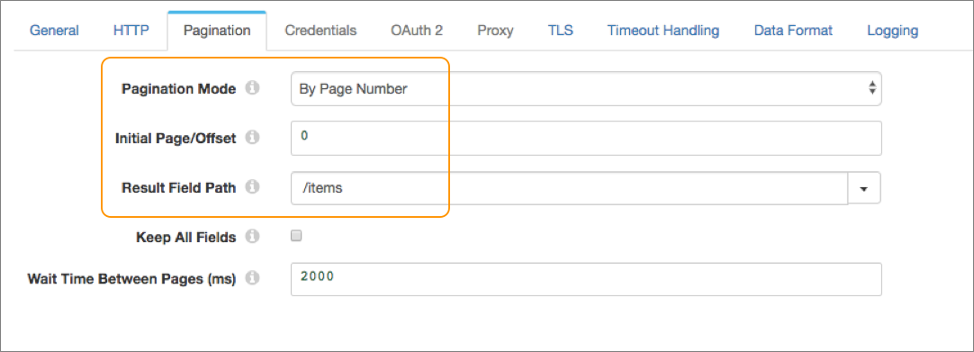
Example for Offset Number
limit- Specifies the number of results per page.offset- Specifies the offset value.
${startAt}
variable:https://myapp.com/product?limit=10&offset=${startAt}Then, you set the Multiple Values Behavior property to write all values to a list in a single record or all values to separate records.
{
"total":"2000",
"limit":"10",
"results":[
{
"firstName":"Joe",
"lastName":"Smith"
},
...
{
"firstName":"Joanne",
"lastName":"Smythe"
}
]
}On the Pagination tab of the
stage, you set Pagination Mode to by offset number. You want to
begin processing from the first item in the results, so you set the initial offset to 0.
Then you set the result field path to the /results field:
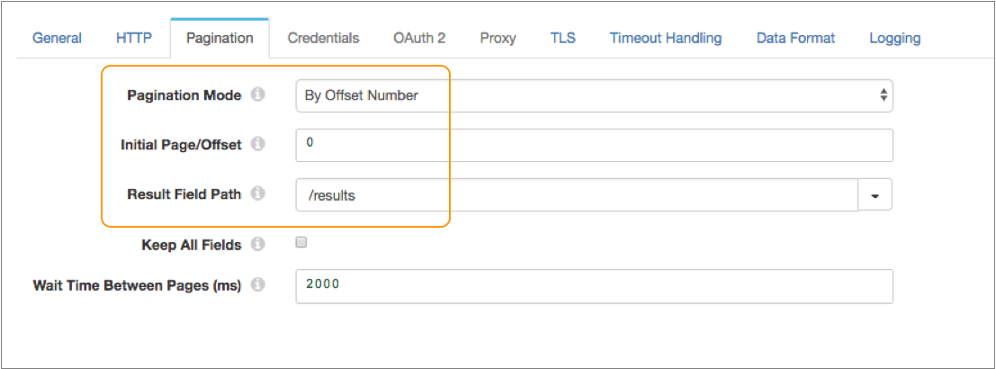
OAuth 2 Authorization
You can configure the HTTP Client processor to use the OAuth 2 protocol to connect to an HTTP service that uses basic, digest, or universal authentication, OAuth 2 client credentials, OAuth 2 username and password, or OAuth 2 JSON Web Tokens (JWT).
The OAuth 2 protocol authorizes third-party access to HTTP service resources without sharing credentials. The HTTP Client processor uses credentials to request an access token from the service. The service returns the token to the processor, and then the processor includes the token in a header in each request to the resource URL.
- Client credentials grant
-
HTTP Client sends its own credentials - the client ID and client secret or the basic, digest, or universal authentication credentials - to the HTTP service. For example, use the client credentials grant to process data from the Twitter API or from the Microsoft Azure Active Directory (Azure AD) API.
For more information about the client credentials grant, see https://tools.ietf.org/html/rfc6749#section-4.4.
- Resource owner password credentials grant
-
HTTP Client sends the credentials for the resource owner - the resource owner username and password - to the HTTP service. Or, you can use this grant type to migrate existing clients using basic, digest, or universal authentication to OAuth 2 by converting the stored credentials to an access token.
For example, use this grant to process data from the Getty Images API. For more information about using OAuth 2 to connect to the Getty Images API, see http://developers.gettyimages.com/api/docs/v3/oauth2.html.
For more information about the resource owner password credentials grant, see https://tools.ietf.org/html/rfc6749#section-4.3.
- JSON Web Tokens
-
HTTP Client sends a JSON Web Token (JWT) to an authorization service and obtains an access token for the HTTP service. For example, use JSON Web Tokens to process data with the Google API.
Let’s look at some examples of how to configure authentication and OAuth 2 authorization to process data from Twitter, Microsoft Azure AD, and Google APIs.
Example for Twitter
To use OAuth 2 authorization to read from Twitter, configure HTTP Client to use basic authentication and the client credentials grant.
For more information about configuring OAuth 2 authorization for Twitter, see https://developer.twitter.com/en/docs/authentication/oauth-2-0/application-only.
- On the HTTP tab, set Authentication Type to Basic, and then select Use OAuth 2.
-
On the Credentials tab, enter the Twitter consumer API
key and consumer API secret key for the Username and
Password properties.
Tip: To secure sensitive information such as the consumer API keys, you can use runtime resources or credential stores.
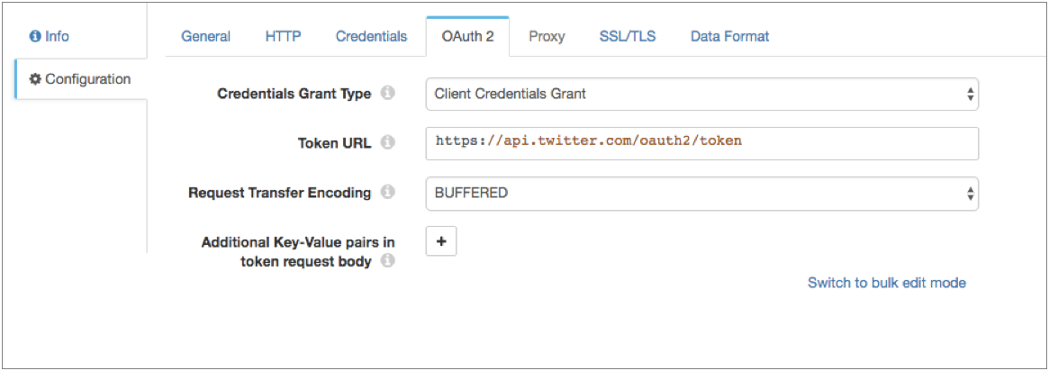
- On the OAuth 2 tab, select Client Credentials Grant for the grant type.
-
In the Token URL property, enter the following URL used
to request the access token:
https://api.twitter.com/oauth2/token
Example for Microsoft Azure AD
To use OAuth 2 authorization to read from Microsoft Azure AD, configure HTTP Client to use no authentication and the client credentials grant.
For more information about configuring OAuth 2 authorization for Microsoft Azure AD, see https://docs.microsoft.com/en-us/azure/active-directory/develop/active-directory-protocols-oauth-code.
- On the HTTP tab, set Authentication Type to None, and then select Use OAuth 2.
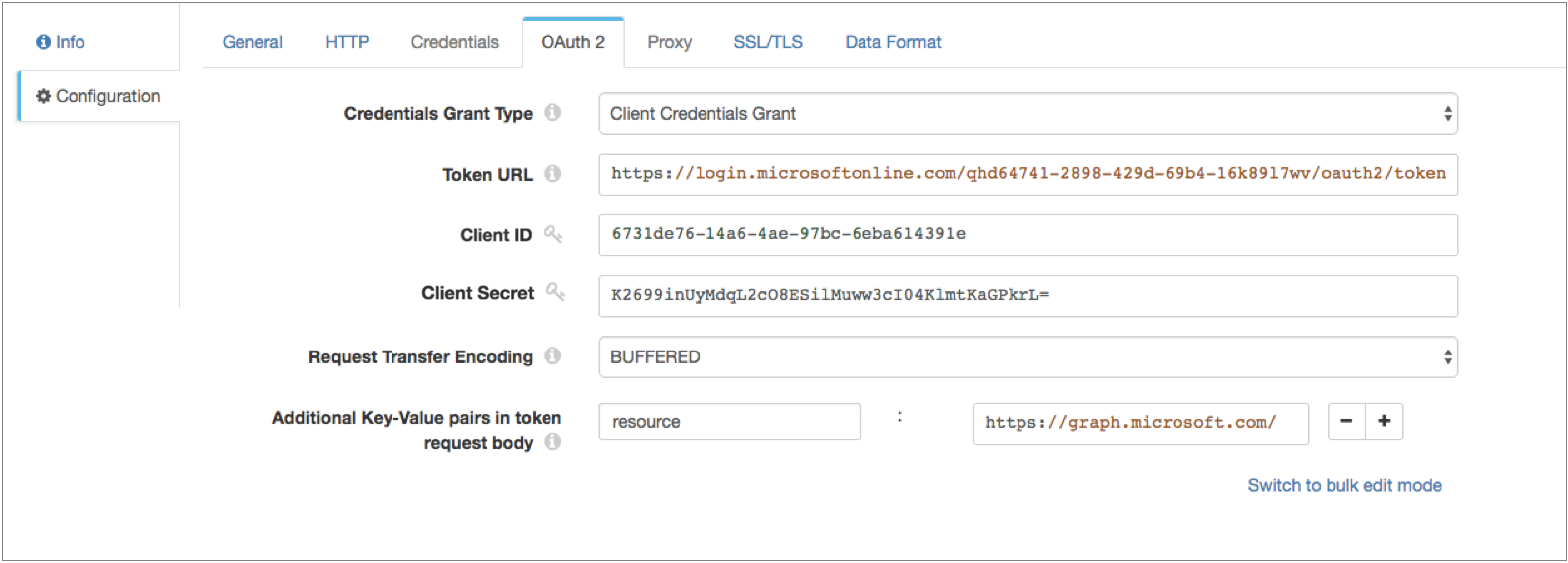
- On the OAuth 2 tab, select Client Credentials Grant for the grant type.
-
In the Token URL property, enter the following URL used
to request the access token:
https://login.microsoftonline.com/<tenant identifier>/oauth2/tokenWhere
<tenant identifier>is the Azure AD tenant identifier. -
Enter the OAuth 2 client ID and secret.
The client ID is the Application Id assigned to your app when you registered it with Azure AD, found in the Azure Classic Portal.
The client secret is the application secret that you created in the app registration portal for your app.
Tip: To secure sensitive information such as the client ID and secret, you can use runtime resources or credential stores. -
Add any key-value pairs that the HTTP service requires in the token
request.
In our example, we are accessing the
graph.microsoft.comAPI in our resource URL, so we need to add the following key-value pair:resource : https://graph.microsoft.com/
Example for Google
Configure the HTTP Client processor to use OAuth 2 authorization to read from Google service accounts. The stage sends a JSON Web Token in a request to the Google Authorization Server and obtains an access token for calls to the Google API.
Before you configure the stage, create a service account and delegate domain-wide authority to the service account. For details, see the Google Identity documentation: Using OAuth 2.0 for Server to Server Applications.
For more information about Google service accounts, see the Google Cloud documentation: Understanding service accounts.
For more information about configuring OAuth 2 authorization for Google, see the Google Identity documentation: Using OAuth 2.0 to Access Google APIs.
- On the HTTP tab, set Authentication Type to None, and then select Use OAuth 2.
- On the OAuth 2 tab, select JSON Web Tokens for the grant type.
-
In the Token URL property, enter the following URL used
to request the access token:
https://oauth2.googleapis.com/token - For JWT Signing Algorithm, select RSASSA-PKCS-v1_5 using SHA-256.
-
In the JWT Signing Key property, enter the private key
that the algorithm uses to compute the JWT signature and then encodes in Base64.
To access the key, download the JSON key file when you generate the Google credentials. Locate the "private_key" field in the file, which contains a string version of the key. Copy the string into the JWT Signing Key property, and then replace all "\n" literals with new lines.
For example, your key might look like:-----BEGIN PRIVATE KEY----- MIIEvgIBADANBgkqhkiG9..... -----END PRIVATE KEY-----Tip: To secure sensitive information such as the JWT signing key, you can use runtime resources or credential stores. -
In the JWT Headers property, enter the headers required
in the JWT, specified in JSON format.
The headers require information about the key and algorithm. For example, enter the headers in the following JSON format:
{ "alg":"RS256”, "typ":”JWT" } -
In the JWT Claims property, enter the claims required in
the JWT token, specified in JSON format.
For information about claim requirements when calling a Google API, see the Google Identity documentation: Preparing to make an authorized API call.
For a list of scopes for the scope claim, see the Google Identity documentation: OAuth 2.0 Scopes for Google APIs.
For example, enter the claims in the following JSON format:{ "iss":"my_name@my_account.iam.gserviceaccount.com", "scope":"https://www.googleapis.com/auth/drive", "aud":"https://oauth2.googleapis.com/token", "exp":${(time:dateTimeToMilliseconds(time:now())/1000) + 50 * MINUTES}, "iat":${time:dateTimeToMilliseconds(time:now())/1000} }You can include the expression language in the JWT claims. For example, in the sample claim above, both the "exp" (expiration time) claim and the "iat" (issued at) claim include Data Collector time functions to set the expiration time and the issue time.
Tip: Google access tokens expire after 60 minutes. As a result, set the expiration time claim to be slightly less than 60 minutes so that HTTP Client can request a new token within the time limit. -
In Additional Key-Value Pairs in Token Request Body, add
a key with the name grant_type and the value
urn:ietf:params:oauth:grant-type:jwt-bearer.
This configuration defines the
grant_typeparameter that the Google Authorization Server requires for token requests. -
Keep the Use Custom Assertion check box clear so that
the stage writes the JWT in the
assertionparameter, as required by the Google Authorization Server.
Generated Output
For each request that returns a 2xx success status code, the HTTP Client processor writes the response to the specified output field. The processor parses data in the response body into values based on the selected data format. You configure how the processor writes multiple values. The processor can write either the first value to a single record, all values to a list in a single record, or all values to separate records.
When you configure the processor to generate records for unsuccessful statuses that are not added to the Per-Status Actions list, then the HTTP Client processor might also write an error response body to the specified error response body field.
For HEAD responses, the response body contains no data. Therefore, the processor writes output only to record header attributes, leaving the output field empty.
Response Headers
- Record header attributes
- The processor writes data in response headers to corresponding record header attributes.
- Record field
- The processor can also write the response headers to a field in the record. The processor writes the response headers to the record field as a map of key-value pairs where the key is the response header name.
Logging Request and Response Data
The HTTP Client processor can log request and response data to the Data Collector log.
When enabling logging, you configure the following properties:
- Verbosity
-
The type of data to include in logged messages:
- Headers_Only - Includes request and response headers.
- Payload_Text - Includes request and response headers as well as any text payloads.
- Payload_Any - Includes request and response headers and the payload, regardless of type.
- Log Level
- The level of messages to include in the Data Collector log. When you select a level, higher level messages are also logged. That is, if you select the Warning log level, then Severe and Warning messages are written to the Data Collector log.
- Max entity size
-
The maximum size of message data to write to the log. Use to limit the volume of data written to the Data Collector log for any single message.
Logging the Resolved Resource URL
You can write the resolved resource URL to the Data Collector log.
The resolved resource URL is the URL that is defined in the Resource URL property after resolving any expressions included in the URL.
https://api.twitter.com/1.1/search/tweets.json?q=${record:value('/text')}%23DataOps in the /text field, then the resolved URL
is:https://api.twitter.com/1.1/search/tweets.json?q=%23DataOpsTo write the resolved resource URL to the Data Collector log, set the Data Collector log level to DEBUG or higher. You do not need to use the Enable Request Logging property in the processor to log the resolved resource URL.
Data Formats
The HTTP Client processor parses each server response based on the selected data format and writes the response to the specified output field in the selected format.
You configure how the processor writes parsed responses that contain multiple values. The processor can write either the first value to a single record, all values to a list in a single record, or all values to separate records.
- Delimited
- The processor parses each line in the response as a value, and either writes only the first delimited line to a single record, writes all delimited lines to a single record with each line written to a list item, or writes each delimited line to separate records.
- JSON
- The processor parses each object in the response into a value, and either writes only the first object to a single record, writes all objects to a list in a single record, or writes each object to separate records.
- Text
- If you specify a custom delimiter, the processor parses the data into values based on the delimiter. Otherwise, the processor parses each line into a value. Then, the processor either writes only the first value to a single record, writes all values to a list in a single record, or writes each value to separate records.
- XML
- If you specify a delimiter element, the processor uses the delimiter element to parse the response into values. The processor either writes only the first delimited element to a single record, writes all delimited elements to a list in a single record, or writes each delimited element to separate records.
Configuring an HTTP Client Processor
Configure an HTTP Client processor to perform requests against a resource URL.
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
-
On the HTTP tab, configure the following properties:
HTTP Property Description Resource URL HTTP resource URL. Output Field Field to use for the response. You can use a new or existing field. Multiple Values Behavior Action to take when responses contain multiple values: - First value only - Write the first value.
- All values as a list - Write all values to a list in a single record.
- Split into multiple records - Write all values, each to a separate record.
When the processor uses pagination, set to All values as a list or Split into multiple records.
Headers Headers to include in the request. Using simple or bulk edit mode, click Add to add additional headers. Additional Security Headers Security headers to include in the request. Using simple or bulk edit mode, click Add to add additional security headers. You can use credential functions to retrieve sensitive information from supported credential stores.
Note: If you define the same header in the Headers property, additional security headers take precedence.HTTP Method HTTP request method. Use one of the standard methods or use Expression to enter an expression. HTTP Method Expression Expression that evaluates to a standard HTTP method. Used for the Expression method only.
Request Data Request data to use with the specified method. Available for the PUT, POST, DELETE, PATCH, and Expression methods. Default Request Content Type Content-Type header to include in the request. Used only when the Content-Type header is not present. Available for the PUT, POST, DELETE, PATCH, and Expression methods.
Default is application/json.
Authentication Type Determines the authentication type used to connect to the server: - None - Performs no authentication.
- Basic - Uses basic authentication. Requires a username and password.
Use with HTTPS to avoid passing unencrypted credentials.
- Digest - Uses digest authentication. Requires a username and password.
- Universal - Makes an anonymous connection, then provides authentication
credentials upon receiving a 401 status and a WWW-Authenticate header request.
Requires a username and password associated with basic or digest authentication.
Use only with servers that respond to this workflow.
- OAuth - Uses OAuth 1.0 authentication. Requires OAuth credentials.
OAuth2 Enables using OAuth 2 authorization to request access tokens. You can use OAuth 2 authorization with none, basic, digest, or universal authentication.
Per-Status Actions Actions to take for specific response statuses that are not a 2xx success status code. For example, you can configure the stage to retry the request with an exponential backoff when it receives a 500 HTTP status code. Specify the HTTP status code, the action to take for the status, and related properties. Optionally enable the Pass Records property, which passes an input record downstream when the maximum number of retries are reached for a retry action.
When you enable the Pass Records property with the Generate Errors action, the processor passes the input record downstream and generates a stage error instead of passing an error record downstream.
Records for Remaining Statuses Generate records for all unsuccessful statuses that are not added to the Per-Status Actions list. Error Response Body Field Name of the field that stores the error response body for those records. Available when generating records for remaining statuses.
Header Output Location Location to write response header field information. Header Output Field Field to use when writing response header field information to a field in the record. Header Attribute Prefix Prefix to use when writing response header field information to record header attributes. Request Transfer Encoding Use one of the following encoding types: - Buffered - The standard transfer encoding type.
- Chunked - Transfers data in chunks. Not supported by all servers.
Default is Buffered.
Connect Timeout Maximum number of milliseconds to wait for a connection. Read Timeout Maximum number of milliseconds to wait for data. Use Proxy Enables using an HTTP proxy to connect to the system. Rate Limit Minimum amount of time between requests in milliseconds. Set a rate limit when sending requests to a rate-limited API. Default is 0, which means there is no delay between requests.
Maximum Request Time Maximum number of seconds to wait for a request to complete. Batch Wait Time (ms) Maximum number of milliseconds wait before sending a partial or empty batch. -
On the Pagination tab, optionally configure pagination
details.
Pagination Property Description Pagination Mode Method of pagination to use. Use a method supported by the API of the HTTP client. Initial Page/Offset Initial page for page number pagination, or the initial offset for offset number pagination. Next Page Link Field Field path in the response that contains the URL to the next page. For link in response field pagination.
Stop Condition Condition that evaluates to true when there are no more pages to process. For link in response field pagination.
For example, let's say that the API of the HTTP client includes a count property that determines the number of items displayed per page. If the count is set to 1000 and a page returns with less than 1000 items, it is the last page of data. So you'd enter the following expression to stop processing when the count is less than 1000:${record:value('/count') < 1000}Result Field Path Field path in the response that contains the data that you want to process. Must be a list or array field.
The processor generates records from the specified field based on the Multiple Values Behavior property on the HTTP tab.
Keep All Fields Includes all fields from the response in the resulting record when enabled. By default, only the fields in the specified result field path are included in the record.
Wait Time Between Pages (ms) The number of milliseconds to wait before requesting the next page of data. -
When using Basic authentication, on the Credentials tab,
configure the following properties:
Credentials Property Description Username User name for basic, digest, or universal authentication. Password Password for basic, digest, or universal authentication. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores. -
When using OAuth 2 authorization, on the OAuth 2 tab,
configure the following properties.
For more information about OAuth 2 and for example OAuth 2 configurations to read from Twitter, Microsoft Azure AD, or Google APIs, see OAuth 2 Authorization.
OAuth 2 Property Description Credentials Grant Type Type of client credentials grant type required by the HTTP service: - Client credentials grant
- Resource owner password credentials grant
- JSON Web Tokens
Token URL URL to request the access token. User Name Resource owner user name. Enter for the resource owner password credentials grant.
Password Resource owner password. Enter for the resource owner password credentials grant.
Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores.Client ID Client ID that the HTTP service uses to identify the HTTP client. Enter for the client credentials grant that uses a client ID and secret for authentication. Or, for the resource owner password credentials grant that requires a client ID and secret.
Client Secret Client secret that the HTTP service uses to authenticate the HTTP client. Enter for the client credentials grant that uses a client ID and secret for authentication. Or, for the resource owner password credentials grant that requires a client ID and secret.
Tip: To secure sensitive information such as the client ID and secret, you can use runtime resources or credential stores.JWT Signing Algorithm Algorithm used to sign the JSON Web Token (JWT). Default is none.
Enter for the JSON Web Tokens grant.
JWT Signing Key Private key that the selected signing algorithm uses to sign the JWT. Tip: To secure sensitive information such as the JWT signing key, you can use runtime resources or credential stores.Enter for the JSON Web Tokens grant.
JWT Headers Headers to include in the JWT. Specify in JSON format. Enter for the JSON Web Tokens grant.
JWT Claims Claims to include in the JWT. Specify in JSON format. Enter each claim required to obtain an access token. You can include the expression language in the JWT claims. For example, to request an access token to read from Google service accounts, enter the following claims with the appropriate values:
{ "iss":"my_name@my_account.iam.gserviceaccount.com", "scope":"https://www.googleapis.com/auth/drive", "aud":"https://oauth2.googleapis.com/token", "exp":${(time:dateTimeToMilliseconds(time:now())/1000) + 50 * 60}, "iat":${time:dateTimeToMilliseconds(time:now())/1000} }Enter for the JSON Web Tokens grant.
Request Transfer Encoding Form of encoding to use when the stage requests an access token: buffered or chunked. Default is chunked.
Additional Key-Value Pairs in Token Request Body Optional key-value pairs to send to the token URL when requesting an access token. For example, you can define the OAuth 2 scoperequest parameter.Using simple or bulk edit mode, click the Add icon to add additional key-value pairs.
Use Custom Assertion Writes the JWT in the parameter specified in Assertion Key Type. By default, the stage writes the JWT in the
assertionparameter.Available for the JSON Web Tokens grant.
Assertion Key Type Parameter where the stage writes the JWT. Default value is assertion.Available if Use Custom Assertion is selected.
-
To use an HTTP proxy, on the Proxy tab, configure the
following properties:
Proxy Property Description Proxy URI Proxy URI. Username Proxy user name. Password Proxy password. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores. -
To use SSL/TLS, on the TLS tab, configure the following
properties:
TLS Property Description Use TLS Enables the use of TLS. Use Remote Keystore Enables loading the contents of the keystore from a remote credential store or from values entered in the stage properties. For more information, see Remote Keystore and Truststore. Private Key Private key used in the remote keystore. Enter a credential function that returns the key or enter the contents of the key. Certificate Chain Each PEM certificate used in the remote keystore. Enter a credential function that returns the certificate or enter the contents of the certificate. Keystore File Path to the local keystore file. Enter an absolute path to the file or enter the following expression to define the file stored in the Data Collector resources directory:
${runtime:resourcesDirPath()}/keystore.jksBy default, no keystore is used.
Keystore Type Type of keystore to use. Use one of the following types: - Java Keystore File (JKS)
- PKCS #12 (p12 file)
Default is Java Keystore File (JKS).
Keystore Password Password to the keystore file. A password is optional, but recommended.
Tip: To secure sensitive information such as passwords, you can use runtime resources or credential stores.Keystore Key Algorithm Algorithm to manage the keystore.
Default is SunX509.
Use Remote Truststore Enables loading the contents of the truststore from a remote credential store or from values entered in the stage properties. For more information, see Remote Keystore and Truststore. Trusted Certificates Each PEM certificate used in the remote truststore. Enter a credential function that returns the certificate or enter the contents of the certificate. Using simple or bulk edit mode, click the Add icon to add additional certificates.
Truststore File Path to the local truststore file. Enter an absolute path to the file or enter the following expression to define the file stored in the Data Collector resources directory:
${runtime:resourcesDirPath()}/truststore.jksBy default, no truststore is used.
Truststore Type Type of truststore to use. Use one of the following types:- Java Keystore File (JKS)
- PKCS #12 (p12 file)
Default is Java Keystore File (JKS).
Truststore Password Password to the truststore file. A password is optional, but recommended.
Tip: To secure sensitive information such as passwords, you can use runtime resources or credential stores.Truststore Trust Algorithm Algorithm to manage the truststore.
Default is SunX509.
Use Default Protocols Uses the default TLSv1.2 transport layer security (TLS) protocol. To use a different protocol, clear this option. Transport Protocols TLS protocols to use. To use a protocol other than the default TLSv1.2, click the Add icon and enter the protocol name. You can use simple or bulk edit mode to add protocols. Note: Older protocols are not as secure as TLSv1.2.Use Default Cipher Suites Uses a default cipher suite for the SSL/TLS handshake. To use a different cipher suite, clear this option. Cipher Suites Cipher suites to use. To use a cipher suite that is not a part of the default set, click the Add icon and enter the name of the cipher suite. You can use simple or bulk edit mode to add cipher suites. Enter the Java Secure Socket Extension (JSSE) name for the additional cipher suites that you want to use.
-
On the Data Format tab, configure the following
property:
Data Format Property Description Data Format Data format of the response:- Delimited
- JSON
- Text
- XML
-
For delimited data, on the Data Format tab, configure the
following properties:
Delimited Property Description Header Line Indicates whether a file contains a header line, and whether to use the header line. Delimiter Format Type Delimiter format type. Use one of the following options: - Default CSV - File that includes comma-separated values. Ignores empty lines in the file.
- RFC4180 CSV - Comma-separated file that strictly follows RFC4180 guidelines.
- MS Excel CSV - Microsoft Excel comma-separated file.
- MySQL CSV - MySQL comma-separated file.
- Tab-Separated Values - File that includes tab-separated values.
- PostgreSQL CSV - PostgreSQL comma-separated file.
- PostgreSQL Text - PostgreSQL text file.
- Custom - File that uses user-defined delimiter, escape, and quote characters.
- Multi Character Delimited - File that uses multiple user-defined characters to delimit fields and lines, and single user-defined escape and quote characters.
Available when using the Apache Commons parser type.
Multi Character Field Delimiter Characters that delimit fields. Default is two pipe characters (||).
Available when using the Apache Commons parser with the multi-character delimiter format.
Multi Character Line Delimiter Characters that delimit lines or records. Default is the newline character (\n).
Available when using the Apache Commons parser with the multi-character delimiter format.
Delimiter Character Delimiter character. Select one of the available options or use Other to enter a custom character. You can enter a Unicode control character using the format \uNNNN, where N is a hexadecimal digit from the numbers 0-9 or the letters A-F. For example, enter \u0000 to use the null character as the delimiter or \u2028 to use a line separator as the delimiter.
Default is the pipe character ( | ).
Available when using the Apache Commons parser with a custom delimiter format.
Field Separator One or more characters to use as delimiter characters between columns. Available when using the Univocity parser.
Escape Character Escape character. Available when using the Apache Commons parser with the custom or multi-character delimiter format. Also available when using the Univocity parser.
Quote Character Quote character. Available when using the Apache Commons parser with the custom or multi-character delimiter format. Also available when using the Univocity parser.
Line Separator Line separator. Available when using the Univocity parser.
Allow Comments Allows commented data to be ignored for custom delimiter format. Available when using the Univocity parser.
Comment Character Character that marks a comment when comments are enabled for custom delimiter format.
Available when using the Univocity parser.
Enable Comments Allows commented data to be ignored for custom delimiter format. Available when using the Apache Commons parser.
Comment Marker Character that marks a comment when comments are enabled for custom delimiter format. Available when using the Apache Commons parser.
Lines to Skip Number of lines to skip before reading data. Compression Format The compression format of the files: - None - Processes only uncompressed files.
- Compressed File - Processes files compressed by the supported compression formats.
- Archive - Processes files archived by the supported archive formats.
- Compressed Archive - Processes files archived and compressed by the supported archive and compression formats.
File Name Pattern within Compressed Directory For archive and compressed archive files, file name pattern that represents the files to process within the compressed directory. You can use UNIX-style wildcards, such as an asterisk or question mark. For example, *.json. Default is *, which processes all files.
CSV Parser Parser to use to process delimited data: - Apache Commons - Provides robust parsing and a wide range of delimited format types.
- Univocity - Can provide faster processing for wide delimited files, such as those with over 200 columns.
Default is Apache Commons.
Max Columns Maximum number of columns to process per record. Available when using the Univocity parser.
Max Character per Column Maximum number of characters to process in each column. Available when using the Univocity parser.
Skip Empty Lines Allows skipping empty lines. Available when using the Univocity parser.
Allow Extra Columns Allows processing records with more columns than exist in the header line. Available when using the Apache Commons parser to process data with a header line.
Extra Column Prefix Prefix to use for any additional columns. Extra columns are named using the prefix and sequential increasing integers as follows: <prefix><integer>.For example,
_extra_1. Default is_extra_.Available when using the Apache Commons parser to process data with a header line while allowing extra columns.
Max Record Length (chars) Maximum length of a record in characters. Longer records are not read. This property can be limited by the Data Collector parser buffer size. For more information, see Maximum Record Size.
Available when using the Apache Commons parser.
Ignore Empty Lines Allows empty lines to be ignored. Available when using the Apache Commons parser with the custom delimiter format.
Root Field Type Root field type to use: - List-Map - Generates an indexed list of data. Enables you to use standard functions to process data. Use for new pipelines.
- List - Generates a record with an indexed list with a map for header and value. Requires the use of delimited data functions to process data. Use only to maintain pipelines created before 1.1.0.
Parse NULLs Replaces the specified string constant with null values. NULL Constant String constant to replace with null values. Charset Character encoding of the files to be processed. Ignore Control Characters Removes all ASCII control characters except for the tab, line feed, and carriage return characters. -
For JSON data, on the Data Format tab, configure the
following properties:
JSON Property Description Compression Format The compression format of the files: - None - Processes only uncompressed files.
- Compressed File - Processes files compressed by the supported compression formats.
- Archive - Processes files archived by the supported archive formats.
- Compressed Archive - Processes files archived and compressed by the supported archive and compression formats.
File Name Pattern within Compressed Directory For archive and compressed archive files, file name pattern that represents the files to process within the compressed directory. You can use UNIX-style wildcards, such as an asterisk or question mark. For example, *.json. Default is *, which processes all files.
Max Object Length (chars) Maximum number of characters in a JSON object. Longer objects are diverted to the pipeline for error handling.
This property can be limited by the Data Collector parser buffer size. For more information, see Maximum Record Size.
Charset Character encoding of the data to be processed. Ignore Control Characters Removes all ASCII control characters except for the tab, line feed, and carriage return characters. -
For text data, on the Data Format tab, configure the
following properties:
Text Property Description Compression Format The compression format of the files: - None - Processes only uncompressed files.
- Compressed File - Processes files compressed by the supported compression formats.
- Archive - Processes files archived by the supported archive formats.
- Compressed Archive - Processes files archived and compressed by the supported archive and compression formats.
File Name Pattern within Compressed Directory For archive and compressed archive files, file name pattern that represents the files to process within the compressed directory. You can use UNIX-style wildcards, such as an asterisk or question mark. For example, *.json. Default is *, which processes all files.
Max Line Length Maximum number of characters allowed for a line. Longer lines are truncated. Adds a boolean field to the record to indicate if it was truncated. The field name is Truncated.
This property can be limited by the Data Collector parser buffer size. For more information, see Maximum Record Size.
Use Custom Delimiter Uses custom delimiters to define records instead of line breaks. Custom Delimiter One or more characters to use to define records. Include Custom Delimiter Includes delimiter characters in the record. Charset Character encoding of the files to be processed. Ignore Control Characters Removes all ASCII control characters except for the tab, line feed, and carriage return characters. -
For XML data, on the Data Format tab, configure the
following properties:
XML Property Description Compression Format The compression format of the files: - None - Processes only uncompressed files.
- Compressed File - Processes files compressed by the supported compression formats.
- Archive - Processes files archived by the supported archive formats.
- Compressed Archive - Processes files archived and compressed by the supported archive and compression formats.
File Name Pattern within Compressed Directory For archive and compressed archive files, file name pattern that represents the files to process within the compressed directory. You can use UNIX-style wildcards, such as an asterisk or question mark. For example, *.json. Default is *, which processes all files.
Delimiter Element XML element that acts as a delimiter. Omit a delimiter to treat the entire XML document as one field.
Preserve Root Element Includes the root element in the generated records. When omitting a delimiter, the root element is the root element of the XML document. When specifying a delimiter, the root element is the XML element specified as the delimiter element.
Max Record Length (chars) The maximum number of characters in a field. Longer fields are diverted to the pipeline for error handling.
This property can be limited by the Data Collector parser buffer size. For more information, see Maximum Record Size.
Charset Character encoding of the files to be processed. Ignore Control Characters Removes all ASCII control characters except for the tab, line feed, and carriage return characters. -
On the Logging tab, configure the following properties to
log request and response data:
Logging Property Description Enable Request Logging Enables logging request and response data. For information about logging the resolved resource URL, see Logging the Resolved Resource URL.
Log Level The level of detail to be logged. Choose one of the available options. The following list is in order of lowest to highest level of logging. When you select a level, messages generated by the levels above the selected level are also written to the log:- Severe - Only messages indicating serious failures.
- Warning - Messages warning of potential problems.
- Info - Informational messages.
- Fine - Basic tracing information.
- Finer - Detailed tracing information.
- Finest - Highly detailed tracing information.
Note: The log level configured for Data Collector can limit the level of messages that the stage writes. Verify that the Data Collector log level supports the level that you want to use.Verbosity The type of data to include in logged messages:- Headers_Only - Includes request and response headers.
- Payload_Text - Includes request and response headers as well as any text payloads.
- Payload_Any - Includes request and response headers and the payload, regardless of type.
Max Entity Size The maximum size of message data to write to the log. Use to limit the volume of data written to the Data Collector log for any single message.
-
On the Timeout tab, configure the following
properties:
Timeout Property Description Action for Timeout Action to take when the request times out because the HTTP service did not respond within the read timeout period. Max Retries Maximum number of times to retry the request before failing the stage. A negative value allows an infinite number of retries. Default is 10.
Pass Records Passes an input record downstream when the maximum number of retries are reached for a retry action.
When you enable the Pass Records property with the Generate Errors action, the processor passes the input record downstream and generates a stage error instead of passing an error record downstream.