Groovy Evaluator
The Groovy Evaluator processor uses Groovy code to process data. Use the Groovy Evaluator processor to use Groovy code to perform custom processing. The Groovy Evaluator supports Groovy versions 2.4 and 4.0. Be sure to install the correct stage library for your version of Groovy.
- Initialization script - Optional initialization script that sets up any required resources or connections. The initialization script is run once when the pipeline starts.
- Main processing script - Main script that processes data. The main script is run for each record or each batch of data, based on the configured processing mode.
- Destroy script - Optional destroy script that closes any resources or connections that were opened by the processor. The destroy script is run once when the pipeline stops.
When you use a Groovy Evaluator processor in a pipeline, Data Collector passes a batch of data to the processor and converts the data to a scripting-friendly data structure for processing.
You can call external Java code from the script. You can also configure the processor to use invokedynamic bytecode instruction.
The processor provides extensive sample code that you can use to develop your script.
When configuring the processor, you specify the processing mode, enter the scripts, and specify the method to access records and any script parameters used in the script.
Processing Mode
You can choose the processing mode that the Groovy Evaluator uses to process the main script. You can use the same script in each processing mode. However, you should include error handling in the main script before you run in batch mode.
- Record by Record
- The processor calls the script for each record. The processor passes the record to the script as a map and processes each record individually.
- Batch by Batch
- The processor calls the script for each batch. The processor passes the batch to the script as a list and processes the batch at one time.
Groovy Scripting Objects
| Script Type | Valid Scripting Objects |
|---|---|
| Init | You can use the following scripting objects in the initialization
script:
|
| Main | You can use the following scripting objects in the main script:
|
| Destroy | You can use the following scripting objects in the destroy script:
|
- records
- A collection of records to process. The
records object includes different elements based on the processing mode that
you use:
- Record by Record - The records array includes one record element. A
record includes a single
valueelement. Thevalueelement contains the data for the record. - Batch by Batch - The records array includes all records in the batch.
- Record by Record - The records array includes one record element. A
record includes a single
- state
- An object to store information between invocations of the init, main, and
destroy scripts. A state is a map object that includes a collection of
key/value pairs. You can use the
stateobject to cache data such as lookups, counters, or a connection to an external system. - log
- An object that writes messages to the log4j log. Use
sdc.logto access the object configured for the stage. The object includes methods that correspond to the level in the log file:info(<message template>, <arguments>...)warn(<message template>, <arguments>...)error(<message template>, <arguments>...)trace(<message template>, <arguments>...)
The message template can contain positional variables, indicated by curly brackets: { }. When writing messages, the method replaces each variable with the argument in the corresponding position - that is, the method replaces the first { } occurrence with the first argument, and so on.
- output
- An object that writes the record to the output batch. Use
sdc.outputto access the object configured for the stage. The object includes awrite(<record>)method. - error
- An object that passes error records for error handling. Use
sdc.errorto access the object configured for the stage. The object includes awrite(<record>, <String message>)method. - sdc
- A wrapper object that accesses constants, methods, and objects available to the scripts.
- sdcFunctions
- An object that runs functions that evaluate or modify data. Important: The
sdcFunctionsobject is now deprecated and will be removed in a future release. To evaluate and modify data, use the methods in thesdcobject.ThesdcFunctionsobject includes the following methods:getFieldNull(<record>, <String field path>)- Returns one of the following:- The value of the field at the specified path if the value is not null
- The null object defined for the field type, such as
NULL_INTEGERorNULL_STRING, if the value is null - The unassigned null object
NULLif there is no field at the specified path
createRecord(<String record ID>)- Returns a new record with the passed ID. Pass a string that uniquely identifies the record and includes enough information to track the record source.createMap(<Boolean list-map>)- Returns a map for use as a field in a record. Passtrueto create a list-map field, orfalseto create a map field.createEvent(<String type>, <Integer version>)- Returns a new event record with the specified event type and version. Verify that the stage enables event generation before implementing event methods.toEvent(<event record>)- Sends an event record to the event output stream. Verify that the stage enables event generation before implementing event methods.isPreview()- Returns a Boolean value that indicates whether the pipeline is in preview mode.pipelineParameters()- Returns a map of all runtime parameters defined for the pipeline.
Accessing Record Details
By default, you use native types from the scripting language to access records in scripts. However, with native types, you cannot easily access all the features of Data Collector records, such as field attributes.
To access records in scripts directly as Data Collector
records, configure the stage to use the Data Collector Java API to process records in
scripts by setting the Record Type advanced property to Data Collector
Records.
In the script, reference the needed classes from
the Java package com.streamsets.pipeline.api and then use the
appropriate methods to access records and fields. With the Data Collector
Java API, scripts can access all the features of Data Collector
records.
- Create a String field named
newand set its value tonew-value. - Update the existing field named
oldto set the value of theattrattribute toattr-value.
import com.streamsets.pipeline.api.Field
...
record.sdcRecord.set('/new', Field.create(Field.Type.STRING, 'new-value'))
record.sdcRecord.get('/old').setAttribute('attr', 'attr-value')
...Processing List-Map Data
In scripts that process list-map data, treat the data as maps.
List-map is a Data Collector data type that allows you to use standard record functions to work with delimited data. When an origin reads delimited data, it generates list-map fields by default.
The Groovy Evaluator can read and pass list-map data. But to process data in a list-map field, treat the field as a map in the script.
Type Handling
Note the following type information when working with the Groovy Evaluator processor:
- Data type of null values
- You can
associate null values with a data type. For example, if the script assigns a
null value to an Integer field, the field is returned to the pipeline as an
integer with a null value.Use constants in the Groovy code to create a new field of a specific data type with a null value. For example, you can create a new String field with a null value by assigning the
NULL_STRINGtype constant to the field as follows:record.value['new_field'] = sdc.NULL_STRING - Date fields
- Use the String data type to create a new field to
store a date with a specific format. For example, the following sample code
creates a new String field that stores the current date using the format
YYYY-MM-dd:// Define a date object to record the current date def date = new Date() for (record in records) { try { // Create a string field to store the current date with the specified format record.value['date'] = new SimpleDateFormat('YYYY-MM-dd').format(date) // Write a record to the output sdc.output.write(record) } catch (e) { // Send a record to error sdc.log.error(e.toString(), e) sdc.error.write(record, e.toString()) } }
Event Generation
You can use the Groovy Evaluator processor to generate event records for an event stream. Enable event generation when you want the stage to generate an event record based on scripting logic.
As with any record, you can pass event records downstream to a destination for event storage or to any executor that can be configured to use the event. For more information about events and the event framework, see Dataflow Triggers Overview.
- On the General tab, select the Produce
Events property.
This enables the event output stream for use.
- Include both of the following methods in the script:
-
sdc.createEvent(<String type>, <Integer version>)- Creates an event record with the specified event type and version number. You can create a new event type or use an existing event type. Existing event types are documented in other event-generating stages.The event record contains no record fields. Generate record fields as needed.
-
sdc.toEvent(<record>)- Use to pass events to the event output stream.
-
Working with Record Header Attributes
You can use the Groovy Evaluator processor to read, update, or create record header attributes.
Use a map when creating or updating a header attribute. If a header attribute exists, the script updates the value. If it does not exist, the script creates the attribute and sets it to the specified value.
All records include a set of internal record header attributes that stages update automatically as they process records. Error records also have their own set of internal header attributes. You cannot change values of internal header attributes in scripts.
Some stages generate custom record header attributes that are meant to be used in particular ways. For example, the Oracle CDC origin specifies the operation type for a record in a record header attribute. And event-generating stages create a set of event header attributes for event records. For more information, see Record Header Attributes.
record.<header name>- Use to return the value of a header attribute.record.attributes- Use to return a map of custom record header attributes, or to create or update a specific record header attribute.
Viewing Record Header Attributes
You can use data preview to view the record header attributes associated with a record at any given point in the pipeline. To view record header attributes, enable the Show Record/Field Header data preview property.
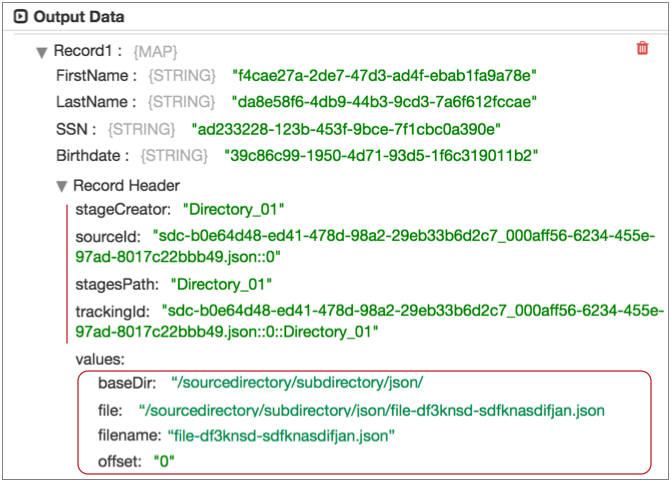
For example, the following image shows a record generated by the Directory origin in data preview.
 s
s
The "Record Header" list displays the set of
read-only internal attributes in the record at this point of the pipeline. You
can use the record.<header name> variable to return values for these
attributes.
The header attributes under "values" are the
attributes created by the Directory origin. You can use the
record.attributes variable to return or modify these attributes.
When you use the record.attributes variable to create a header
attribute, it displays in this location during data preview.
Accessing Whole File Format Records
In a pipeline that processes the whole file data format, you can use a Groovy Evaluator to read the whole file data.
The processor can access the fileref field in a whole file record by creating an input stream using the getInputStream() API. For example, you might use the processor to read the file data in the fileref field and then create new records with the data. The processor can access the fileref field, but cannot modify information in the field.
input_stream = record.value['fileRef'].getInputStream()
input_stream.read()input_stream.close()Calling External Java Code
You can call external Java code from the Groovy Evaluator processor. Simply install the external Java library to make it available to the processor. Then, call the external Java code from the Groovy script that you develop for the processor.
You install the external Java library into one of the Groovy stage libraries, streamsets-datacollector-groovy_2_4-lib or streamsets-datacollector-groovy_4_0-lib, which includes the processor. For information about installing additional drivers, see Install External Libraries.
import <package>.<class name>import org.bouncycastle.jcajce.provider.digest.SHA3For more information, see the following informative blog post: Calling External Java Code from Script Evaluators.
Granting Permissions on Groovy Scripts
The Java Security Manager is enabled by default.
- In Control Hub, edit the deployment, and in the Configure Engine section, click Advanced Configuration. Then, click Security Policy.
-
Add the following lines to the file:
// groovy source code grant codebase "file:///groovy/script" { <permissions>; };Where
<permissions>are the permissions you are granting to the Groovy scripts.For example, to grant read permission on all files in the/data/filesdirectory and subdirectories, add the following lines:// groovy source code grant codebase "file:///groovy/script" { permission java.util.PropertyPermission "*", "read"; permission java.io.FilePermission "/data/files/-", "read"; }; - Save the changes to the deployment and restart all engine instances.
Configuring a Groovy Evaluator Processor
Configure a Groovy Evaluator processor to use custom Groovy code in a pipeline.
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Produce Events Generates event records when events occur. Use for event handling. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
-
On the Groovy tab, configure the following
properties:
Groovy Evaluator Property Description Script Main processing script to use. Runs for each record or each batch of data, based on the configured processing mode.
Record Processing Mode Determines how the Groovy Evaluator processes the main script: - Record by Record - Processes records individually. Performs error handling.
- Batch by Batch - Processes records in batches. Requires error handling code in the script.
Default is Batch by Batch.
Init Script Optional initialization script to use. Use to set up any required connections or resources. Runs once when the pipeline starts.
Destroy Script Optional destroy script to use. Use to close any connections or resources that were used. Runs once when the pipeline stops.
-
On the Advanced tab, configure the following
properties:
Advanced Property Description Record Type Record type to use during script execution: - Data Collector Records - Select when scripts use Data Collector Java API methods to access records.
- Native Objects - Select when scripts use native types to access records.
Default value is Native Objects.
Enable invokedynamic Compiler Option Enables the use of the invokedynamic bytecode instruction. This can affect performance differently depending on the use case. For more information about Groovy invokedynamic support, see http://groovy-lang.org/indy.html.
Parameters in Script Script parameters and their values. The script accesses the values with the
sdc.userParamsdictionary.Script Error as Record Error Handles script errors based on how the On Record Error property is configured. Otherwise, the processor handles script errors as if the Send to Error option is selected. You might use the Script Error as Record Error property to discard script errors by enabling it and using the Discard option for the On Record Error property.
Default is disabled.