Record Header Attributes
Record header attributes are attributes in record headers that you can use in pipeline logic, as needed.
Some stages create record header attributes for a particular purpose. For example, CDC-enabled origins include the
CRUD operation type in the sdc.operation.type record header attribute.
This enables CRUD-enabled destinations to determine the operation type to use when
processing records. Similarly, the Hive Metadata processor generates record header
attributes that some destinations can use as part of the Drift Synchronization
Solution for Hive.
Other stages include processing-related information in record header attributes for general use. For example, event-generating stages include the event type in record header attributes in case you want to process the event based on that information. And several origins include information such as the originating file name, location, or partition for each record.
You can use certain processors to create or update record header attributes. For example, you can use an Expression Evaluator to create attributes for record-based writes.
The inclusion of attributes in record headers does not require using them in the pipeline. You can, for example, use the CDC-enabled Salesforce origin in a non-CDC pipeline and ignore the CDC record header attributes that are automatically generated.
When writing data to destination systems, record header attributes are preserved with the record only when using the Google Pub/Sub Publisher or JMS Producer destination or when using another destination with the SDC Record data format. To preserve the information when using other data formats, use the Expression Evaluator to copy information from record header attributes to record fields.
Working with Header Attributes
You can use an Expression Evaluator processor or any scripting processor to create or update record header attributes. For example, the MongoDB destination requires a CRUD operation to be specified in a record header attribute. If the origin providing the data does not generate that information automatically, you can use an Expression Evaluator processor or any scripting processor to set the attribute value.
Record header attributes are string values. You can use record:attribute functions in any expression to include attribute values in calculations.
${record:attribute('<attribute name>')}For example, the following Expression Evaluator adds the file and offset record header attributes created by the Directory origin to the record:
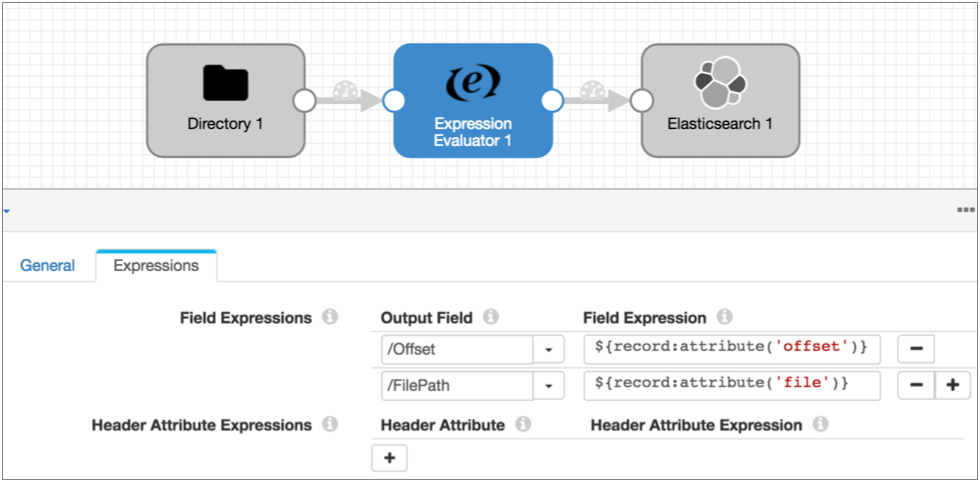
Internal Attributes
Data Collector generates and updates some read-only internal record header attributes as records move from stage to stage. These attributes can be viewed for debugging issues, but can only be updated by Data Collector.
| Internal Record Header Attribute | Description | Related Function |
|---|---|---|
| stageCreator | The ID of the stage that created the record. | record:creator() |
| sourceId | Source of the record. Can include different information based on the origin type. | record:id() |
| stagesPath | List of stages that processed the record in order, by stage name. | record:path() |
| trackingId | The route the record has taken through the pipeline, starting with the sourceId, then listing the stages that processed the record. | n/a |
| previousTrackingId | The tracking ID of the record before it entered the current stage. | n/a |
| errorStage | The stage that generated the error. In error records only. |
record:errorStage() |
| errorStageLabel | The user-defined name for a stage. In error records only. |
record:errorStageLabel() |
| errorCode | The error code. In error records only. |
record:errorCode() |
| errorJobId | The ID of the job that started the pipeline. Only in error records from pipelines started by Control Hub jobs. |
n/a |
| errorMessage | The error message. In error records only. |
record:errorMessage() |
| errorTimestamp | The time that the error occurred. In error records only. |
record:errorTime() |
| errorStackTrace | The stack trace associated with the error. In error records only. |
n/a |
Header Attribute-Generating Stages
| Stage | Description |
|---|---|
| CDC-enabled origins | Include the CRUD operation type in the sdc.operation.type header attribute and can include additional CRUD and CDC information in record header attributes. For more information, see CDC-Enabled Origins. |
| Origins that process Avro data and the Data Parser processor | Include the Avro schema in an avroSchema record header attribute. |
| Origins that process Parquet data |
Include the Parquet schema in a parquetSchema record header
attribute, and include the index number of the element in a
union the data is read from in an
|
| Origins that process XML data | Can include namespaces in an xmlns record header attribute when you enable field XPaths. |
| Stages that generate events | Generate record header attributes for event records. For details about event record header attributes, see "Event Records" in the stage documentation. |
| Amazon S3 origin | Can be configured to include system-defined and user-defined object metadata in record header attributes. |
| Amazon SQS Consumer origin | Can be configured to include SQS message attributes in record header attributes. |
| Aurora PostgreSQL CDC Client origin | When tables have primary keys, includes information about the primary keys in record header attributes. |
| Azure Blob Storage origin | Can be configured to include system-defined, user-defined, and custom object metadata in record header attributes. |
| Azure Data Lake Storage Gen2 origin | Can be configured to include system-defined and custom object metadata in record header attributes. |
| Azure Data Lake Storage Gen2 (Legacy) origin | Includes information about the originating file for the record in record header attributes. |
| CONNX origin | Can be configured to include table and data type information in JDBC record header attributes. |
| CONNX CDC origin | Can be configured to include table and data type information in JDBC record header attributes. |
| Directory origin | Includes information about the originating file for the record in record header attributes. |
| File Tail origin | Includes information about the originating file for
the record in record header attributes. Can be configured to use tag attributes for sets of files. |
| Google Pub/Sub Subscriber origin | When available, includes user-defined message attributes in record header attributes |
| Groovy Scripting origin | Can be configured to create record header attributes. |
| Hadoop FS Standalone origin | Includes information about the originating file for the record in record header attributes. |
| HTTP Client origin | Includes response header fields in record header attributes. |
| HTTP Server origin | Includes information about the requested URL and request header fields in record header attributes. |
| JavaScript Scripting origin | Can be configured to create record header attributes. |
| JDBC Multitable Consumer origin | Includes table and data type information in JDBC record header attributes. |
| JDBC Query Consumer origin | Can be configured to include table and data type information in JDBC record header attributes. |
| Jython Scripting origin | Can be configured to create record header attributes. |
| Kafka Multitopic Consumer origin | Includes information about the origins of the record in record header attributes. Can also include Kafka message headers in record header attributes. |
| MapR FS Standalone origin | Includes information about the originating file for the record in record header attributes. |
| MapR Multitopic Streams Consumer origin | Includes information about the origins of the record in record header attributes. |
| MapR Streams Consumer origin | Includes information about the origins of the record in record header attributes. |
| MQTT Subscriber origin | Includes information about the origins of the record in record header attributes. |
| MySQL Binary Log origin | When tables have primary keys, includes information about the primary keys in record header attributes. |
| Oracle CDC origin | When tables have primary keys, includes information about the
primary keys in record header attributes. Can include a range of additional data depending on how you configure the origin. |
| Oracle CDC Client origin | When tables have primary keys, includes information about the primary keys in record header attributes. |
| Oracle Multitable Consumer origin | Includes table and data type information in JDBC Header Attributes. |
| PostgreSQL CDC Client origin | When tables have primary keys, includes information about the primary keys in record header attributes. |
| Pulsar Consumer (Legacy) origin | Includes information in the properties field of the message and the topic that the message was read from in record header attributes. |
| RabbitMQ Consumer origin | Includes RabbitMQ attributes in record header attributes. |
| REST Service origin | Includes information about the URL and request header fields in record header attributes. |
| Salesforce origin | Includes Salesforce information about the origins of the record in Salesforce header attributes. |
| Salesforce Bulk API 2.0 origin | Includes Salesforce information about the origins of the record in Salesforce header attribute. |
| SAP HANA Query Consumer origin | Can be configured to include table and data type information in
JDBC header attributes. Can be configured to include SAP HANA connection information in SAP HANA header attributes. |
| SFTP/FTP/FTPS Client origin | Includes information about the originating file for the record in record header attributes. |
| Snowflake Bulk origin | Includes information about the origins of the record in Snowflake header attributes. |
| Couchbase Lookup processor | Includes information about the state of the looked-up document in a record header attribute. |
| Expression Evaluator processor | Can be configured to create or update record header attributes. |
| Groovy Evaluator processor |
Can be configured to create or update record header attributes. |
| Hive Metadata processor | Generates record header attributes for the data record. These
attributes can be used for record-based writes as part of the Drift Synchronization Solution for Hive. Can be configured to add custom header attributes to the metadata record. |
| HTTP Client processor | Includes response header fields in record header attributes. Generates record header attributes when passing an incoming record downstream based on per-status action or timeout properties. |
| JavaScript Evaluator processor | Can be configured to create or update record header attributes. |
| Jython Evaluator processor | Can be configured to create or update record header attributes. |
| Schema Generator processor | Generates schemas and writes them to a user-defined record header attribute. |
| Aerospike Client destination | Generates error record header attributes for records that cannot be written. |
Record Header Attributes for Record-Based Writes
Destinations can use information in record header attributes to write data. Destinations that write Avro data can use Avro schemas in the record header. The Hadoop FS and MapR FS destinations can use record header attributes to determine the directory to write to and when to roll a file as part of the Drift Synchronization Solution for Hive. For more information, see Drift Synchronization Solution for Hive.
To use a record header attribute, configure the destination to use the header attribute and ensure that the records include the header attribute.
The Hive Metadata processor automatically generates record header attributes for Hadoop FS and MapR FS to use as part of the Drift Synchronization Solution for Hive. For all other destinations, you can use the Expression Evaluator or a scripting processor to add record header attributes.
- targetDirectory attribute in all the Azure Data Lake Storage destinations and in the Hadoop FS, Local FS, and MapR FS destinations
- The targetDirectory record header attribute defines the directory where the record is written. If the directory does not exist, the destination creates the directory. The targetDirectory header attribute replaces the Directory Template property in the destination.
- avroSchema attribute in destinations that write Avro data
- The avroSchema header attribute defines the Avro schema for the record. When you use this header attribute, you cannot define an Avro schema to use in the destination.
- parquetSchema attribution in destinations that write Parquet data
- The parquetSchema header attribute defines the Parquet schema for the record. When you use this header attribute, you cannot define a Parquet schema to use in the destination.
- roll attribute in all the Azure Data Lake Storage destinations and in the Hadoop FS, Local FS, and MapR FS destinations
- The roll attribute, when present in the record header, triggers a roll of the file.
Generating Attributes for Record-Based Writes
You can use the Hive Metadata processor, an Expression Evaluator processor or any scripting processor to generate record header attributes for record-based writes. The Hive Metadata processor automatically generates record header attributes for Hadoop FS and MapR FS to use as part of the Drift Synchronization Solution for Hive. For all other destinations, you can use the Expression Evaluator or a scripting processor to add record header attributes.
- Generating the target directory
- When using an Expression Evaluator processor or any scripting processor to generate the target directory, note the following details:
- Generating the Avro schema
- When using an Expression Evaluator processor or any scripting
processor to generate the Avro schema, note the following details:
- The destination expects the Avro schema in a header attribute named "avroSchema".
- Use the standard Avro schema format, for example:
{"type":"record","name":"table_name","namespace":"database_name", "fields":[{"name":"int_val","type":["null","int"],"default":null}, {"name":"str_val","type":["null","string"],"default":null}]} - The database name and table name must be included in the Avro schema.
- Generating the roll attribute
- When using an Expression Evaluator processor or any scripting
processor to generate the roll attribute, note the following details:
- Use any name for the attribute and specify the attribute name in the destination.
- Configure an expression that defines when to roll files.
- On the Expressions tab of the Expression Evaluator, specify
the Header Attribute name.
To generate a target directory, use
targetDirectory.To generate an Avro schema, use
avroSchema.You can use any name for a roll indicator header attribute.
- For the Header Attribute Expression, define the expression that evaluates to the information you want the destination to use.
For information about generating record header attributes with scripting processors, see the scripting processor documentation.
Viewing Attributes in Data Preview
You can use data preview to view the record header attributes associated with a record at any given point in the pipeline. To view record header attributes, enable the Show Record/Field Header data preview property.
For example, the following image shows a record generated by the Directory origin in data preview.
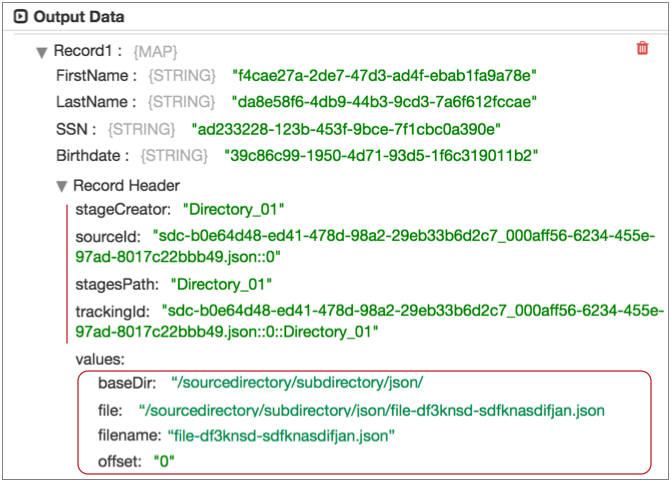
The "Record Header" list displays the set of read-only internal attributes in the record at this point of the pipeline. The header attributes under "values" are the attributes created by the Directory origin.