Field Attributes
Field attributes are attributes that provide additional information about each field that you can use in pipeline logic, as needed.
Some stages generate field attributes. For example, the Salesforce origin includes the
original Salesforce data type in the salesforce.salesforceType
attribute for every field.
You can create, modify, and evaluate field attributes in the pipeline. The Expression Evaluator enables creating and modifying field-level attributes. You can use field attribute functions to evaluate field attributes.
For example, you can use an Expression Evaluator to create a field attribute based on record data, then pass the record to a Stream Selector that routes data based on the value of the attribute.
To include field attributes in the record data or to use
field attributes in calculations, use the record:fieldAttribute
and record:fieldAttributeOrDefault functions. For more
information about field attribute functions, see Record Functions.
When using data preview, you can enable viewing field attributes and record header attributes to aid with pipeline development.
Working with Field Attributes
Like record header attributes, you can use an Expression Evaluator processor or any scripting processor to create or update field attributes. For example, when processing Avro data, origins place the precision and scale information for Decimal data into field attributes. If you want to increase those values before writing them to the destination system, you can use an Expression Evaluator processor or any scripting processor to set the attribute value.
Field attributes are string values. You can also use
record:fieldAttribute functions in any expression to include
attribute values in calculations.
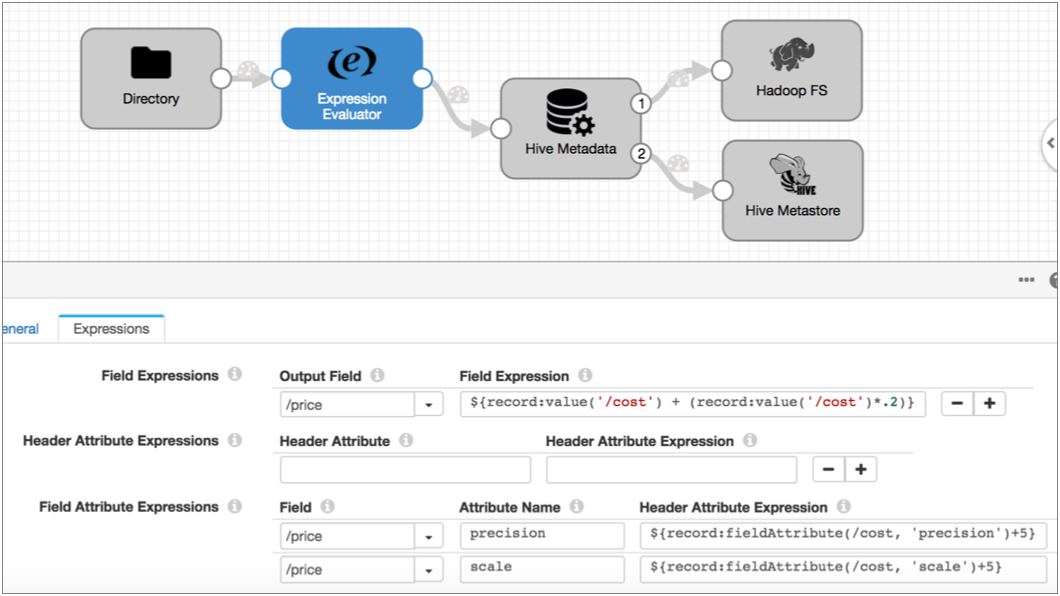
${record:fieldAttribute(<path to the field>,'<attribute name>')}For example, say you are processing Avro data as part of the Drift Synchronization Solution for Hive. All Decimal fields include automatically generated precision and scale field attributes. Before passing the data to the Hive Metadata processor, you want to create a new Price Decimal field based on the existing cost data.
The following Expression Evaluator creates the Price field and defines the precision and scale field attributes based on the existing Cost precision and scale.
Field Attribute-Generating Stages
The following table lists the stages that generate field attributes to enable special processing:
| Stage | Description |
|---|---|
| Origins that process Avro data | Include precision and scale field attributes for every decimal field. |
| Origins that process XML data | Can include field XPath information, XML attribute, and namespace declarations in field attributes. |
| CONNX origin | Includes the following field
attributes:
|
| CONNX CDC origin | Includes the following field attributes:
|
| Google BigQuery origin | Includes original precision for datetime, time, and timestamp fields in a field attribute. |
| JDBC Multitable Consumer origin | Includes the following field attributes:
|
| JDBC Query Consumer origin | Includes the following field attributes:
|
| Oracle Bulkload origin | Includes the following field attributes:
|
| Oracle CDC origin | Includes the following field attributes:
Can include additional attributes with information about column types, and presence of each column in the redo SQL statement. |
| Oracle CDC Client origin | Includes the following field
attributes:
|
| Oracle Multitable Consumer origin | Includes the following field
attributes:
|
| Salesforce origin | Includes data type information in field attributes. |
| SQL Server CDC Client origin | Includes the following field attributes:
|
| SQL Server Change Tracking origin | Includes the following field attributes:
|
| JDBC Lookup processor | Includes the following field attributes:
|
| Salesforce Lookup processor | Includes data type information in field attributes. |
| SQL Parser processor | Includes the following field attributes:
|
| XML Parser | Can include field XPath information, XML attribute, and namespace declarations in field attributes. |
Viewing Field Attributes in Data Preview
As with record header attributes, you can use data preview to view field attributes at any point in the pipeline. To view field attributes, enable the Show Record/Field Header data preview property.