SQL Server CDC Client
The SQL Server CDC Client origin processes data in Microsoft SQL Server change data capture (CDC) tables. The origin fetches changes in time windows and uses multiple threads to enable parallel processing of data. For information about supported versions, see Supported Systems and Versions.
Use the SQL Server CDC Client origin to generate records from CDC tables. To read data from Microsoft SQL Server change tracking tables, use the SQL Server Change Tracking origin. For more information about the differences between CDC and change tracking data, see the Microsoft SQL Server documentation. To read data from SQL Server temporal tables, use the JDBC Multitable Consumer origin or the JDBC Query Consumer origin. For more information about temporal tables, see the Microsoft documentation.
By default, the SQL Server CDC Client origin generates a record for each record in the CDC table. You can configure the origin to combine the two update records that SQL Server generates for each update. This changes the structure of the generated records and produces additional record header attributes.
The SQL Server CDC Client origin includes the CRUD operation type in a record header attribute so generated records can be easily processed by CRUD-enabled destinations. For an overview of Data Collector changed data processing and a list of CRUD-enabled destinations, see Processing Changed Data.
You might use this origin to perform database replication. You can use a separate pipeline with the JDBC Query Consumer or JDBC Multitable Consumer origin to read existing data. Then start a pipeline with the SQL Server CDC Client origin to process subsequent changes.
When you configure the origin, you specify the SQL Server capture instance names - the origin processes the related CDC tables. You can define groups of tables in the same database and any initial offsets to use. When you omit initial offsets, the origin processes all available data in the CDC tables.
You can enable late table processing to allow the origin to process tables that appear after the pipeline starts. You can also configure the origin to check for schema changes in processed tables and to generate an event after discovering a change.
To determine how the origin connects to the database, you specify connection information, a query interval, number of retries, and any custom JDBC configuration properties that you need. You can configure advanced connection properties. You can also use a connection to configure the origin.
The origin can generate events for an event stream. For more information about dataflow triggers and the event framework, see Dataflow Triggers Overview.
When a pipeline stops, the SQL Server CDC Client origin notes where it stops reading. When the pipeline starts again, the origin continues processing from where it stopped by default. You can reset the origin to process all requested data.
JDBC Driver
When connecting to Microsoft SQL Server, you do not need to install a JDBC driver. Data Collector includes the JDBC driver required for SQL Server.
Supported Operations
The SQL Server CDC Client origin supports the SQL Server insert and delete operations. Updates captured after the update operation are treated as update, and updates captured before the update operation are treated as an unsupported operation.
Time Windows
The SQL Server CDC Client origin fetches changes from tables in time windows. By default, the origin fetches changes in one time window, beginning with the last committed offset and ending with the latest data. When you have large volumes of data, you can improve performance by configuring multiple time windows.
To configure multiple time windows, set the Maximum Transaction Length property to the desired size of the time windows. The first time window starts at the initial offset or last saved offset and ends the specified number of seconds later. The next window starts where the previous ended and ends the specified number of seconds later, and so on. Within each time window, the origin creates batches based on the batch settings.
When you enable event generation, the origin produces a no-more-data event at the end of each time window, even when subsequent time windows remain for processing.
Previewing data shows no values when there are no changes during the first time window.
Multithreaded Processing
The SQL Server CDC Client origin performs parallel processing and enables the creation of a multithreaded pipeline.
When you start the pipeline, the SQL Server CDC Client origin retrieves the list of CDC tables associated with the source tables defined in the table configurations. The origin then uses multiple concurrent threads based on the Number of Threads property. Each thread reads data from a single table.
As the pipeline runs, each thread connects to the origin system, creates a batch of data, and passes the batch to an available pipeline runner. A pipeline runner is a sourceless pipeline instance - an instance of the pipeline that includes all of the processors, executors, and destinations in the pipeline and handles all pipeline processing after the origin.
Each pipeline runner processes one batch at a time, just like a pipeline that runs on a single thread. When the flow of data slows, the pipeline runners wait idly until they are needed, generating an empty batch at regular intervals. You can configure the Runner Idle Time pipeline property to specify the interval or to opt out of empty batch generation.
Multithreaded pipelines preserve the order of records within each batch, just like a single-threaded pipeline. But since batches are processed by different pipeline runners, the order that batches are written to destinations is not ensured.
For more information about multithreaded pipelines, see Multithreaded Pipeline Overview.
Example
Say you are reading from 10 tables. You set the Number of Threads property to 5 and the Maximum Pool Size property to 6. When you start the pipeline, the origin retrieves the list of tables. The origin then creates five threads to read from the first five tables, and by default Data Collector creates a matching number of pipeline runners. Upon receiving data, a thread passes a batch to each of the pipeline runners for processing.
At any given moment, the five pipeline runners can each process a batch, so this multithreaded pipeline processes up to five batches at a time. When incoming data slows, the pipeline runners sit idle, available for use as soon as the data flow increases.
Batch Strategy
You can specify the batch strategy to use when processing data:
- Process all available rows from the table
- Each thread processes all available rows from a table. A thread runs a SQL query and processes all of the results for a table. Then, the thread switches to the next available table.
- Switch tables
- When the origin performs multithreaded table processing for all tables, each thread processes one batch of data, then switches to an available table and repeats the process. When a pipeline starts, each thread runs a SQL query, generates a result set, and processes a batch of records from the result set. The database driver caches the remaining records for the same thread to access again. Then, the thread switches to the next available table.
Table Configuration
When you configure SQL Server CDC Client, you can define multiple CDC tables using a single set of table configuration properties. You can also define multiple table configurations to process multiple groups of CDC tables.
- Capture Instance Name
- Determines the CDC tables to process. The naming convention for Microsoft
SQL Server CDC tables is <capture instance name>_CT. When specifying this
property, use the capture instance name, not the names of the CDC tables to
be processed. For example, specify the
dbo.customersource table, not the associated CDC table,dbo_customer_CT. - Table exclusion pattern
- Optionally specify a regex pattern for the table names that you want to
exclude from the query.
For example, say you want to process all CDC tables in the schema except for those that start with "dept". You can use the default % for the table name pattern, and enter dept* for the table exclusion pattern.
For more information about using regular expressions with Data Collector, see Regular Expressions Overview.
- Initial offset
- To process existing data, specify an initial offset. When not set, the origin processes all available CDC data.
Initial Table Order Strategy
You can define the initial order that the origin uses to read the tables.
- None
- Reads the tables in the order that they are listed in the database.
- Alphabetical
- Reads the tables in alphabetical order.
The origin uses the table order strategy only for the initial reading of the tables. When threads switch back to previously read tables, they read from the next available table, regardless of the defined order.
Allow Late Table Processing
You can configure the SQL Server CDC Client to process data in CDC tables that appear after the pipeline starts.
When you allow late table processing, the SQL Server CDC Client origin uses a background thread to check for late CDC tables. The origin checks at regular user-defined intervals.
- On the JDBC tab, select the Allow Late Tables property.
- To define the time to wait before checking for new tables, configure the New Table Discovery Interval property.
- On the Advanced tab, set the Maximum Pool Size and Minimum Idle Connections properties to one thread more than the Number of Threads property.
Checking for Schema Changes
You can configure the SQL Server CDC Client origin to check for schema changes in the tables being processed. When checking for schema changes, the origin includes a schema check statement in the SQL query.
- Compares current table schemas with the original table schemas at regular intervals, based on the Query Interval property.
- If it determines that the schema of a table has changed, it generates a
schema-change event that states the table or capture instance name with the
changed schema.
The origin generates a schema-change event each time that it finds a schema change: one for each table with a schema change.
Note: Since the origin continues to check for schema changes at regular intervals until the pipeline stops, a single schema change can generate a large volume of events. - It can write the exact column name or data type change to the Data Collector log. To enable writing to the log, the log level must be set to Trace. For information about changing the log level, see the Control Hub documentation.
- On the General tab, select the Produce Events property.
- On the JDBC tab, select the Enable Schema Changes Event property.
Generated Record
The SQL Server CDC Client origin generates records from CDC tables, placing the CDC information, such as the CDC operation type and start LSN values, in record header attributes and generating field attributes for some converted fields.
- Basic - Generates two records for updates, one with the old data and one with the changed data.
- Basic discarding ‘Before Update’ records - Generates one record for updates, containing the changed data.
- Rich - Generates one record for updates with data written to the Data field, OldData field, or both.
The origin generates a record header attribute named record_format, which
indicates the format of the generated record: 1 indicates basic format, 2 indicates basic
discarding “before update” records, and 3 indicates rich.
Basic Record Format
By default, the Record Format property is set to Basic. The origin creates one record for each record in the CDC table. SQL Server generates two records in the CDC table for each update, one with the old data and one with the changed data. Therefore, each update operation results in two records. The origin writes the data to fields that match the data fields in the CDC table.
For example, suppose a CDC table with three fields (id, name, and dt) has four records: a record for an insert, two records for an update, and a record for a delete. With the Record Format property set to Basic, the origin generates four records, one for each record in the CDC table, as shown below.
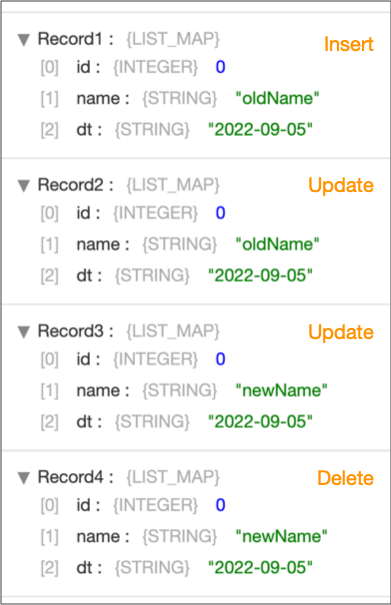
Basic Discarding Before Update Record Format
When you set the Record Format to Basic discarding Before Update records, the origin creates one record for each record in the CDC table. For updates, the record contains the changed data.
For example, suppose a CDC table with three fields (id, name, and dt) has four records: a record for an insert, two records for an update, and a record for a delete. With the Record Format property set to Basic discarding Before Update records, the origin generates three records, one for the insert record, one for the delete record, and a single update record showing the changed data, as shown below.
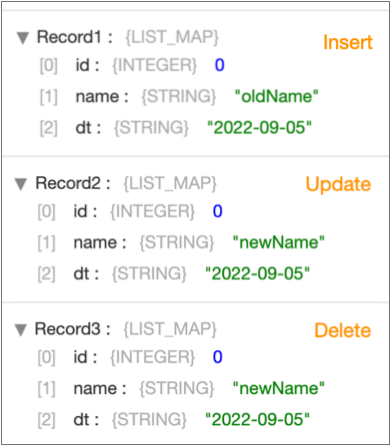
Rich Record Format
- For an insert operation, the origin writes the inserted data in the Data map field and does not create an OldData field.
- For an update operation, the origin writes the data before the update in an OldData map field and the data after the update in a Data map field.
- For a delete operation, the origin writes the data before the deletion in the OldData map field and does not create a Data field.
You might set the Record Format property to Rich to produce one record for each update, similar to how other origins generate records.
For example, suppose a CDC table with three fields (id, name, and dt) has four records: a record for an insert, two records for an update, and a record for a delete. With the Record Format property set to Rich, the origin generates three records, as shown below.
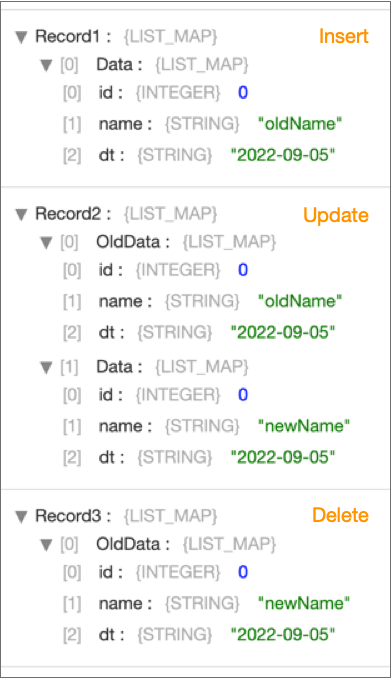
Note that the update record includes the previous data in an OldData map field, and the updated data in a Data map field. If all you need is the updated data, you can use the Field Remover processor to drop the OldData field from the record. And you could use a Field Flattener processor to flatten the fields in the Data field.
Record Header Attributes
The SQL Server CDC Client origin generates JDBC record header attributes that provide the SQL Server CDC data for each record, such as the start or end log sequence numbers (LSNs).
The origin also includes the sdc.operation.type attribute,
record_format attribute, and information from the SQL Server CDC
tables. The SQL Server CDC Client header attributes are prefixed with
jdbc. The names of the SQL Server CDC column names are included in
the header attribute name, as follows: jdbc.<CDC column name>.
You can use the record:attribute or
record:attributeOrDefault functions to access the information
in the attributes. For more information about working with record header attributes,
see Working with Header Attributes.
| Header Attribute Name | Description |
|---|---|
| sdc.operation.type |
Provides one of the following values to represent the operation
type:
|
| record_format | Provides one of the following values to represent the generated record
format:
|
| jdbc.cdc.source_schema_name | Provides the source schema for the CDC data. |
| jdbc.cdc.source_name | Provides the source table for the CDC data. |
| jdbc.tables |
Provides a
comma-separated list of source tables for the fields in the
record.
Note: Not all JDBC drivers
provide this information. |
| jdbc.<column name>.jdbcType | Provides
the numeric value of the original SQL data type for each field
in the record. See the Java documentation for
a list of the data types that correspond to numeric
values.
Because the record read from the SQL Server CDC table includes
CDC columns, the generated record also includes corresponding
For example, since the
original data includes a __$start_lsn column, the resulting
record has a |
| jdbc.<column name>.jdbc.precision | Provides the original precision for all numeric and decimal fields. |
| jdbc.<column name>.jdbc.scale | Provides the original scale for all numeric and decimal fields. |
| jdbc.primaryKeySpecification |
Provides a JSON-formatted
string that lists the columns that form the primary key in the table and the
metadata for those columns. For example, a table with a
composite primary key contains the following attribute:
A table without a primary key
contains the attribute with an empty value:
|
| jdbc.primaryKey.before.<primary key column name> |
Provides the old
value for the specified primary key column. Generated when the record represents an update operation on a table with a primary key. |
| jdbc.primaryKey.after.<primary key column name> |
Provides the new
value for the specified primary key column. Generated when the record represents an update operation on a table with a primary key. |
| jdbc. __$command_id | Data from the SQL Server CDC __$command_id column. |
| jdbc.__$end_lsn | Data from the SQL Server CDC __$end_lsn column. |
| jdbc.__$operation | The CRUD operation type using SQL Server codes, as defined in the SQL Server CDC __$operation column. |
| jdbc.__$seqval | Data from the SQL Server CDC __$seqval column. |
| jdbc.__$start_lsn | Data from the SQL Server CDC __$start_lsn column. |
| jdbc.__$update_mask | Data from the SQL Server CDC __$update_mask column. |
For details about the CDC attributes, see the SQL Server documentation.
CRUD Operation Header Attributes
- sdc.operation.type
- The SQL Server CDC Client origin writes the operation type to the
sdc.operation.typerecord header attribute. - jdbc.__$operation
- The SQL Server CDC Client origin places the values from the SQL Server
__$operation column in the
jdbc.__$operationrecord header attribute. As a result, thejdbc.__$operationrecord header attribute contains the CRUD operation type as defined using SQL Server CDC codes.
Field Attributes
The SQL Server CDC Client origin generates field attributes for columns converted to the Decimal or Datetime data types in Data Collector. The attributes provide additional information about each field.
- SQL Server Decimal and Numeric data types are converted to the Data Collector Decimal data type, which does not store scale and precision.
- SQL Server Datetime, Datetime2, and Smalldatetime data types are converted to the Data Collector Datetime data type, which does not store nanoseconds.
| Data Collector Data Type | Generated Field Attribute | Description |
|---|---|---|
| Decimal | precision | Provides the original precision for every decimal or numeric column. |
| Decimal | scale | Provides the original scale for every decimal or numeric column. |
| Datetime | nanoSeconds | Provides the original nanoseconds for every datetime, datetime2, or smalldatetime column. |
You can use the record:fieldAttribute or
record:fieldAttributeOrDefault functions to access the information
in the attributes. For more information about working with field attributes, see Field Attributes.
Event Generation
The SQL Server CDC Client origin can generate events that you can use in an event stream. When you enable event generation, the origin generates an event when it completes processing the data returned by the specified queries for all tables.
If you enable schema change event generation, the origin also generates an event each time it finds a schema change.
- With the Pipeline Finisher executor to
stop the pipeline and transition the pipeline to a Finished state when
the origin completes processing available data.
When you restart a pipeline stopped by the Pipeline Finisher executor, the origin continues processing from the last-saved offset unless you reset the origin.
For an example, see Stopping a Pipeline After Processing All Available Data.
- With a destination to store event information.
For an example, see Preserving an Audit Trail of Events.
For more information about dataflow triggers and the event framework, see Dataflow Triggers Overview.
Event Record
| Record Header Attribute | Description |
|---|---|
| sdc.event.type | Event type. Uses one of the following types:
|
| sdc.event.version | Integer that indicates the version of the event record type. |
| sdc.event.creation_timestamp | Epoch timestamp when the stage created the event. |
- no-more-data
-
The origin generates a no-more-data event record when the origin completes processing all available data in a time window and the number of seconds configured for event generation delay elapses without any new files appearing to be processed. The origin generates the event record even when subsequent time windows remain for processing.
The no-more-data event record generated by the origin has the sdc.event.type set to no-more-data and does not include any additional fields.
- schema-change
-
The origin generates a schema-change event record only when you enable the origin to check for schema changes, and the origin discovers a schema change.
The schema-change event record generated by the origin has the sdc.event.type set to schema-change and includes the following fields:Event Record Field Description capture-instance-name The name of the capture instance or CDC table associated with the table with the schema change. source-table-schema-name The name of the schema that contains the data table. source-table-name The name of the data table that has a schema changes.
Configuring a SQL Server CDC Client Origin
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Produce Events Generates event records when events occur. Use for event handling. On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
-
On the JDBC tab, configure the following properties:
JDBC Property Description Connection Connection that defines the information required to connect to an external system. To connect to an external system, you can select a connection that contains the details, or you can directly enter the details in the pipeline. When you select a connection, Control Hub hides other properties so that you cannot directly enter connection details in the pipeline.
To create a new connection, click the Add New Connection icon:
 . To view and edit the details of the
selected connection, click the Edit
Connection icon:
. To view and edit the details of the
selected connection, click the Edit
Connection icon:  .
.JDBC Connection String Connection string used to connect to the database.
Number of Threads Number of threads the origin generates and uses for multithreaded processing. Configure the Maximum Pool Size property on the Advanced tab to be equal to or greater than this value.
Record Format Format of update records generated from CDC tables: - Basic - Generates two records for updates, one with the old data and one with the changed data.
- Basic discarding Before Update records - Generates one record for updates, containing the changed data.
- Rich - Generates one record for updates with data written to the Data field, OldData field, or both.
Use Direct Table Query Queries the CDC table directly. When enabled, the origin fetches data directly from the CDC table, which typically uses fewer connections to the database. Otherwise, the origin fetches data from the CDC table using system queries, which can require more connections to the database.
Note: When disabled, Data Collector obtains a lock on the change tracking table, which can prevent a built-in stored procedure that performs a cleanup job from running until the pipeline completes.Per Batch Strategy Strategy to create each batch of data: - Switch Tables - Each thread creates a batch of data from one table, and then switches to the next available table to create the next batch. Define the Batches from Result Set property when you configure a Switch Tables strategy.
- Process All Available Rows From the Table - Each thread processes all data from a table before moving to the next table.
Batches from Result Set Maximum number of batches to create from a result set. After a thread creates this number of batches from a result set, it closes the result set. Then, any available thread can read from the table. Use a positive integer to set a limit on the number of batches created from the result set. Use -1 to allow an unlimited number of batches to be created from a result set.
By default, the origin creates an unlimited number of batches from the result set, keeping the result set open as long as possible.
Available when using the Switch Tables batch strategy.
Result Set Cache Size Number of result sets to cache in the database. Use a positive integer to set a limit on the number of cached result sets. Use -1 to opt out of this property. By default, the origin caches an unlimited number of result sets.
Fetch Size Maximum number of rows to fetch and store in memory on the Data Collector machine. The size cannot be zero. Default is 1,000.
Use Credentials Enables entering credentials. Use when you do not include credentials in the JDBC connection string. Queries per Second Maximum number of queries to run in a second across all partitions and tables. Use 0 for no limit. Default is 10.
Max Batch Size (records) Maximum number of records to include in a batch. Max Clob Size (characters) Maximum number of characters to be read in a Clob field. Larger data is truncated. Max Blob Size (bytes) Maximum number of bytes to be read in a Blob field.
Number of Retries on SQL Error Number of times a thread tries to read a batch of data after receiving an SQL error. After a thread retries this number of times, the thread handles the error based on the error handling configured for the origin. Use to handle transient network or connection issues that prevent a thread from reading a batch of data.
Default is 0.
Allow Late Tables Allows the origin to process tables that appear after the pipeline starts. When enabled, the origin uses a background thread to check for additional tables to process. For information about adjusting related configuration properties, see Allow Late Table Processing.
New Table Discovery Interval Time to wait before checking for additional tables to process. Available if you enable Allow Late Tables.
Enable Schema Changes Event Enables regular checks for schema changes. When enabled, the origin checks for schema changes for all processed tables at regular intervals based on the Query Interval property. The origin generates a schema change event each time it discovers a schema change.
Maximum Transaction Length Size of the time windows that the origin uses to fetch data. Specify in seconds or with a time expression. Default value is -1. When set to -1, the origin fetches changes in one time window, beginning with the last committed offset and ending with the latest data. Setting a value improves performance with large volumes of data.
When you set a value, the origin fetches changes over multiple time windows. The property defines the size of the time windows.
No-more-data Event Generation Delay (seconds) Number of seconds to delay generation of the no-more-data event after processing all rows. Use to allow time for additional data to arrive before generating the no-more-data event. Convert Timestamp To String Enables the origin to write timestamps as string values rather than datetime values. Strings maintain the precision stored in the source system. For example, strings can maintain the precision of a high-precision SQL Server datetime2 field. When writing timestamps to Data Collector date or time data types that do not store nanoseconds, the origin stores any nanoseconds from the timestamp in a field attribute.
Additional JDBC Configuration Properties Additional JDBC configuration properties to use. To add properties, click Add and define the JDBC property name and value. Use the property names and values as expected by JDBC.
-
On the CDC tab, define one or more table configurations.
Using simple or bulk edit mode, click the Add icon
to define another table configuration.
CDC Property Description Capture Instance Name Determines the set of CDC tables to process. Use SQL LIKE syntax to define a table name pattern for the table names. Use one of the following formats: - To process the CDC tables that match the
specified capture instance name pattern, use the following
format:
<capture instance name pattern> - To process all available CDC tables for the
specified data tables, use the following
format:
<schema name>_<data table name pattern> - To process all CDC tables associated with the
schema, use the following format:
<schema name>_%
Default is dbo_%, which processes all available CDC tables in the default dbo schema.
Table Exclusion Pattern Pattern of the table names to exclude from being read for this table configuration. Use a Java-based regular expression, or regex, to define the pattern. Leave empty if you do not need to exclude any tables.
To view and configure this option, click Show Advanced Options.
Initial Offset Offset value to use for this table configuration. When the pipeline starts, the offset value determines where the origin starts processing: - 0 or higher - Start with the first value in the offset column greater than or equal to the offset value.
- Blank - Start with the lowest value in the offset column.
- -1 - Start with new, incoming changes, ignoring existing data.
To view and configure this option, click Show Advanced Options.
- To process the CDC tables that match the
specified capture instance name pattern, use the following
format:
-
To enter JDBC credentials separately from the JDBC connection string, on the
Credentials tab, configure the following
properties:
Credentials Property Description Username User name for the JDBC connection. The user account must have the correct permissions or privileges in the database. Password Password for the account. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores. -
When using JDBC versions older than 4.0, on the Legacy
Drivers tab, optionally configure the following
properties:
Legacy Drivers Property Description JDBC Class Driver Name Class name for the JDBC driver. Required for JDBC versions older than version 4.0. Connection Health Test Query Optional query to test the health of a connection. Recommended only when the JDBC version is older than 4.0. -
On the Advanced tab, optionally configure the following
properties:
The defaults for these properties should work in most cases:
Advanced Property Description Initial Table Order Strategy Initial order used to read the tables: - None - Reads the tables in the order that they are listed in the database.
- Alphabetical - Reads the tables in alphabetical order.
On Unknown Type Action to take when encountering an unsupported data type: - Stop Pipeline - Stops the pipeline after completing the processing of the previous records.
- Convert to String - When possible, converts the data to string and continues processing.
Maximum Pool Size Maximum number of connections to create. Must be equal to or greater than the value of the Number of Threads property. Default is 1.
Minimum Idle Connections Minimum number of connections to create and maintain. To define a fixed connection pool, set to the same value as Maximum Pool Size. Default is 1.
Connection Timeout (seconds) Maximum time to wait for a connection. Use a time constant in an expression to define the time increment. Default is 30 seconds, defined as follows:${30 * SECONDS}Idle Timeout (seconds) Maximum time to allow a connection to idle. Use a time constant in an expression to define the time increment. Use 0 to avoid removing any idle connections.
When the entered value is close to or more than the maximum lifetime for a connection, Data Collector ignores the idle timeout.
Default is 10 minutes, defined as follows:${10 * MINUTES}Max Connection Lifetime (seconds) Maximum lifetime for a connection. Use a time constant in an expression to define the time increment. Use 0 to set no maximum lifetime.
When a maximum lifetime is set, the minimum valid value is 30 minutes.
Default is 30 minutes, defined as follows:${30 * MINUTES}Auto Commit Determines if auto-commit mode is enabled. In auto-commit mode, the database commits the data for each record. Default is disabled.
Enforce Read-only Connection Creates read-only connections to avoid any type of write. Default is enabled. Disabling this property is not recommended.
Transaction Isolation Transaction isolation level used to connect to the database. Default is the default transaction isolation level set for the database. You can override the database default by setting the level to any of the following:
- Read committed
- Read uncommitted
- Repeatable read
- Serializable
Init Query SQL query to perform immediately after the stage connects to the database. Use to set up the database session as needed. The query is performed after each connection to the database. If the stage disconnects from the database during the pipeline run, for example if a network timeout occurrs, the stage performs the query again when it reconnects to the database.