Aurora PostgreSQL CDC Client
The Aurora PostgreSQL CDC Client origin processes Write-Ahead Logging (WAL) data to generate change data capture records for an Amazon Aurora PostgreSQL database. To generate change data capture records for a PostgreSQL database not running on Amazon Aurora, use the PostgreSQL CDC Client origin. For information about supported versions, see Supported Systems and Versions.
You might use this origin to perform database replication. You can use a separate pipeline with the JDBC Query Consumer or JDBC Multitable Consumer origin to read existing data. Then start a pipeline with the Aurora PostgreSQL CDC Client origin to process subsequent changes.
You configure the contents of the records that the Aurora PostgreSQL CDC Client origin generates. The origin can generate a single record from either each transaction or each operation. The record contents affect the record header attributes, which determine whether additional processing is needed before passing the records to CRUD-enabled destinations. For an overview of Data Collector changed data processing and a list of CRUD-enabled destinations, see Processing Changed Data.
Because the origin uses the wal2json output plugin for logical decoding, you must configure the wal2json format, which determines how the origin reads data. The wal2json format and the record contents affect the memory that the origin and database use.
When you configure the Aurora PostgreSQL CDC Client, you configure the change capture details, such as the schema and tables to read from, the initial change to use, and the operations to include. You can also use a connection to configure the origin.
You define the name for the replication slot to be used, and specify whether to remove replication slots on close. You can also specify the behavior when the origin encounters an unsupported data type and include the data for those fields in the record as unparsed strings. When the source database has high-precision timestamps, you can configure the origin to write string values rather than datetime values to maintain the precision.
To determine how the origin connects to the database, you specify connection information, a query interval, number of retries, and any custom JDBC configuration properties that you need. You can configure advanced connection properties.
You can also configure the origin to use a secure connection to the database server using SSL/TLS encryption.
Before you configure the origin, you must complete the prerequisites.
Aurora PostgreSQL Prerequisites
Before you configure the Aurora PostgreSQL CDC Client origin, complete the following prerequisites in the Aurora PostgreSQL database:
- Enable logical replication.
- Assign the required role.
Enable Logical Replication
To enable the Aurora PostgreSQL CDC Client origin to read Write-Ahead Logging (WAL) changed data capture information, you must enable logical replication for the Aurora PostgreSQL database.
To enable PostgreSQL logical replication with Aurora, set the
rds.logical_replication static parameter in the database parameter
group to 1. Setting this parameter enables the wal2json plugin.
For more information, see the Amazon Aurora documentation.
Assign the Required Role
Reading WAL change data capture data from Aurora PostgreSQL requires that the user specified in the stage or connection has the same privileges as the database default user, as granted with the superuser role.
You can specify the default user, named postgres by default. Or you can
create another database user, grant that user the superuser role, and then specify that
user in the stage or connection properties. For details on creating another user with
the same privileges as the default user, see this Amazon Aurora article.
JDBC Driver
When connecting to an Aurora PostgreSQL database, you do not need to install a JDBC driver. Data Collector includes the Amazon Web Services PostgreSQL RDS driver required for Aurora PostgreSQL.
Schema, Table Name, and Exclusion Patterns
When you configure the Aurora PostgreSQL CDC Client origin, you specify the tables with the change capture data that you want to process. To specify the tables, you define the schema, a table name pattern, and an optional exclusion pattern.
When defining the schema and table name pattern, you can use SQL LIKE syntax to define a set of tables within a schema or across multiple schemas. For more information about valid patterns for the SQL LIKE syntax, see the PostgreSQL documentation.
When needed, you can also use a regular expression as an exclusion pattern to exclude a subset of tables from the larger set.
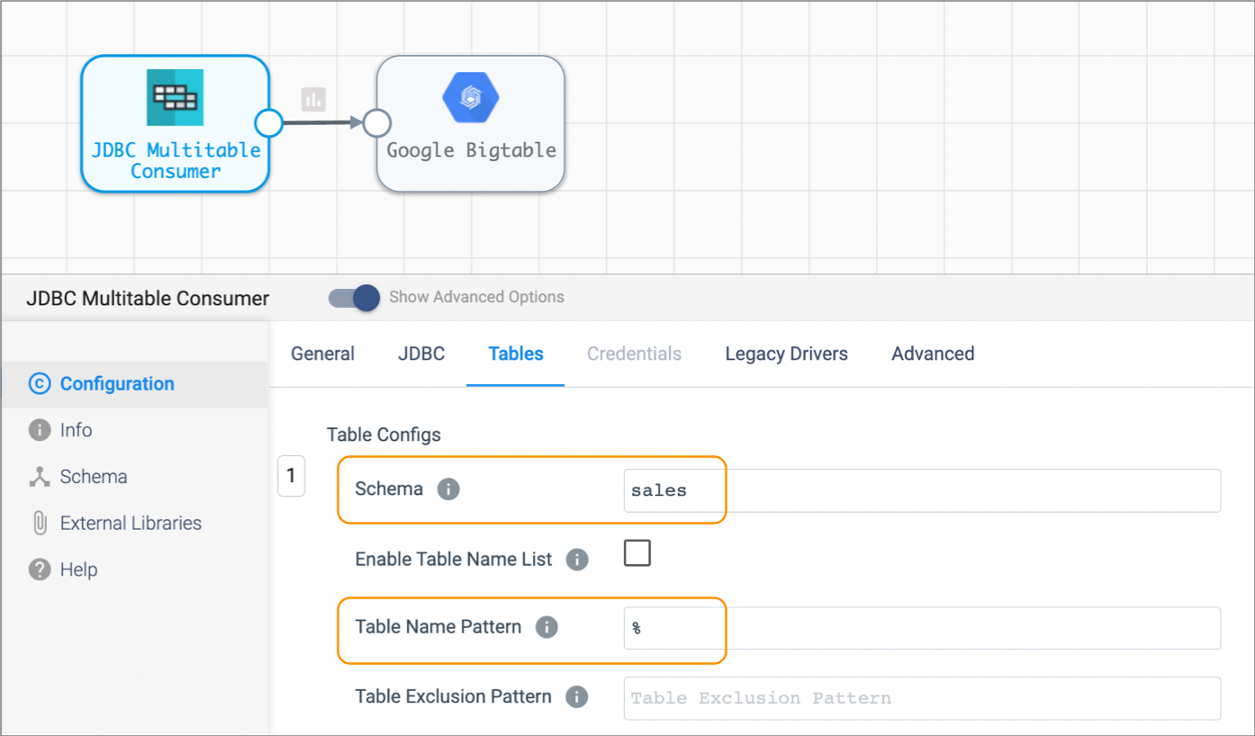
- Schema:
sales - Table Name Pattern:
SALES% - Exclusion Pattern:
SALES.*-.
Initial Change
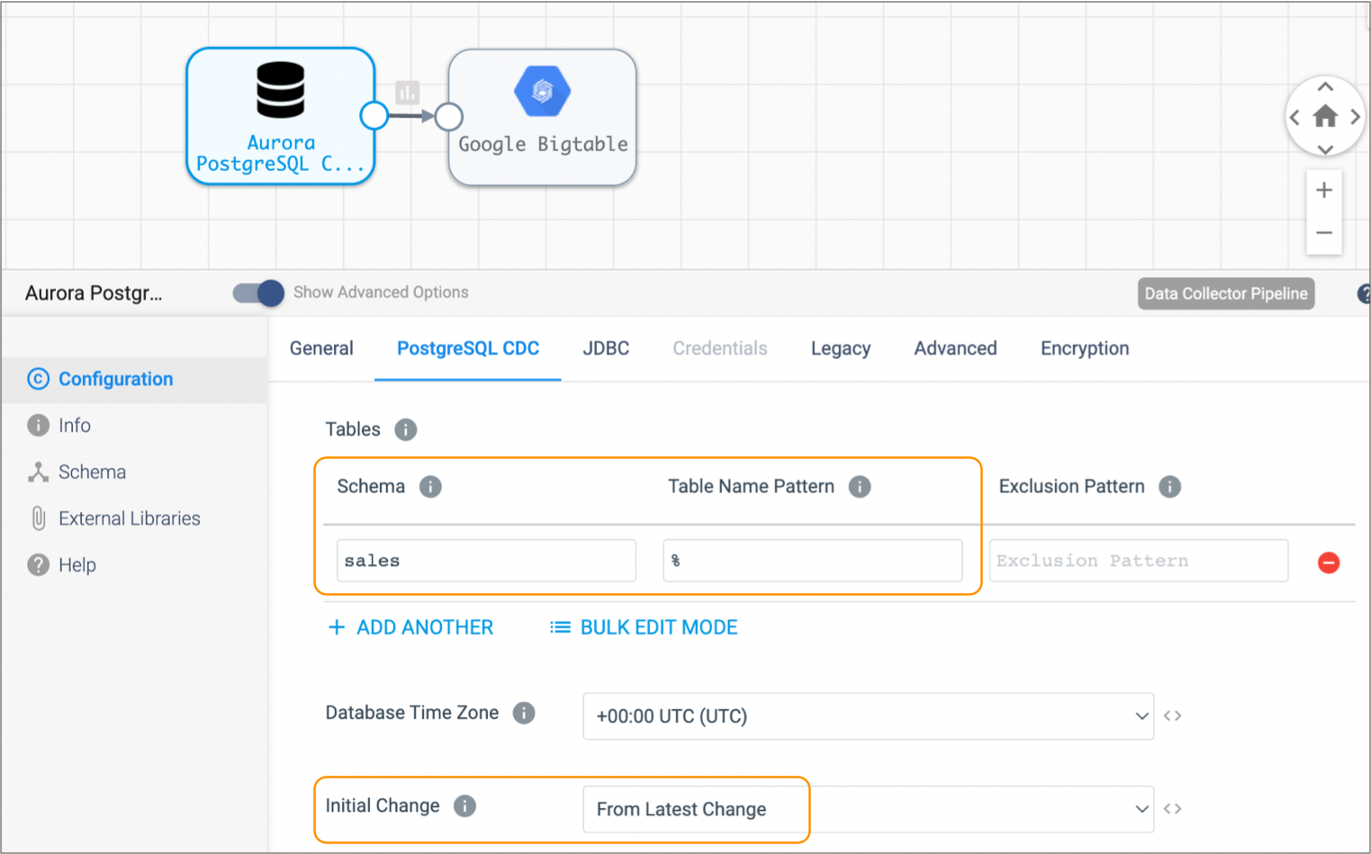
The initial change is the point in the Write-Ahead Logging (WAL) data where you want to start processing. When you start the pipeline for the first time, the origin starts processing from the specified initial change. The origin only uses the specified initial change again when you reset the origin.
Note that the Aurora PostgreSQL CDC Client origin processes only change capture data. If you need existing data, you might use a JDBC Query Consumer or a JDBC Multitable Consumer in a separate pipeline to read table data before you start an Aurora PostgreSQL CDC Client pipeline.
- From the latest change
- The origin processes all changes that occur after you start the pipeline.
- From a specified datetime
- The origin processes all changes that occurred at the specified datetime and
later. Use the following format:
DD-MM-YYYY HH24:MI:SS. - From a specified log sequence number (LSN)
- The origin processes all changes that occurred in the specified LSN and later. When using the specified LSN, the origin starts processing with the timestamp associated with the LSN. If the LSN cannot be found in the WAL data, the origin continues reading from the next higher LSN that is available.
Example
You want to process all existing data in the Sales schema and then capture changed data, writing all data to Google Bigtable. To do this, you create two pipelines.
To read the existing data from the schema, you use a pipeline with the JDBC Multitable Consumer and Google Bigtable destination as follows:
Once all existing data is read, you stop the JDBC Multitable Consumer pipeline and start the following Aurora PostgreSQL CDC Client pipeline. This pipeline is configured to pick up changes that occur after you start the pipeline, but if you wanted to prevent any chance of data loss, you could configure the initial change for an exact datetime or earlier LSN:
Memory Usage
The format of the data that the origin reads and the contents of the generated records affect the memory that the database and origin use.
- Wal2json Format
- Sets the format requested from the wal2json plugin. This becomes the format of the data that the origin reads. The format affects the memory used. Setting the format to Operation reduces the memory used, but note that this format requires wal2json plugin version 2.0 or later.
- Record Contents
- Sets the contents of the generated record. The origin can generate a record for each transaction or a record for each operation. The contents of the records affect the amount of processing required for each batch that the origin generates. Setting the contents to Transaction requires more processing and more memory use.
| Wal2json Format | Record Contents | Description |
|---|---|---|
| Operation | Operation | Origin reads data presented as single operations
and creates one record for each operation. Data Collector and the database consume the least memory. Recommended configuration. Requires using wal2json plugin version 2.0 or later. |
| Operation | Transaction | Not supported. Do not use. |
| Chunked Transaction | Operation | Origin reads data presented in chunks of
transactions and creates one record for each
operation. Data Collector and the database consume less memory. Recommended configuration in systems that cannot upgrade to wal2json plugin version 2.0. or later |
| Chunked Transaction | Transaction | Not supported. Do not use. |
| Transaction | Operation | Origin reads data presented as transactions and
creates one record for each operation. Data Collector and the database both consume memory. |
| Transaction | Transaction | Origin reads data presented as transactions and
creates one record for each transaction, which can
contain multiple operations. Data Collector and the database consume the most memory. This is the default configuration. |
SSL/TLS Encryption
You can secure the connection to the Aurora PostgreSQL database by configuring the origin to use SSL/TLS encryption.
Before configuring the origin to use SSL/TLS encryption, verify that the database is correctly configured to use SSL/TLS. For more information, see the Amazon Aurora PostgreSQL documentation.
Define one of the following SSL/TLS modes that the origin uses to connect to an Aurora PostgreSQL database:
- Disabled
- The stage does not establish an SSL/TLS connection.
- Required
- The stage establishes an SSL/TLS connection without any verification. The stage trusts the certificate and host name of the PostgreSQL server.
- Verify CA
- The stage establishes an SSL/TLS connection only after successfully verifying the certificate of the PostgreSQL server.
- Verify Full
- The stage establishes an SSL/TLS connection only after successfully verifying the certificate and host name of the PostgreSQL server.
-----BEGIN CERTIFICATE REQUEST-----
MIIB9TCCAWACAQAwgbgxGTAXBgNVHJoMEFF1b1ZlZGwzIEkpbWl0ZWLxHLAaBgNV
......
98TwDIK/39WEB/V607As+KoYajQL9drorw==
-----END CERTIFICATE REQUEST-----Record Contents and Generated Records
- Transaction
- The origin generates a record for each transaction, which can
include multiple CRUD operations. Because each record can
contain multiple operations, the origin does not write the CRUD
operations to the
sdc.operation.typerecord header attribute.If you want to pass records to a CRUD-enabled destination, you might use a scripting processor to convert the records as needed. Or, you might use a Field Pivoter processor and other processors to separate the data to create a record for each operation.
- Operation
- The origin generates a record for each operation. Because each
record contains a single operation, the origin writes the CRUD
operations to the
sdc.operation.typerecord header attribute. CRUD-enabled destinations can easily process generated records.
When you set Record Contents to Operation, generated records include fields that match the column names from the table.
| Field Name | Description |
|---|---|
| xid | Transaction ID. |
| nextlsn | Next Logical Sequence Number (LSN). |
| timestamp | Timestamp with sub-second granularity, including the time zone offset from UTC. |
| change | A list field that includes the following details about each data
change:
|
Record Header Attributes
The included record header attributes depend on the configured record contents of the Aurora PostgreSQL CDC Client origin.
Transaction Based Records
| CDC Header Attribute | Description |
|---|---|
| postgres.cdc.lsn | Logical Sequence Number of this record. |
| postgres.cdc.xid | Transaction ID. |
| postgres.cdc.timestamp | Timestamp of transaction. |
Operation Based Records
- Change data capture information
-
The origin includes the
sdc.operation.typerecord header attribute with the CRUD operation type.The origin also includes change data capture information in the following record header attributes:CDC Header Attribute Description postgres.cdc.lsn Logical Sequence Number of this record. postgres.cdc.xid Transaction ID. postgres.cdc.timestamp Timestamp of transaction. postgres.cdc.table Name of table. postgres.cdc.schema Name of schema. postgres.cdc.operation Operation type. - Primary key information
-
The origin includes the following record header attribute:
jdbc.primaryKeySpecification- Provides a JSON-formatted string that lists the columns that form the primary key in the table and the metadata for those columns.For example, a table with a composite primary key contains the following attribute:jdbc.primaryKeySpecification = {{"<primary key column 1 name>": {"type": <type>, "datatype": "<data type>", "size": <size>, "precision": <precision>, "scale": <scale>, "signed": <Boolean>, "currency": <Boolean> }}, ..., {"<primary key column N name>": {"type": <type>, "datatype": "<data type>", "size": <size>, "precision": <precision>, "scale": <scale>, "signed": <Boolean>, "currency": <Boolean> } } }A table without a primary key contains the attribute with an empty value:jdbc.primaryKeySpecification = {}
For an update operation on a table with a primary key, the origin also includes the following record header attributes:jdbc.primaryKey.before.<primary key column name>- Provides the old value for the specified primary key column.jdbc.primaryKey.after.<primary key column name>- Provides the new value for the specified primary key column.
Note: The origin provides the new and old values of the primary key columns regardless of whether the value changes.
Sample Records
Suppose the input data has a transaction with three different operations: insert, update, and delete. The generated records and record header attributes differ depending on how you configure the record contents of the Aurora PostgreSQL CDC Client origin.
Transaction Based Records
Header:
{
"postgres.cdc.timestamp":"2022-08-02 11:56:23.378604+02",
"postgres.cdc.xid":"528",
"postgres.cdc.lsn":"0/167F498"
}
Fields:
{
"xid":528,
"nextlsn":"0/167F6C0",
"timestamp":"2022-08-02 11:56:23.378604+02",
"change":[
{
"kind":"insert",
"schema":"public",
"table":"mytable",
"columnnames":[
"id",
"name"
],
"columntypes":[
"integer",
"character varying(20)"
],
"columnvalues":[
0,
"Jones"
]
},
{
"kind":"update",
"schema":"public",
"table":"mytable",
"columnnames":[
"id",
"name"
],
"columntypes":[
"integer",
"character varying(20)"
],
"columnvalues":[
1,
"Smith"
],
"oldkeys":{
"keynames":[
"id"
],
"keytypes":[
"integer"
],
"keyvalues":[
1
]
}
},
{
"kind":"delete",
"schema":"public",
"table":"mytable",
"oldkeys":{
"keynames":[
"id"
],
"keytypes":[
"integer"
],
"keyvalues":[
2
]
}
}
]
}Operation Based Records
- Record 1:
Header: { "sdc.operation.type":"1", "postgres.cdc.table":"mytable", "postgres.cdc.schema":"public", "postgres.cdc.lsn":"0/167F498", "jdbc.primaryKeySpecification":"{\"id\":{\"type\":4,\"datatype\":\"INTEGER\",\"size\":11,\"precision\":10,\"scale\":0,\"signed\":true,\"currency\":false}}", "postgres.cdc.timestamp":"2022-08-02 11:56:23.378604+02", "postgres.cdc.xid":"528", "postgres.cdc.operation":"I" } Fields: { "name":"Jones", "id":0 } - Record 2:
Header: { "sdc.operation.type":"3", "postgres.cdc.table":"mytable", "postgres.cdc.schema":"public", "postgres.cdc.lsn":"0/167F498", "jdbc.primaryKeySpecification":"{\"id\":{\"type\":4,\"datatype\":\"INTEGER\",\"size\":11,\"precision\":10,\"scale\":0,\"signed\":true,\"currency\":false}}", "postgres.cdc.timestamp":"2022-08-02 11:56:23.378604+02", "jdbc.primaryKey.before.id":"1", "jdbc.primaryKey.after.id":"1", "postgres.cdc.xid":"528", "postgres.cdc.operation":"U" } Fields: { "name":"Smith", "id":1 } - Record 3:
Header: { "sdc.operation.type":"2", "postgres.cdc.table":"mytable", "postgres.cdc.schema":"public", "postgres.cdc.lsn":"0/167F498", "jdbc.primaryKeySpecification":"{\"id\":{\"type\":4,\"datatype\":\"INTEGER\",\"size\":11,\"precision\":10,\"scale\":0,\"signed\":true,\"currency\":false}}", "postgres.cdc.timestamp":"2022-08-02 11:56:23.378604+02", "postgres.cdc.xid":"528", "postgres.cdc.operation":"D" } Fields: { "id":2 }
Configuring an Aurora PostgreSQL CDC Client Origin
Configure an Aurora PostgreSQL CDC Client origin to process WAL change data capture data for an Amazon Aurora PostgreSQL database.
Before you configure the origin, complete the prerequisite tasks.
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
-
On the PostgreSQL CDC tab, configure the following
properties:
PostgreSQL CDC Property Description Tables Tables to track. Specify related properties as needed. Using simple or bulk edit mode, click the Add icon to define another table configuration.
Schema Schema to use. You can enter a schema name or use SQL LIKE syntax to specify a set of schemas. Table Name Pattern Table name pattern that specifies the tables to track. You can enter a table name or use SQL LIKE syntax to specify a set of tables. Exclusion Pattern An optional table exclusion pattern to define a subset of tables to exclude. You can enter a table name or use a regular expression to specify a subset of tables to exclude. To view and configure this option, click Show Advanced Options.
Database Time Zone Time zone of the database. Initial Change The starting point for the read. When you start the pipeline for the first time, the origin starts processing from the specified initial change. The origin only uses the specified initial change again when you reset the origin. Use one of the following options:
- From Latest Change - Processes all changes that occur after you start the pipeline. If a replication slot exists, the origin first processes all existing data in the replication slot.
- From Date - Processes changes starting from the specified date.
- From LSN - Processes changes starting from the specified log sequence number.
Start Date The datetime to read from when you start the pipeline. Use the following format:
MM-DD-YYYY HH24:MI:SS.For a date-based initial change only.
Start LSN The log sequence number to start reading from when you start the pipeline. If the LSN cannot be found, the origin continues reading from the next higher LSN that is available. For an LSN-based initial change only.
Remove Replication Slot on Close Removes the replication slot when the pipeline stops, so the replication slot is only available during pipeline runs. Keeping the replication slot results in the continued production of WAL records for this slot, but may cause a degradation in performance.
Replication Slot Name for the replication slot. Include only lowercase letters and numbers. Default is
sdc.Operations Operations to include. Unsupported Field Type Action taken when the origin encounters unsupported data types in the record: - Send Record to Pipeline - The origin ignores unsupported data types and passes the record with only supported data types to the pipeline.
- Send Record to Error - The origin handles the record based on the error record handling configured for the stage. The error record contains only the supported data types.
- Discard Record - The origin discards the record.
Wal2json Format Format requested from the wal2json plugin:- Transaction
- Chunked Transaction
- Operation Note: Operation requires wal2json plugin version 2.0 or later.
The selected format affects memory usage.
Record Contents Contents in generated records:- Transaction - Origin generates a record for each transaction. Each record contains all the operations from that transaction.
- Operation - Origin generates a record for each operation. Each record contains one operation.
The record contents affect memory usage.
Batch Wait Time (ms) Number of milliseconds to wait before sending a partial or empty batch. Add Unsupported Fields Includes fields with unsupported data types in the record. When enabled, the origin adds the field name and passes the data as an unparsed string, when possible. Parse Datetimes Enables the origin to write timestamps as datetime values rather than as string values. Strings maintain the precision stored in the source database. Query Timeout Time to wait before timing out a WAL query and returning the batch. Default is
${ 5 * MINUTES }which is 300 seconds.Poll Interval Milliseconds to wait before checking for additional data. Default is 1,000 milliseconds, or 1 second.
Status Interval Interval between status updates. Use to ensure that the wal_sender process does not time out. This property should be set to less than the wal_sender_timeout property in the PostgreSQL
postgresql.conffile. Ideally, it should be set to half of the value of the wal_sender_timeout property.For example, you can use the default status interval of 30 seconds with the default wal_sender_timeout value of 60000 milliseconds, or 1 minute.
CDC Generator Queue Size Buffer size for storing records in memory before passing them downstream. Set this property larger than the maximum batch size.
-
On the JDBC tab, configure the following JDBC
properties:
JDBC Property Description Connection Connection that defines the information required to connect to an external system. To connect to an external system, you can select a connection that contains the details, or you can directly enter the details in the pipeline. When you select a connection, Control Hub hides other properties so that you cannot directly enter connection details in the pipeline.
To create a new connection, click the Add New Connection icon:
 . To view and edit the details of the
selected connection, click the Edit
Connection icon:
. To view and edit the details of the
selected connection, click the Edit
Connection icon:  .
.JDBC Connection String Connection string used to connect to the database.
Use the following format:
jdbc:postgresql:aws://<instance_name>.<cluster_id>.<aws_region>.rds.amazonaws.com:<port>/For example:
jdbc:postgresql:aws://instance.1234abcd.us-west-1.rds.amazonaws.com:1234/Note: If you include the JDBC credentials in the connection string, use a user account created for the origin. The user must have the required privileges for the database.Max Batch Size (records) Maximum number of records processed at one time. Honors values up to the Data Collector maximum batch size. Default is 1000. The Data Collector default is 1000.
Use Credentials Enables entering credentials. Use when you do not include credentials in the JDBC connection string.
Additional JDBC Configuration Properties Additional JDBC configuration properties to use. To add properties, click Add and define the JDBC property name and value. Use the property names and values as expected by JDBC.
-
If you configured the origin to enter JDBC credentials
separately from the JDBC connection string on the JDBC tab,
then configure the following properties on the Credentials
tab:
Credentials Property Description Username PostgreSQL username. The specified user must have the required role for the database.
Password PostgreSQL password. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores. -
When using JDBC versions older than 4.0, on the Legacy
Drivers tab, optionally configure the following
properties:
Legacy Drivers Property Description JDBC Class Driver Name Class name for the JDBC driver. Required for JDBC versions older than version 4.0. Connection Health Test Query Optional query to test the health of a connection. Recommended only when the JDBC version is older than 4.0. -
On the Advanced tab, optionally configure advanced
options.
The defaults for these properties should work in most cases:
Advanced Property Description Maximum Pool Size Maximum number of connections to create. Default is 1. The recommended value is 1.
Minimum Idle Connections Minimum number of connections to create and maintain. To define a fixed connection pool, set to the same value as Maximum Pool Size. Default is 1.
Connection Timeout (seconds) Maximum time to wait for a connection. Use a time constant in an expression to define the time increment. Default is 30 seconds, defined as follows:${30 * SECONDS}Idle Timeout (seconds) Maximum time to allow a connection to idle. Use a time constant in an expression to define the time increment. Use 0 to avoid removing any idle connections.
When the entered value is close to or more than the maximum lifetime for a connection, Data Collector ignores the idle timeout.
Default is 10 minutes, defined as follows:${10 * MINUTES}Max Connection Lifetime (seconds) Maximum lifetime for a connection. Use a time constant in an expression to define the time increment. Use 0 to set no maximum lifetime.
When a maximum lifetime is set, the minimum valid value is 30 minutes.
Default is 30 minutes, defined as follows:${30 * MINUTES}Enforce Read-only Connection Creates read-only connections to avoid any type of write. Default is enabled. Disabling this property is not recommended.
Transaction Isolation Transaction isolation level used to connect to the database. Default is the default transaction isolation level set for the database. You can override the database default by setting the level to any of the following:
- Read committed
- Read uncommitted
- Repeatable read
- Serializable
Init Query SQL query to perform immediately after the stage connects to the database. Use to set up the database session as needed. The query is performed after each connection to the database. If the stage disconnects from the database during the pipeline run, for example if a network timeout occurrs, the stage performs the query again when it reconnects to the database.
-
On the Encryption tab, configure the following
properties:
Encryption Property Description SSL Mode SSL/TLS mode used to connect to the PostgreSQL server: - Disabled - Does not establish an SSL/TLS connection.
- Required - Establishes an SSL/TLS connection without any verification.
- Verify CA - Establishes an SSL/TLS connection only after successfully verifying the certificate of the PostgreSQL server.
- Verify Full - Establishes an SSL/TLS connection only after successfully verifying the certificate and host name of the PostgreSQL server.
Server Certificate PEM Server certificate in PEM format used to verify the SSL/TLS certificate of the PostgreSQL server. Use a text editor to open the PEM encoded certificate, and then copy and paste the full contents of the file into the property, including the header and footer.
CA Certificate PEM CA certificate in PEM format used to verify the SSL/TLS certificate of the PostgreSQL server. Use a text editor to open the PEM encoded certificate, and then copy and paste the full contents of the file into the property, including the header and footer.