What is Control Hub?
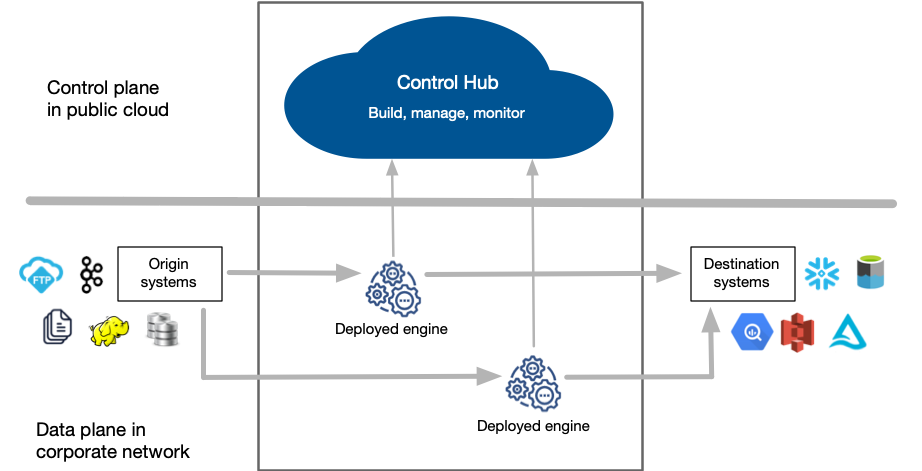
Control Hub serves as the central point of control for all of your data pipelines.
You access Control Hub using a web browser. You use Control Hub to deploy engines to your corporate network, which can be on-premises or on a protected cloud computing platform. You build and manage your pipelines in Control Hub, then run the pipelines on the deployed engines.
The engines use the pipeline configuration to process the data. As the pipelines run, the engines send status updates and metrics back to Control Hub so that you can monitor the pipeline progress in real time. Since pipelines run in your corporate network, you maintain all ownership and control of your data.
- IBM© StreamSets
- IBM StreamSets includes Control Hub and the Data Collector engine.
- IBM© StreamSets for Apache Spark
- IBM StreamSets for Apache Spark includes Control Hub and the Transformer engine.
- IBM© StreamSets for Snowflake
- IBM StreamSets for Snowflake includes Control Hub and the Transformer for Snowflake engine.
The following image provides a general overview of how Control Hub works with engines deployed to your corporate network: