Field Replacer
The Field Replacer processor replaces the values in fields with nulls or with new values. Use the Field Replacer processor to update values or to replace invalid values.
When you configure the processor, you define the replacement rules to use. You can replace all values in a specified field. You can also use a Spark SQL expression to generate the new field value.
If you define multiple replacement rules, the Field Replacer processor replaces values in the order that the rules are listed in the processor.
Replacing Values with Nulls
You can use the Field Replacer processor to replace all values in a field with null values.
To replace all values in a field with nulls, simply specify a field and then select Set to Null.
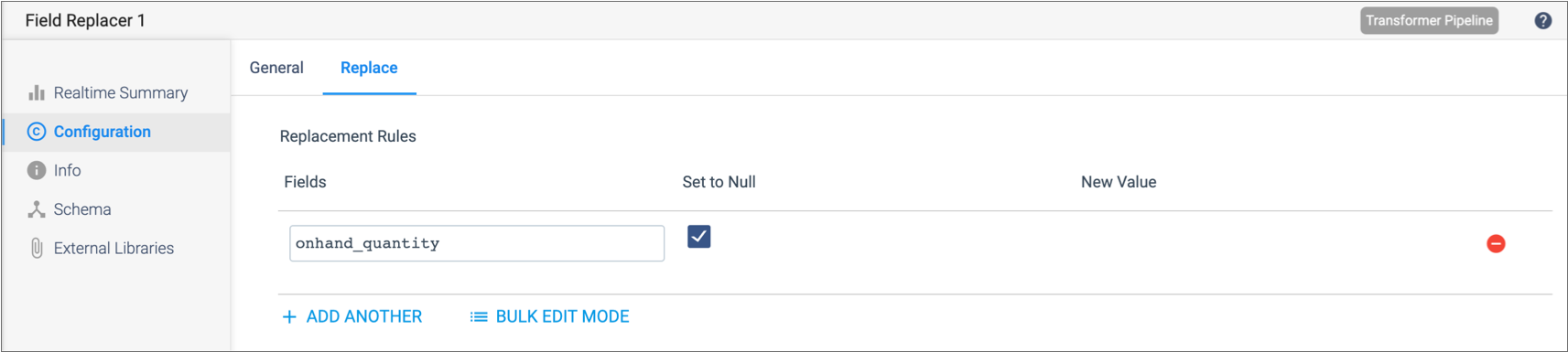
For example, the following configuration replaces all the values in the
onhand_quantity field with null:
Replacing Values with New Values
You can use the Field Replacer processor to replace the values in a field with new values.
To replace all values in a field with a single value, simply specify a field and then specify the new value. When you define the new value, you can enter a Spark SQL expression or a string. When specifying a string, enclose the value inside quotation marks.
- To replace the value in the
salaryfield with the double of its value, entersalary*2. - To replace the value in the
company_namefield with the string "MyCompany", enter"MyCompany". - To replace the value in the
onhand_quantityfield with the value of 100, enter100. - To replace the value in the
codefield with the string "012345", enter"012345".
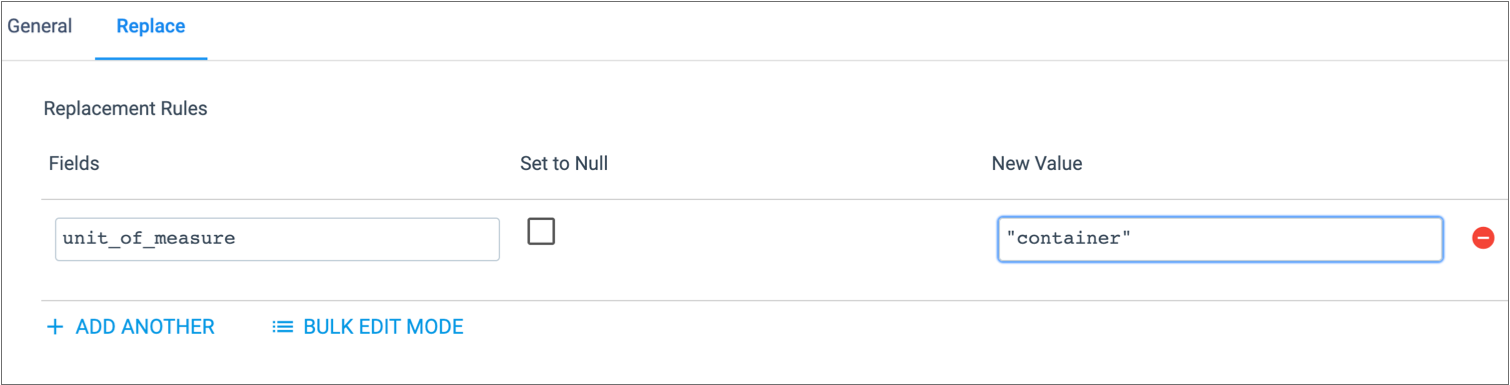
For example, the following configuration replaces all values in the
unit_of_measure field with the string container.
Because the new value is a string, it must be enclosed in quotation marks:
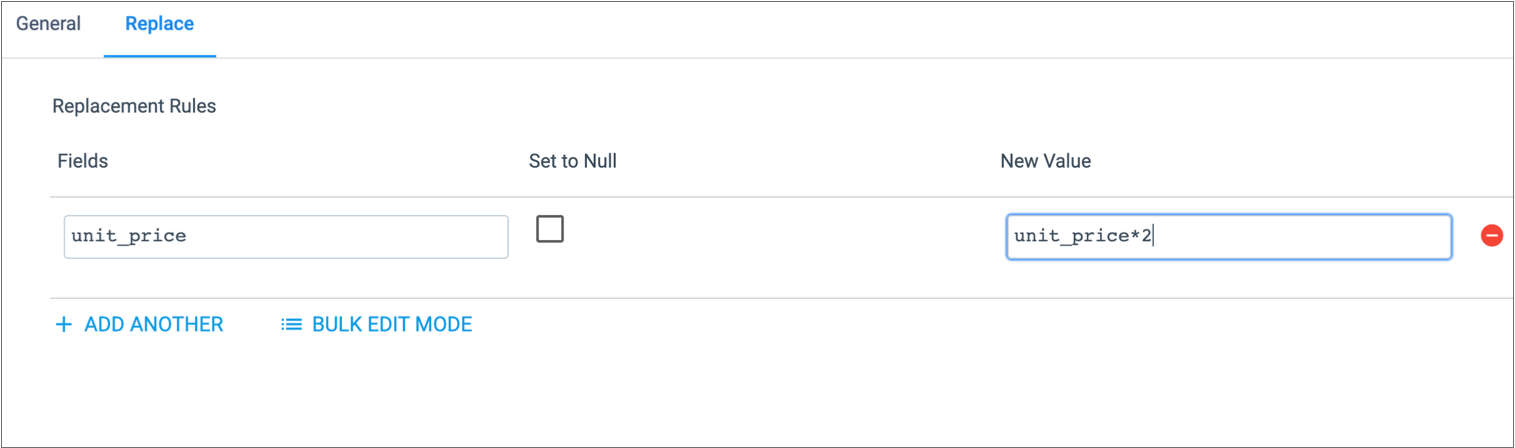
For example, the following configuration uses a Spark SQL expression to replace all the
values in the unit_price field with the double of its value:
Configuring a Field Replacer Processor
Configure a Field Replacer processor to replace field values with nulls or new values.
-
In the Properties panel, on the
General tab, configure the following properties:
General Property Description Name Stage name. Description Optional description. Cache Data Caches data processed for a batch so the data can be reused for multiple downstream stages. Use to improve performance when the stage passes data to multiple stages. Caching can limit pushdown optimization when the pipeline runs in ludicrous mode.
-
On the Replace tab, configure the following properties for each replacement
rule:
Replacement Rule Property Description Fields Field values to replace. Set to Null Replace the field values with nulls. New Value Replacement value to use. Enter either a Spark SQL expression or a string inside quotation marks. - Using simple or bulk edit mode, click the Add icon to add additional replacement rules.