XML Parser
The XML Parser processor parses an XML document in a string field and passes the parsed data to a map field in the output record.
When you configure the XML Parser processor, you specify the field that contains the XML document. You specify whether the processor replaces the data in the original field with the parsed data or passes the parsed data to another field. You also configure whether the processor stops the pipeline with an error or continues processing when the specified field to parse does not exist in a record.
You specify the schema that the processor uses to parse the XML document. The processor can infer the schema from the first record that it reads, or use a custom schema specified in JSON or DDL format.
Schema
- Infer from Data
- With the default mode, the XML Parser processor infers the schema from the
first incoming record. The XML document in the specified field in the first
record must include all fields in the schema.Tip: As you build the pipeline, verify that the processor infers the schema as expected. Previewing the pipeline is the easiest way to determine how the processor infers the schema.
- Use Custom Schema - JSON Format
- The XML Parser processor uses the custom schema that you specify in JSON format.
- Use Custom Schema - DDL Format
- The XML Parser processor uses the custom schema that you specify in DDL format.
Use a custom schema when the XML document in the first record does not include all the fields in the schema or when the processor infers the schema inaccurately.
JSON Schema Format
To use JSON to define a custom schema, specify the field names and data types within a root field that uses the Struct data type.
nullable attribute is required for most fields.{
"type": "struct",
"fields": [
{
"name": "<first field name>",
"type": "<data type>",
"nullable": <true|false>
},
{
"name": "<second field name>",
"type": "<data type>",
"nullable": <true|false>
}
]
}{
"name": "<list field name>",
"type": {
"type": "array",
"elementType": "<subfield data type>",
"containsNull": <true|false>
}
}{
"name": "<map field name>",
"type": {
"type": "struct",
"fields": [ {
"name": "<first subfield name>",
"type": "<data type>",
"nullable": <true|false>
}, {
"name": "<second subfield name>",
"type": "<data type>",
"nullable": <true|false>
} ] },
"nullable": <true|false>
}Example
{
"type": "struct",
"fields": [
{
"name": "TransactionID",
"type": "string",
"nullable": false
},
{
"name": "Verified",
"type": "boolean",
"nullable":false
},
{
"name": "User",
"type": {
"type": "struct",
"fields": [ {
"name": "ID",
"type": "long",
"nullable": true
}, {
"name": "Name",
"type": "string",
"nullable": true
} ] },
"nullable": true
},
{
"name": "Items",
"type": {
"type": "array",
"elementType": "string",
"containsNull": true},
"nullable":true
}
]
}order field contains the following XML
document:<root><Verified>true</Verified><Items>T-35089</Items><Items>M-00352</Items><Items>Q-11044</Items><TransactionID>G-23525-3350</TransactionID><User><ID>23005</ID><Name>Marnee Gehosephat</Name></User></root>The processor generates the following record when configured to replace the
order field with the parsed data:
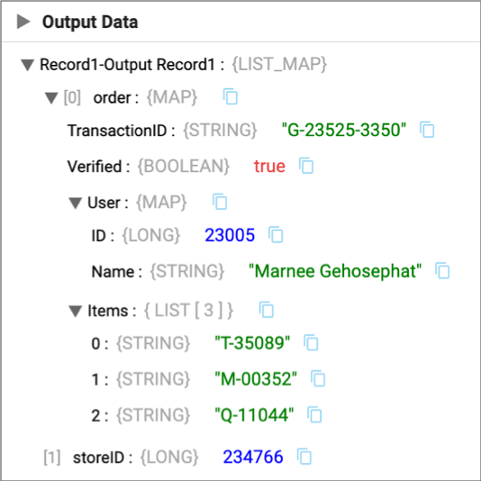
Notice the User Map field with the Long and String subfields and the
Items List field with String subfields. In addition, the order
of the fields now matches the order in the custom schema. Also note that any
remaining fields in the record are passed to the output record unchanged, the
storeID field in this example.
DDL Schema Format
<first field name> <data type>, <second field name> <data type>, <third field name> <data type><list field name> Array <subfields data type><map field name> Struct < <first subfield name>:<data type>, <second subfield name>:<data type> >`count`.Example
TransactionID String, Verified Boolean, User Struct <ID:Integer, Name:String>, Items Array <String>order field contains the following XML document:
<root><Verified>true</Verified><Items>T-35089</Items><Items>M-00352</Items><Items>Q-11044</Items><TransactionID>G-23525-3350</TransactionID><User><ID>23005</ID><Name>Marnee Gehosephat</Name></User></root>The processor generates the following record when configured to replace the
order field with the parsed data:
Notice the User Map field with the Long and String subfields and the
Items List field with String subfields. In addition, the order
of the fields now matches the order in the custom schema. Also note that any
remaining fields in the record are passed to the output record unchanged, the
storeID field in this example.
Schema Error Handling
- When the schema is not valid, the processor stops the pipeline with an error.
- When the specified field to parse does not include a valid XML document, the
processor handles the error based on the Error Handling configuration on the
Schema tab:
- Permissive - The processor writes the invalid XML in a
_corrupt_recordfield. - Drop Malformed - The processor drops the record from the pipeline and continues processing.
- Fail Fast - The processor stops the pipeline with an error.
- Permissive - The processor writes the invalid XML in a
- When the specified field to parse contains data that does not match the schema,
the processor handles the error based on how the XML document differs from the schema:
XML Document Error handling Includes a field not defined in the schema The processor ignores the field, dropping it from the output record. Omits a field defined in the schema The processor passes the field to the output record with a null value. Includes data in a field not compatible with the data type defined in the schema The processor handles the error based on the Error Handling configuration on the Schema tab: - Permissive - The processor passes the field with a null value to the output record and continues processing.
- Drop Malformed - The processor drops the record from the pipeline and continues processing.
- Fail Fast - The processor stops the pipeline with an error.
Configuring an XML Parser Processor
Configure an XML Parser processor to parse an XML document in a string field.
-
In the Properties panel, on the
General tab, configure the following properties:
General Property Description Name Stage name. Description Optional description. Cache Data Caches data processed for a batch so the data can be reused for multiple downstream stages. Use to improve performance when the stage passes data to multiple stages. Caching can limit pushdown optimization when the pipeline runs in ludicrous mode.
-
On the XML Parser tab, configure the following
properties:
XML Parser Property Description XML Field Field that contains the XML document to parse. Replace Field Replaces the XML document in the field with the parsed data. Output Field Field where the processor writes the parsed data. You can specify an existing field or a new field. If the field does not exist, the XML Parser processor creates the field.
Available when Replace Field is cleared.
Fail if Missing Stops the pipeline with an error if the specified XML field does not exist in a record. When cleared, the processor passes the record to the next stage and then continues processing.
-
On the Schema tab, configure the following
properties:
Schema Property Description Schema Mode Mode that determines the schema to use when processing data: - Infer from Data
The processor infers the field names and data types from the data.
- Use Custom Schema - JSON Format
The processor uses a custom schema defined in the JSON format.
- Use Custom Schema - DDL Format
The processor uses a custom schema defined in the DDL format.
Schema Custom schema to use to process the data. Enter the schema in JSON or DDL format, depending on the selected schema mode.
Error Handling Determines how the stage handles errors when the field to parse contains invalid XML or when a field in the XML document is not compatible with the data type defined in the schema: - Permissive - Either writes the invalid XML in a
_corrupt_recordfield or passes the field with a null value to the output record; continues processing. - Drop Malformed - Drops the record from the pipeline and continues processing.
- Fail Fast - Stops the pipeline with an error.
- Infer from Data