Pivot
The Pivot processor pivots a list field and creates a record for each item in the field. When you configure the Pivot processor, you specify the list field to pivot and where to write the pivoted data. The processor writes the pivoted data to the new field that you specify. You can also specify whether to keep the existing field. The Pivot processor supports the pivoting of multiple fields.
Generated Records
When you pivot a field, the Pivot processor creates a new record for each first-level item in the list.
When pivoting a field, you can include the existing fields in the record or drop them, using only the pivoted data in the new records.
- Incoming data
- Say you have the following data sample, and you want to pivot the
metadata_authorsdata:{ "metadata_authors": [ { "affiliation": { "institution": "University of Toronto", "laboratory": "", "location": {} }, "email": "", "first": "Andrea", "last": "Leung", "middle": [ "S" ], "suffix": "" }, { "affiliation": { "institution": "University of Toronto", "laboratory": "", "location": {} }, "email": "vanessa.tran@utoronto.ca", "first": "Vanessa", "last": "Tran", "middle": [], "suffix": "" } ], "metadata_title": "BMC Genomics Novel genome polymorphisms in BCG vaccine strains and impact on efficacy" } - Pivot to new field, keep existing field
- If you configure the processor to pivot the
metadata_authorsfield to a new field calledauthorand keep the existing field, the Pivot processor adds theauthorfield at the same level while keeping themetadata_authorsfield, as follows: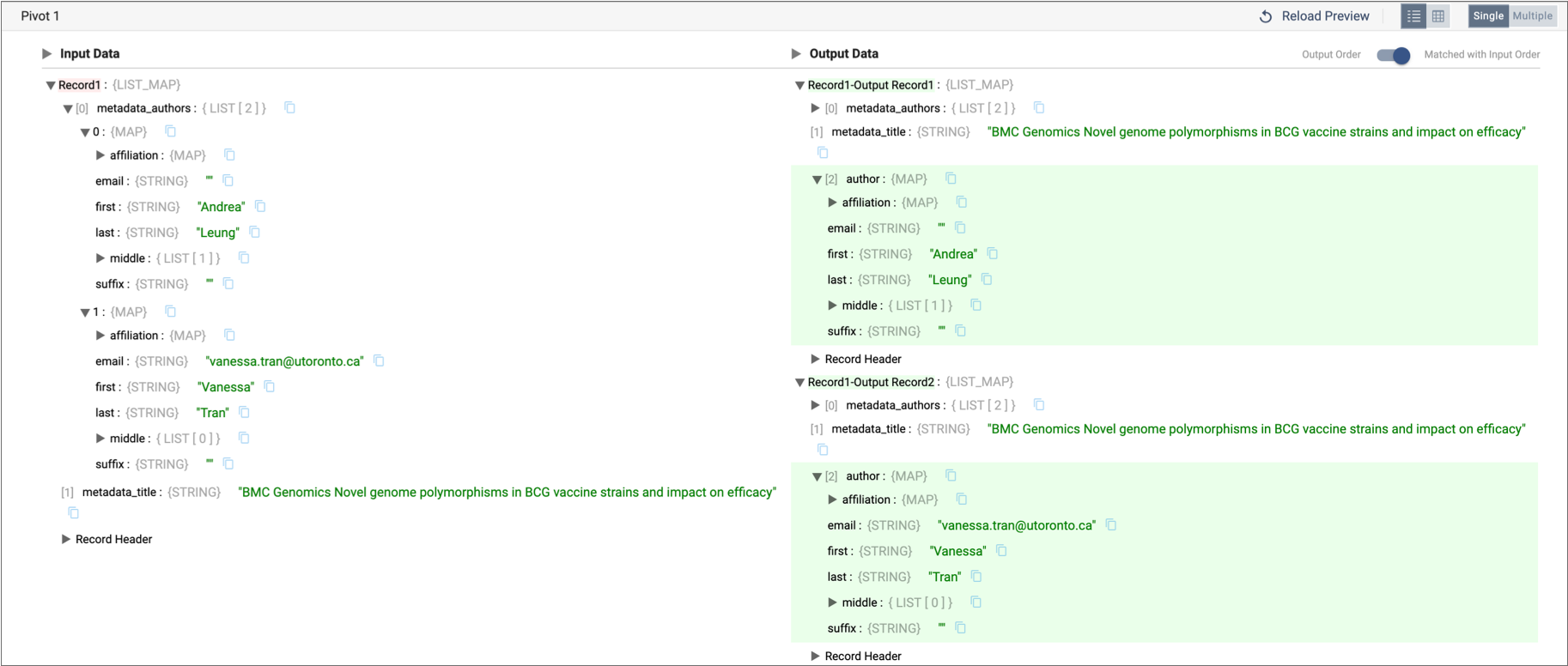
- Pivot to new field, drop existing field
- If you configure the processor to pivot the
metadata_authorsfield to a new field calledauthorand drop the existing field, the Pivot processor adds theauthorfield at the same level while dropping themetadata_authorsfield, as follows: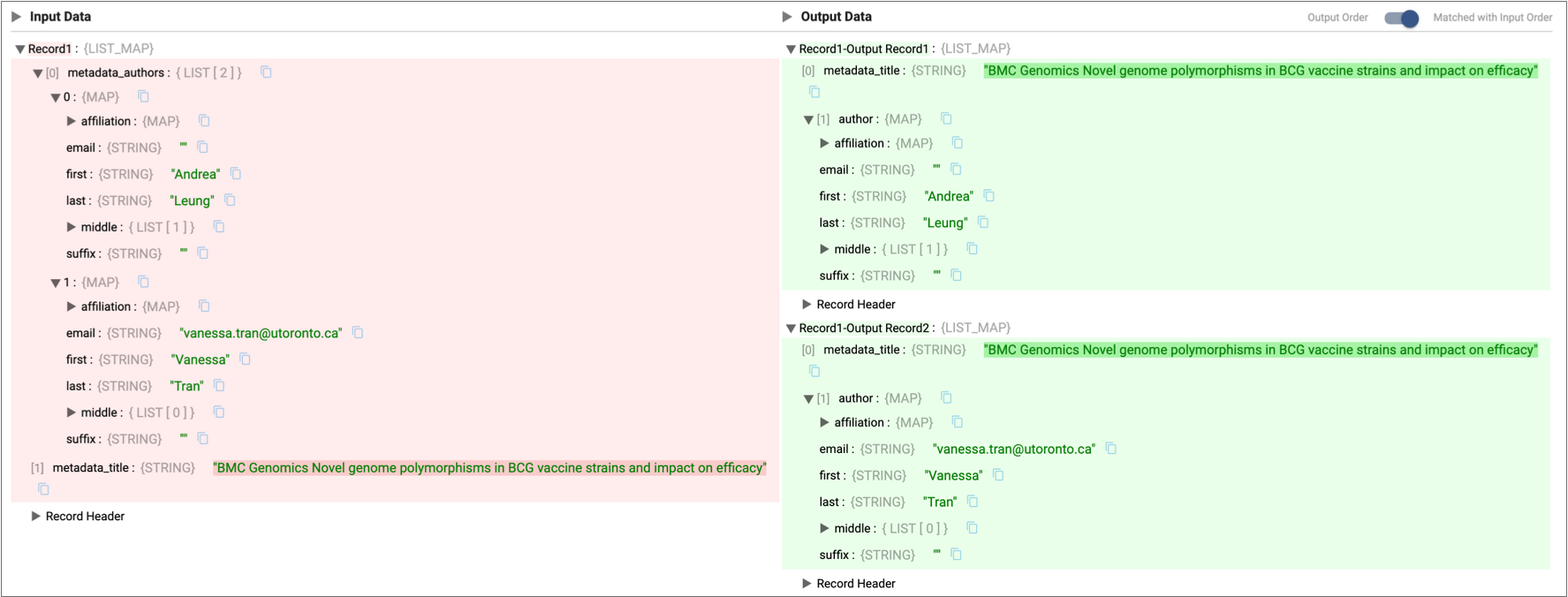
Configuring a Pivot Processor
Configure a Pivot processor to pivot data in a list field and generate a record for each item in the field. You can specify multiple fields to pivot.
-
In the Properties panel, on the
General tab, configure the following properties:
General Property Description Name Stage name. Description Optional description. Cache Data Caches data processed for a batch so the data can be reused for multiple downstream stages. Use to improve performance when the stage passes data to multiple stages. Caching can limit pushdown optimization when the pipeline runs in ludicrous mode.
-
On the Pivot tab, configure the following
properties:
Pivot Property Description Field to Pivot List field to pivot. New Field Name New field name for the records generated by the pivot. Keep Pivoted Field Select to keep the original field in the generated output. - Click the Add icon to specify additional pivots. The processor pivots the fields in the specified order.