Ludicrous Processing Mode
You can configure Transformer to run a pipeline in ludicrous processing mode.
When running a pipeline in ludicrous processing mode, Transformer leverages Spark's ability to perform predicate and filter pushdown to optimize queries. In ludicrous mode, Spark evaluates the processing configured across the pipeline and optimizes the query so that unnecessary data is not read. The pipeline processing can similarly be merged or reordered for peak efficiency, so the processing does not follow the stage-by-stage description in the pipeline canvas. This generally results in improved pipeline performance, but stage-related statistics are naturally unavailable.
In standard processing mode, Transformer also attempts to optimize queries, but not as aggressively as in ludicrous mode. Also, pipeline processing occurs essentially as specified in the pipeline, with data passing from stage to stage as processing completes.
For example, say you build the following batch pipeline to read all transactions and use a Filter transformation to remove all non-European Union transactions. Then, a Stream Selector passes transactions for sales and returns to different processing streams while dropping even-exchange transactions.
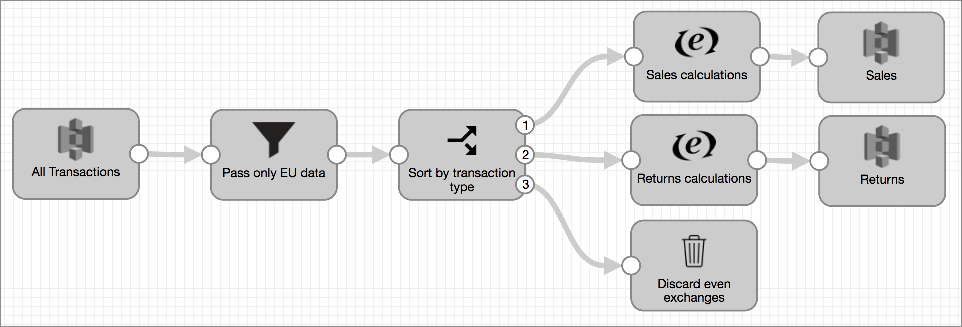
In standard mode, Transformer can include some pushdown optimization when reading from the origin system. Then, it performs the processing specified in the Filter processor, then the processing in the Stream Selector, and so on, through all stages until the data is written to destination systems.
In ludicrous mode, instead of passing data through the pipeline stage-by-stage, Transformer pushes the filtering performed by the Filter, Stream Selector, and Trash stages down to the initial read of source data. As a result, Transformer only reads the data that is used for pipeline processing – EU sales and return data – then performs the required processing. This can vastly improve pipeline performance.
To enable ludicrous mode, select the Enable Ludicrous Mode property on the General tab of pipeline properties.
Caching Support
Ludicrous mode honors all caching configured within the pipeline. However, note that enabling caching may limit the optimization that ludicrous mode would otherwise perform.
For more information about caching, see Caching Data.
Statistics
Since ludicrous mode does not perform typical stage-by-stage pipeline processing, by default, this mode provides only pipeline input and output statistics when you monitor a pipeline. Do not use ludicrous mode when you require stage-level statistics.
When you monitor a pipeline running in ludicrous mode, the input and output record counts display in the Record Count chart for the pipeline. Related statistics also display for the origin.