ADLS Gen2
The ADLS Gen2 destination writes files to Microsoft Azure Data Lake Storage Gen2.
The destination writes data based on the specified data format and creates a separate file for every partition. Before you use the ADLS Gen2 destination, you must perform some prerequisite tasks.
When you configure the ADLS Gen2 destination, you specify the Azure authentication method to use and related properties. Or, you can have the destination use Azure authentication information configured in the cluster where the pipeline runs.
You specify the output directory and write mode to use. You can configure the destination to group partition files by field values. If you configure the destination to overwrite related partitions, you must configure Spark to overwrite partitions dynamically. You can also configure the destination to drop unrelated master records when using the destination as part of a slowly changing dimension pipeline.
You select the data format to write and configure related properties.
Prerequisites
- If necessary, create a new Azure Active Directory
application for Transformer.
For information about creating a new application, see the Azure documentation.
- Ensure that the
Azure Active Directory Transformer application
has the appropriate access control to perform the necessary tasks.
To write to Azure, the Transformer application requires Write and Execute permissions. If also reading from Azure, the application requires Read permission as well.
For information about configuring Gen2 access control, see the Azure documentation.
- Install the Azure Blob File System driver on the cluster where the pipeline
runs.
Most recent cluster versions include the Azure Blob File System driver,
azure-datalake-store.jar. However, older versions might require installing it. For more information about Azure Data Lake Storage Gen2 support for Hadoop, see the Azure documentation. - Retrieve Azure Data Lake Storage Gen2 authentication information from the Azure
portal for configuring the origin.
You can skip this step if you want to use Azure authentication information configured in the cluster where the pipeline runs.
- Before using the stage in a local pipeline, ensure that Hadoop-related tasks are complete.
Retrieve Authentication Information
The ADLS Gen2 destination provides several ways to authenticate connections to Azure. Depending on the authentication method that you use, the destination requires different authentication details.
If the cluster where the pipeline runs has the necessary Azure authentication information configured, then the destination uses that information by default. However, data preview is not available when using Azure authentication information configured in the cluster.
You can also specify Azure authentication information in stage properties. Any authentication information specified in stage properties takes precedence over the authentication information configured in the cluster.
- OAuth
- When connecting using OAuth authentication, the destination requires the
following information:
- Application ID - Application ID for the Azure Active
Directory Transformer
application. Also known as the client ID.
For information on accessing the application ID from the Azure portal, see the Azure documentation.
- Application Key - Authentication key for the Azure
Active Directory Transformer application. Also known as the client key.
For information on accessing the application key from the Azure portal, see the Azure documentation.
- OAuth Token Endpoint - OAuth 2.0 token endpoint for
the Azure Active Directory v1.0 application for Transformer. For example:
https://login.microsoftonline.com/<uuid>/oauth2/token.
- Application ID - Application ID for the Azure Active
Directory Transformer
application. Also known as the client ID.
- Managed Service Identity
- When connecting using Managed Service Identity authentication, the
destination requires the following information:
- Application ID - Application ID for the Azure Active
Directory Transformer
application. Also known as the client ID.
For information on accessing the application key from the Azure portal, see the Azure documentation.
- Tenant ID - Tenant ID for the Azure Active Directory
Transformer
application. Also known as the directory ID.
For information on accessing the tenant ID from the Azure portal, see the Azure documentation.
- Application ID - Application ID for the Azure Active
Directory Transformer
application. Also known as the client ID.
- Shared Key
- When connecting using Shared Key authentication, the destination requires
the following information:
- Account Shared Key - Shared access key that Azure
generated for the storage account.
For more information on accessing the shared access key from the Azure portal, see the Azure documentation.
- Account Shared Key - Shared access key that Azure
generated for the storage account.
Write Mode
The write mode determines how the ADLS Gen2 destination writes files to the destination system. When writing files, the resulting file names are based on the data format of the files.
- Overwrite files
- Before writing data from a batch, the destination removes all files from the output directory and any subdirectories.
- Overwrite related partitions
- Before writing data from a batch, the destination
removes the files from subdirectories for which the batch has data. The
destination leaves subdirectories intact if the batch has no data for that
subdirectory.
For example, say you have a directory with ten subdirectories. If the processed data belongs in two subdirectories, the destination overwrites the two subdirectories with the new data. The other eight subdirectories remain unchanged.
Use this mode to overwrite only affected files, like when writing to a slowly changing grouped file dimension.
The Partition by Fields property specifies the fields used to create subdirectories. With no specified fields, the destination creates no subdirectories and this mode works the same as the Overwrite Files mode.
- Write new files to new directory
- When the pipeline starts, the destination creates the output directory and writes new files to that directory. Before writing data for each subsequent batch during the pipeline run, the destination removes all files from the directory and any subdirectories. The destination generates an error if the output directory exists when the pipeline starts.
- Write new or append to existing files
- The destination creates new files if the files do not exist, or appends data to existing files if the files already exist in the output directory or subdirectory.
Spark Requirement to Overwrite Related Partitions
If you set Write Mode to Overwrite Related Partitions, you must configure Spark to overwrite partitions dynamically.
Set the Spark configuration property
spark.sql.sources.partitionOverwriteMode to
dynamic.
You can configure the property in Spark, or you
can configure the property in individual pipelines. For example, you might set the
property to dynamic in Spark when you plan to enable the Overwrite
Related Partitions mode in most of your pipelines, and then set the property to
static in individual pipelines that do not use that mode.
To configure the property in an individual pipeline, add an extra Spark configuration property on the Cluster tab of the pipeline properties.
Partition Files
Pipelines process data in partitions. The ADLS Gen2 destination writes files, which contain the processed data, in the configured output directory. The destination writes one file for each partition.
The destination groups the partition files if you specify one or more fields in the Partition by Fields property. For each unique value of the fields specified in the Partition by Fields property, the destination creates a subdirectory. In each subdirectory, the destination writes one file for each partition that has the corresponding field and value. Because the subdirectory name includes the field name and value, the file omits that data. With grouped partition files, you can more easily find data with certain values, such as all the data for a particular city.
To overwrite subdirectories that have updated data and leave other subdirectories intact, set the Write Mode property to Overwrite Related Partitions. Then, the destination clears affected subdirectories before writing, replacing files in those subdirectories with new files.
If the Partition by Fields property lists no fields, the destination does not group partition files. Instead, the destination writes one file for each partition directly in the output directory.
Because the text data format only contains data from one field, the destination does not group partition files for the text data format. Do not configure the Partition by Fields property if the destination writes in the text data format.
Example: Grouping Partition Files
Suppose your pipeline processes orders. You want to write data in the Sales directory and group the data by cities. Therefore, in the Directory Path property, you enter Sales, and in the Partition by Fields property, you enter City. Your pipeline is a batch pipeline that only processes one batch. You want to overwrite the entire Sales directory each time you run the pipeline. Therefore, in the Write Mode property, you select Overwrite Files.
As the pipeline processes the batch, the origins and processors lead Spark to split the data into three partitions. The batch contains two values in the City field: Oakland and Fremont. Before writing the processed data in the Sales directory, the destination removes any existing files and subdirectories and then creates two subdirectories, City=Oakland and City=Fremont. In each subdirectory, the destination writes one file for each partition that contains data for that city, as shown below:
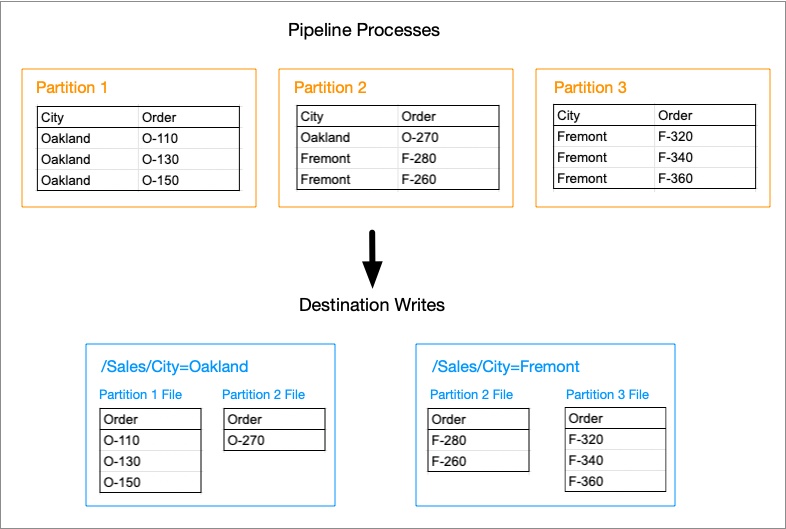
Note that the written files do not include the City field; instead, you infer the city from the subdirectory name. The first partition does not include any data for Fremont; therefore, the City=Fremont subdirectory does not contain a file from the first partition. Similarly, the third partition does not include any data for Oakland; therefore, the City=Oakland subdirectory does not contain a file from the third partition.
Data Formats
The ADLS Gen2 destination writes records based on the specified data format.
- Avro
- The destination writes an Avro file for each partition and includes the Avro schema in each file.
- Delimited
- The destination writes a delimited file for each
partition. It creates a header line for each file and uses
\nas the newline character. You can specify a custom delimiter, quote, and escape character to use in the data. - JSON
- The destination writes a file for each partition and writes each record on a separate line. For more information, see the JSON Lines website.
- ORC
- The destination writes an ORC file for each partition.
- Parquet
- The destination writes a Parquet file for each partition and includes the Parquet schema in every file.
- Text
- The destination writes a text file for every partition and
uses
\nas the newline character. - XML
- The destination writes an XML file for every partition. You specify the root and row tags to use in output files.
Configuring an ADLS Gen2 Destination
Configure an ADLS Gen2 destination to write files to Azure Data Lake Storage Gen2. Before you use the destination in a pipeline, complete the required prerequisites.
-
On the General tab, configure the following
properties:
General Property Description Name Stage name. Description Optional description. Stage Library Stage library to use: - ADLS cluster-provided libraries - The cluster where the pipeline runs has Apache Hadoop Azure Data Lake libraries installed, and therefore has all of the necessary libraries to run the pipeline.
- ADLS Transformer-provided libraries - Transformer passes the necessary libraries with the pipeline
to enable running the pipeline.
Use when running the pipeline locally or when the cluster where the pipeline runs does not include the Apache Hadoop Azure Data Lake libraries.
Select the appropriate version for your cluster.
Note: When using additional ADLS stages in the pipeline, ensure that they use the same stage library. -
On the ADLS tab, configure the following properties:
ADLS Property Description Storage Account Azure Data Lake Storage Gen2 storage account name. File System Name of the file system to use. OAuth Provider Type Authentication method to use to connect to Azure: - OAuth - Use to run pipelines locally. Can also be used to run pipelines on a cluster.
- Managed Service Identity - Can be used to run pipelines on a cluster.
- Shared Key - Can be used to run pipelines on a cluster.
Application ID Application ID for the Azure Active Directory Transformer application. Also known as the client ID. When not specified, the stage uses the equivalent Azure authentication information configured in the cluster where the pipeline runs.
For information on accessing the application ID from the Azure portal, see the Azure documentation.
Available when using the OAuth or Managed Service Identity authentication methods.Application Key Authentication key for the Azure Active Directory Transformerapplication. Also known as the client key. When not specified, the stage uses the equivalent Azure authentication information configured in the cluster where the pipeline runs.
For information on accessing the application key from the Azure portal, see the Azure documentation.
Available when using the OAuth authentication method.OAuth Token Endpoint OAuth 2.0 token endpoint for the Azure Active Directory v1.0 application for Transformer. For example: https://login.microsoftonline.com/<uuid>/oauth2/token.When not specified, the stage uses the equivalent Azure authentication information configured in the cluster where the pipeline runs.
Available when using the OAuth authentication method.
Tenant ID Tenant ID for the Azure Active Directory Transformer application. Also known as the directory ID. When not specified, the stage uses the equivalent Azure authentication information configured in the cluster where the pipeline runs.
For information on accessing the tenant ID from the Azure portal, see the Azure documentation.
Available when using the Managed Service Identity authentication method.Account Shared Key Shared access key that Azure generated for the storage account. When not specified, the stage uses the equivalent Azure authentication information configured in the cluster where the pipeline runs.
For more information on accessing the shared access key from the Azure portal, see the Azure documentation.
Available when using the Shared Key authentication method.Directory Path Path to the output directory where the destination writes files. Use the following format:
/<path to files>/The destination creates the directory if it doesn’t exist. The authentication credentials used to connect to Azure must have write access to the root of the specified directory path.
Write Mode Mode to write files: - Overwrite files - Removes all files from the output directory and any subdirectories.
- Overwrite related partitions - Removes the files from subdirectories for which the batch has data.
- Write new or append to existing files - Creates new files or appends data to existing files.
- Write new files to new directory - Creates the output directory and writes new files to that directory.
Additional Configuration Additional HDFS properties to pass to an HDFS-compatible file system. Specified properties override those in Hadoop configuration files.
To add properties, click the Add icon and define the HDFS property name and value. You can use simple or bulk edit mode to configure the properties. Use the property names and values as expected by your version of Hadoop.
Partition by Fields Fields used to group partition files. The destination creates a subdirectory for each unique field value and writes a file in the subdirectory for each processed partition that contains the corresponding field and value. In a file dimension pipeline that writes to a grouped file dimension, specify the fields that are listed in the Key Fields property of the Slowly Changing Dimension processor.
Exclude Unrelated SCD Master Records -
On the Data Format tab, configure the following
property:
Data Format Property Description Data Format Format of the data. Select one of the following formats: - Avro
- Delimited
- JSON
- ORC
- Parquet
- Text
- XML
-
For delimited data, on the Data Format tab, configure the
following property:
Delimited Property Description Delimiter Character Delimiter character to use in the data. Select one of the available options or select Other to enter a custom character. You can enter a Unicode control character using the format \uNNNN, where N is a hexadecimal digit from the numbers 0-9 or the letters A-F. For example, enter \u0000 to use the null character as the delimiter or \u2028 to use a line separator as the delimiter.
Quote Character Quote character to use in the data. Escape Character Escape character to use in the data -
For text data, on the Data Format tab, configure the
following property:
Text Property Description Text Field String field in the record that contains the data to be written. All data must be incorporated into the specified field. -
For XML data, on the Data Format tab, configure the
following properties:
XML Property Description Root Tag Tag to use as the root element. Default is ROWS, which results in a <ROWS> root element.
Row Tag Tag to use as a record delineator. Default is ROW, which results in a <ROW> record delineator element.