Connections
Section Contents
Connections#
A Connection defines the information required to connect to an external system. Rather than providing these details repeatedly in every pipeline that accesses the same system, a Connection can be created to store those details centrally and can be reused across multiple pipelines.
For more details, refer to the StreamSets Platform Documentation.
Retrieving Existing Connections#
You can view all existing Connections on the Platform by navigating to the Connections section of the UI as seen below:
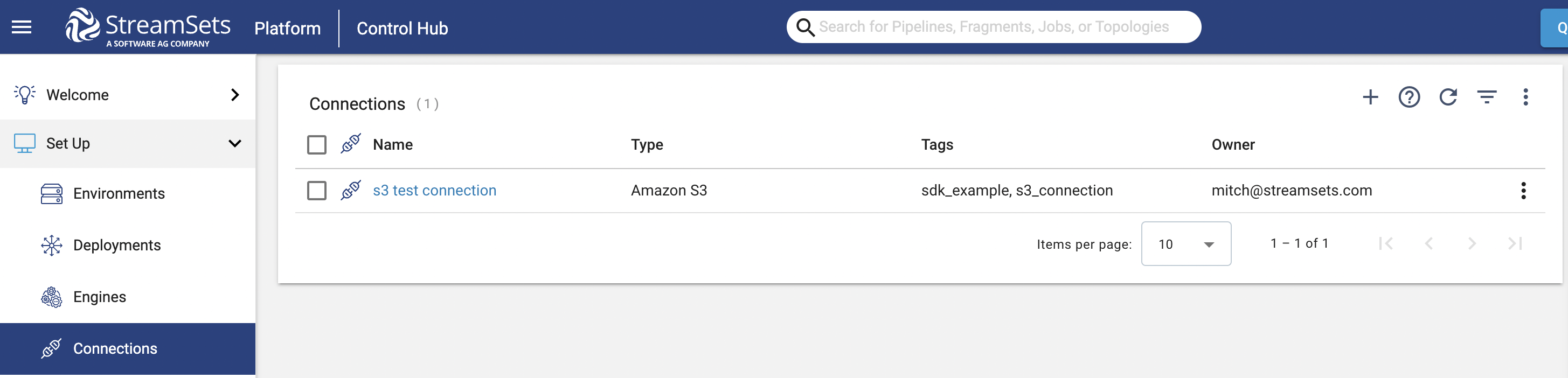
To retrieve all existing Connections using the SDK, you can reference the streamsets.sdk.ControlHub.connections attribute.
You can further filter the available Connections on attributes like name, connection_type and id to retrieve specific Connection(s):
# Retrieve all existing connections
sch.connections
# Retrieve all connections with JDBC type
sch.connections.get_all(connection_type='STREAMSETS_JDBC')
# Retrieve a connection with the name 'amazon s3 connection'
sch.connections.get(name='amazon s3 connection')
# Retrieve a connection with a specific id
sch.connections.get(id='350020cf-eff6-428a-8484-7078edf532c6:791759af-e8b5-11eb-8015-e592a7dbb2d0')
Creating a New Connection#
In the Platform UI, a Connection can be created from the Connections section by clicking “Add” and following the prompts:
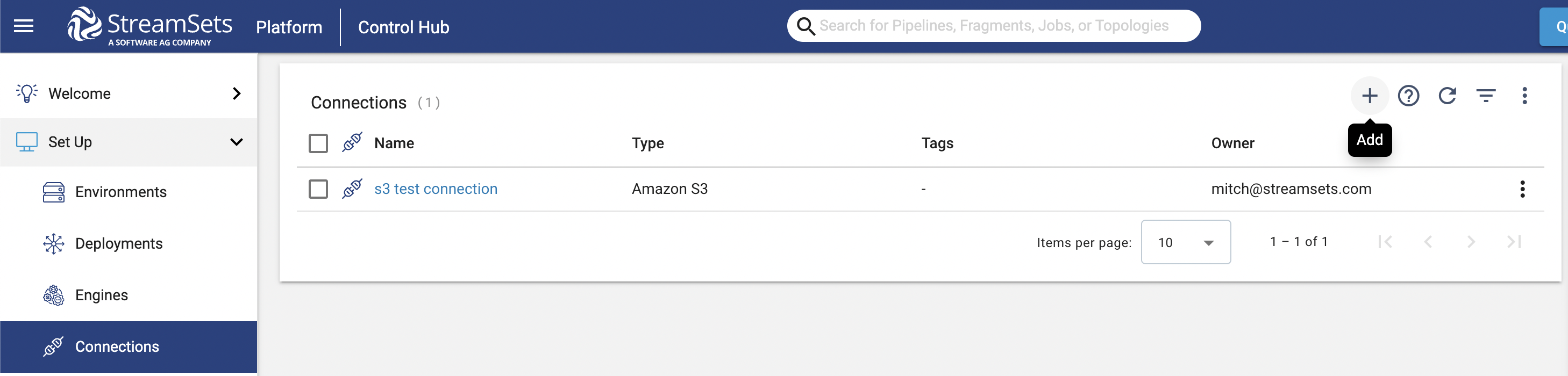
To create a new Connection and add it to the Platform via the SDK, you will need to use the streamsets.sdk.sch_models.ConnectionBuilder class.
To instantiate a builder instance, use the streamsets.sdk.ControlHub.get_connection_builder() method.
Once you’ve instantiated the builder, you will call the streamsets.sdk.sch_models.ConnectionBuilder.build() method, along with a few parameters, to create the desired streamsets.sdk.sch_models.Connection instance.
The parameters you’ll need to provide for the Connection are title, connection_type, authoring_data_collector (optional), and tags (optional) to associate with the Connection:
# Instantiate the ConnectionBuilder instance
connection_builder = sch.get_connection_builder()
# Retrieve the Data Collector engine to be used as the authoring engine
engine = sch.engines.get(engine_url='<engine_url>')
# Build the Connection instance by passing a few key parameters into the build method
connection = connection_builder.build(title='s3 test connection',
connection_type='STREAMSETS_AWS_S3',
authoring_data_collector=engine,
tags=['sdk_example', 's3_connection'])
Tip
Supplying an existing, responsive streamsets.sdk.sch_models.Engine instance via the authoring_data_collector parameter is the recommended best practice when building a connection.
Tip
The available options for the connection_type in the streamsets.sdk.sch_models.ConnectionBuilder.build() method are:
'STREAMSETS_AWS_EMR_CLUSTER', 'STREAMSETS_MYSQL', 'STREAMSETS_SNOWFLAKE', 'STREAMSETS_COAP_CLIENT', 'STREAMSETS_OPC_UA_CLIENT', 'STREAMSETS_GOOGLE_PUB_SUB', 'STREAMSETS_MQTT', 'STREAMSETS_POSTGRES', 'STREAMSETS_GOOGLE_CLOUD_STORAGE', 'STREAMSETS_AWS_REDSHIFT', 'STREAMSETS_GOOGLE_BIG_QUERY', 'STREAMSETS_ORACLE', 'STREAMSETS_AWS_S3', 'STREAMSETS_REMOTE_FILE', 'STREAMSETS_SQLSERVER', 'STREAMSETS_AWS_SQS', 'STREAMSETS_SNOWPIPE', and 'STREAMSETS_JDBC'.
Please refer to the StreamSets Platform documentation for details on the various connection types as well as the corresponding configuration properties.
Once the streamsets.sdk.sch_models.Connection instance has been built, you’ll be able to set configuration properties for the Connection.
Setting configuration properties in the UI will vary by connection type.
As an example, setting specific configuration properties for an S3 connection type in the UI looks like the following:
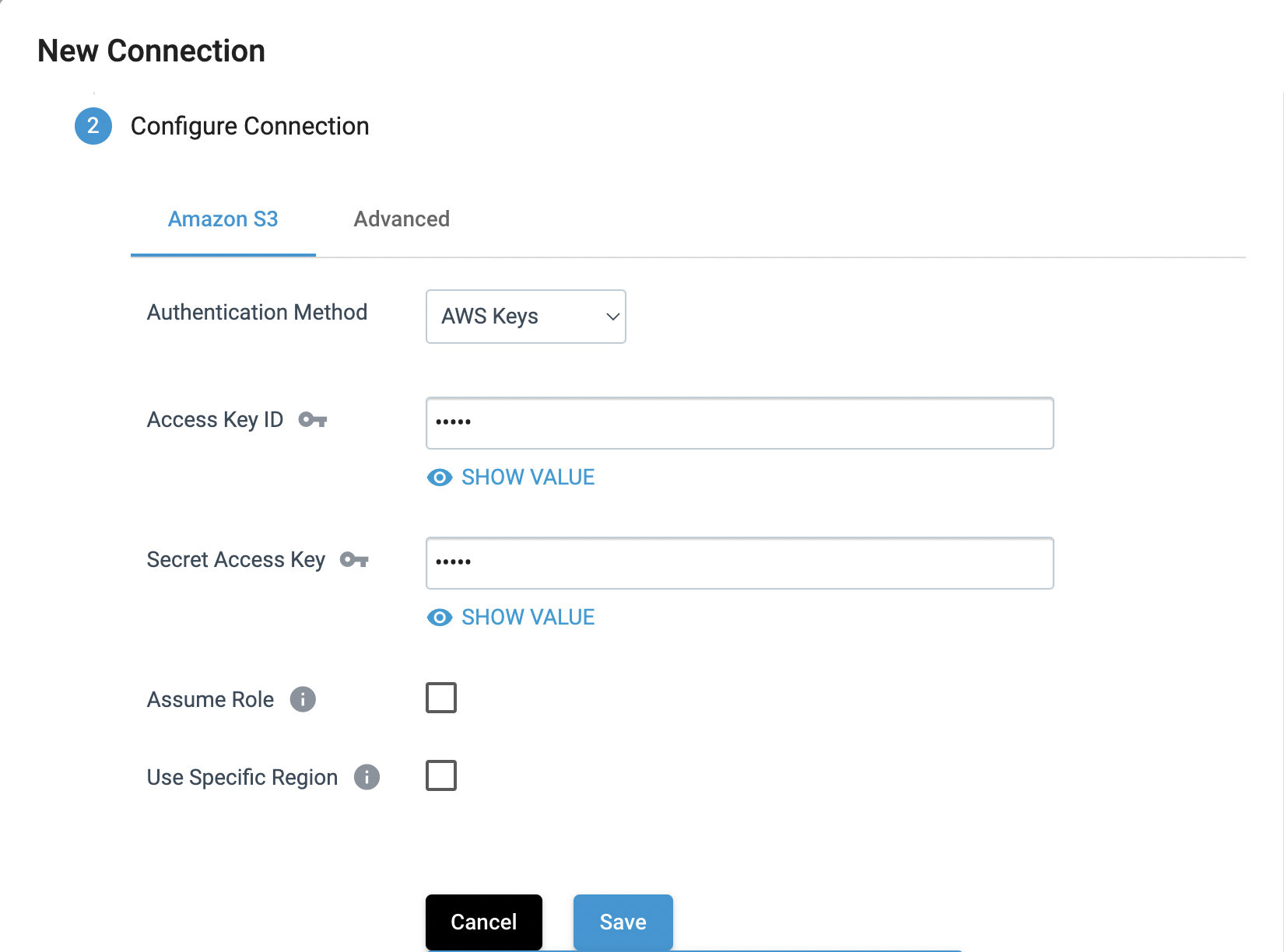
To make configuration updates using the SDK, you can index into the configuration attribute for the Connection by property name. Continuing with the example from above, to set the same configuration properties for the S3 connection you would do the following:
# Specify the credential mode as 'WITH_CREDENTIALS' to use a key pair, or 'WITH_IAM_ROLES' to use an instance profile
connection.connection_definition.configuration['awsConfig.credentialMode'] = 'WITH_CREDENTIALS'
connection.connection_definition.configuration['awsConfig.awsAccessKeyId'] = 12345
connection.connection_definition.configuration['awsConfig.awsSecretAccessKey'] = 67890
Once you have built the Connection and configured it as desired, you can pass it to the streamsets.sdk.ControlHub.add_connection() method to publish it to the Platform:
sch.add_connection(connection)
Tip
The streamsets.sdk.ControlHub.add_connection() method will automatically update the Connection instance’s in-memory representation with the latest state of the Connection on the Platform.
In other words, there is no need to re-retrieve the Connect instance after publishing it!
Updating a Connection#
You can update an existing Connection in the Platform UI by selecting the Connection you wish to update and clicking “Edit”, as seen below:
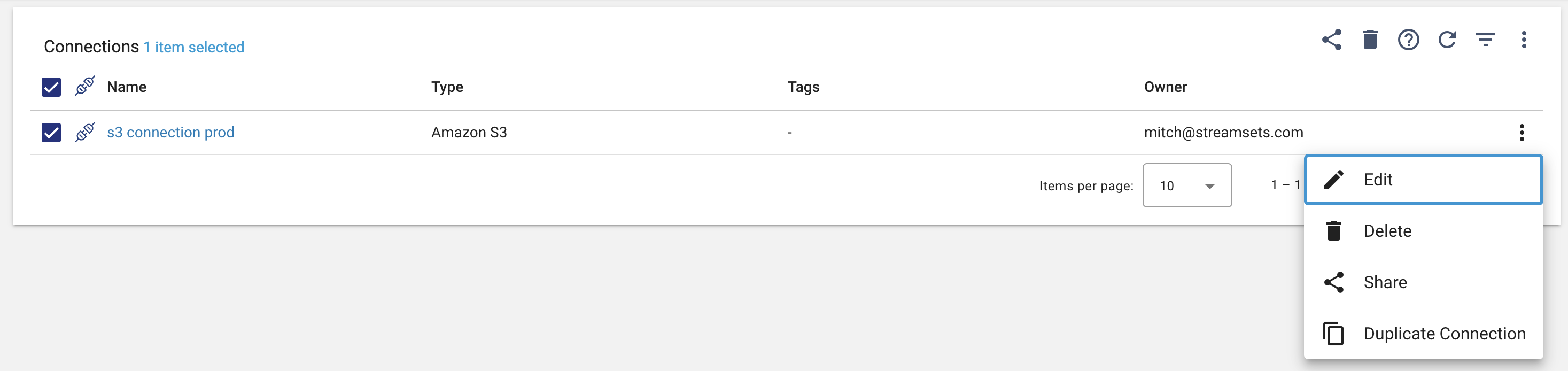
Updating an existing streamsets.sdk.sch_models.Connection instance via the SDK follows a similar workflow to the sections above: retrieving the Connection you wish to update, making the desired changes, and then publishing the Connection.
First, retrieve the streamsets.sdk.sch_models.Connection instance you wish to update by using the streamsets.sdk.ControlHub.connections attribute.
You can make modifications to attributes like the name or various connection-specific configurations.
Please refer to the StreamSets Platform Documentation for details on the properties available for certain connection types.
Once you’ve made the desired changes to the Connection, pass the instance into the streamsets.sdk.ControlHub.update_connection() method to publish the changes:
# Retrieve a connection to update via specific name
connection = sch.connections.get(name='s3 test connection')
# Update properties of the connection (in this case the name of the connection as well as the Access Key/Secret Access Key values for accessing S3)
connection.connection_definition.configuration['awsConfig.awsAccessKeyId'] = 234
connection.connection_definition.configuration['awsConfig.awsSecretAccessKey'] = 567
connection.name = 's3 connection prod'
# Publish the updated connection to the Platform
sch.update_connection(connection)
Tip
The streamsets.sdk.ControlHub.update_connection() method will automatically update the Connection instance’s in-memory representation with the latest state of the Connection on the Platform.
In other words, there is no need to re-retrieve the Connection instance after publishing the changes!
Verifying a Connection#
Verifying a Connection ensures that the configured values can successfully connect to the service or resource that the Connection pertains to. Running verification for a Connection from the Platform UI can be done when creating the Connection for the first time, or by editing an existing Connection. In either case, running verification for the Connection in the UI looks like the following:
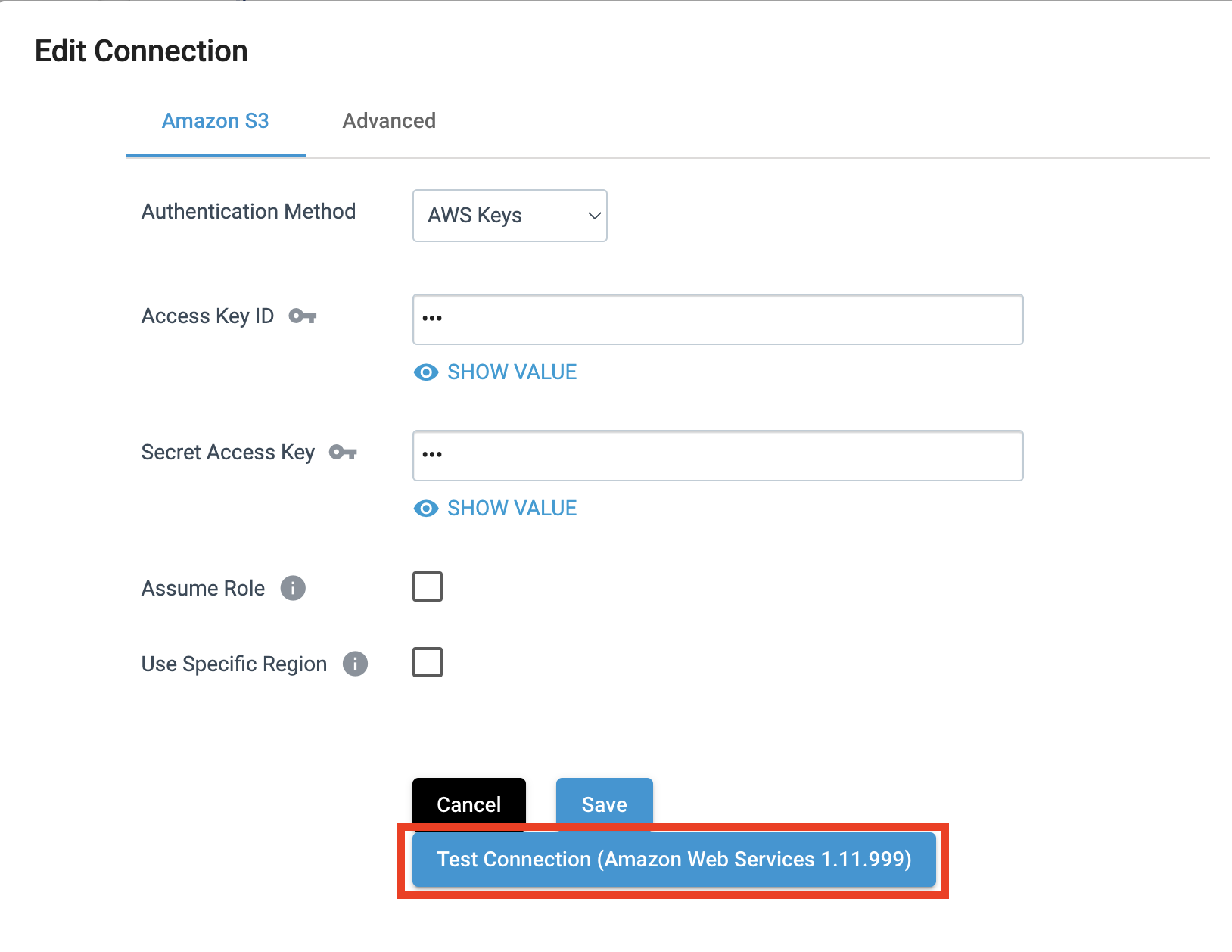
To verify a Connection via the SDK, retrieve the streamsets.sdk.sch_models.Connection instance you want to validate and then use the streamsets.sdk.ControlHub.verify_connection() method to return the results of the verification.
If any issues arise during the verification, you can introspect on the streamsets.sdk.sch_models.ConnectionVerificationResult.issue_count and streamsets.sdk.sch_models.ConnectionVerificationResult.issue_message to identify the issue:
# Retrieve the connection to be verified
connection = sch.connections.get(name='s3 connection prod')
# Run the verification, and then check the results (successful case)
verification_result = sch.verify_connection(connection)
verification_result
connection = sch.connections.get(name='s3 connection invalid')
# Run the verification, and then check the results (failure case)
verification_result = sch.verify_connection(connection)
verification_result
verification_result.issue_count
verification_result.issue_message
Output:
# verification_result (successful case)
<ConnectionVerificationResult (status=VALID)>
# verification_result (failure case)
<ConnectionVerificationResult (status=INVALID)>
# verification_result.issue_count
1
# verification_result.issue_message
'S3_SPOOLDIR_20 - Cannot connect to Amazon S3, reason : com.amazonaws.services.s3.model.AmazonS3Exception:
The request signature we calculated does not match the signature you provided. Check your key and signing method.'
Using a Connection Inside a Pipeline#
Note
At this time, specifying a Connection for a stage via the SDK is only supported when adding the stage to a streamsets.sdk.sch_models.Pipeline or streamsets.sdk.sch_models.PipelineBuilder instance.
This would require adding a stage via the streamsets.sdk.sch_models.Pipeline.add_stage() or streamsets.sdk.sch_models.PipelineBuilder.add_stage() methods, respectively.
Once a Connection has been created and published to the Platform, it can be used in a stage within a pipeline. Specifying a Connection for a pipeline in the Platform UI looks like the following:
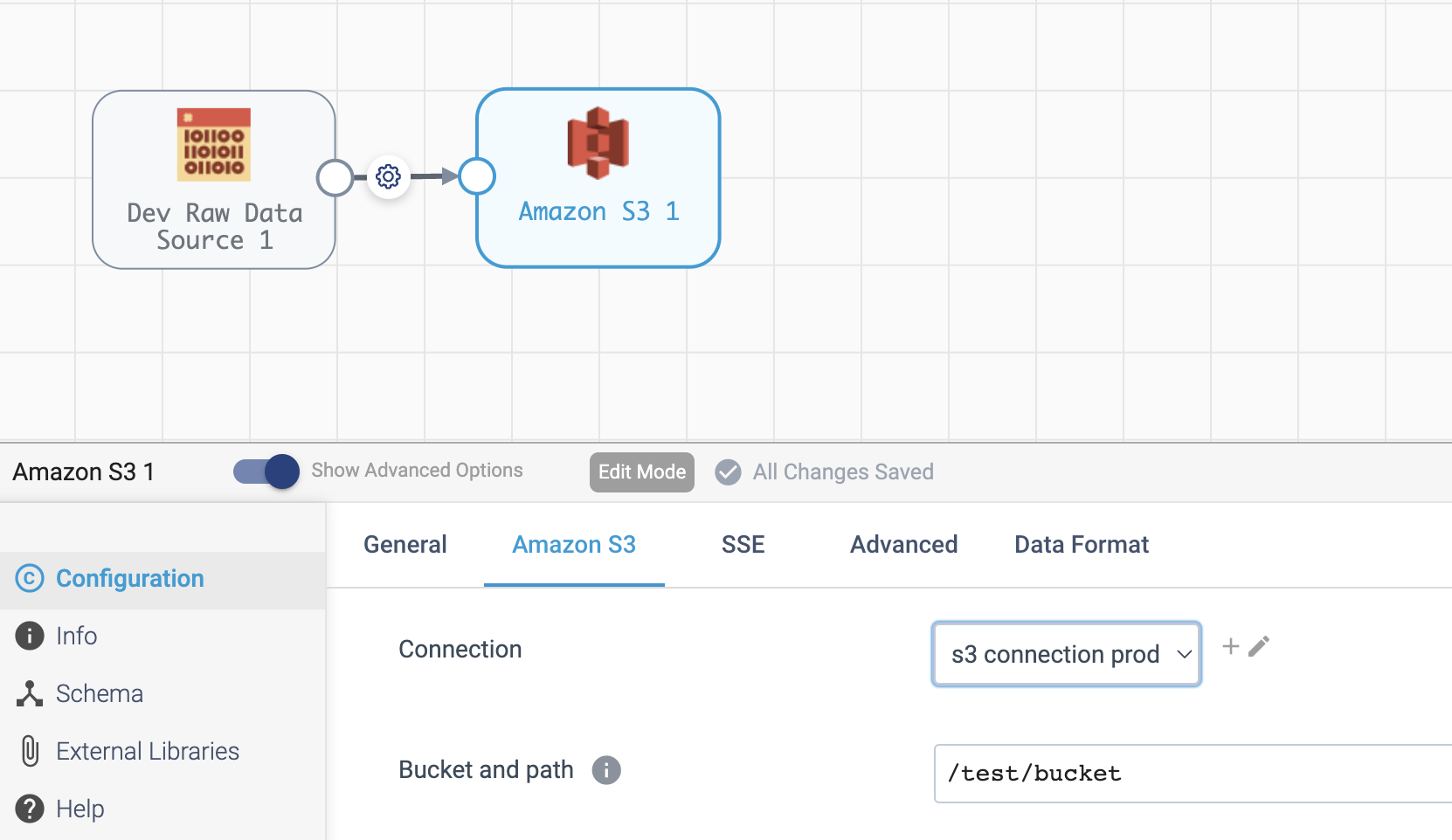
You can specify a streamsets.sdk.sch_models.Connection instance for a stage via the SDK when building a new pipeline or when adding a new stage to an existing pipeline.
Please refer to the SDK documentation for editing pipelines and creating pipelines for details on adding stages.
Once you’ve added the appropriate stage to the pipeline, pass the Connection instance into the stage’s streamsets.sdk.sch_models.SchSdcStage.use_connection() method (or streamsets.sdk.sch_models.SchStStage.use_connection() for Transformer pipelines).
Finally, publish the updated pipeline to the Platform using the streamsets.sdk.ControlHub.publish_pipeline() method:
Note
Not all stage types support Connections. Please refer to the StreamSets Platform Documentation for details on which stages support certain connection types.
# Add a stage to the pipeline via the PipelineBuilder
amazon_s3_destination = pipeline_builder.add_stage('Amazon S3', type='destination')
# Or, alternatively, add a stage to an existing pipeline after retrieving it
# pipeline = sch.pipelines.get(name='Example Pipeline')
# amazon_s3_destination = pipeline.add_stage('Amazon S3', type='destination')
# Configure the stage (an AWS S3 destination in this example) to use the connection created/retrieved earlier
amazon_s3_destination.use_connection(connection)
# If creating a new pipeline via PipelineBuilder, build the pipeline. Otherwise, skip this step.
pipeline = pipeline_builder.build('Example Pipeline', commit_message='Added a connection to the S3 destination')
# Publish the updated pipeline
sch.publish_pipeline(pipeline)
Get Pipelines Using a Connection#
Checking which pipelines or fragments on Platform currently use a particular Connection can be extremely useful, especially when planning to update a Connection. You can check which pipelines or fragments use a specific Connection in the Platform UI by clicking on a specific Connection and checking the “Pipelines/Fragments” section as seen below:
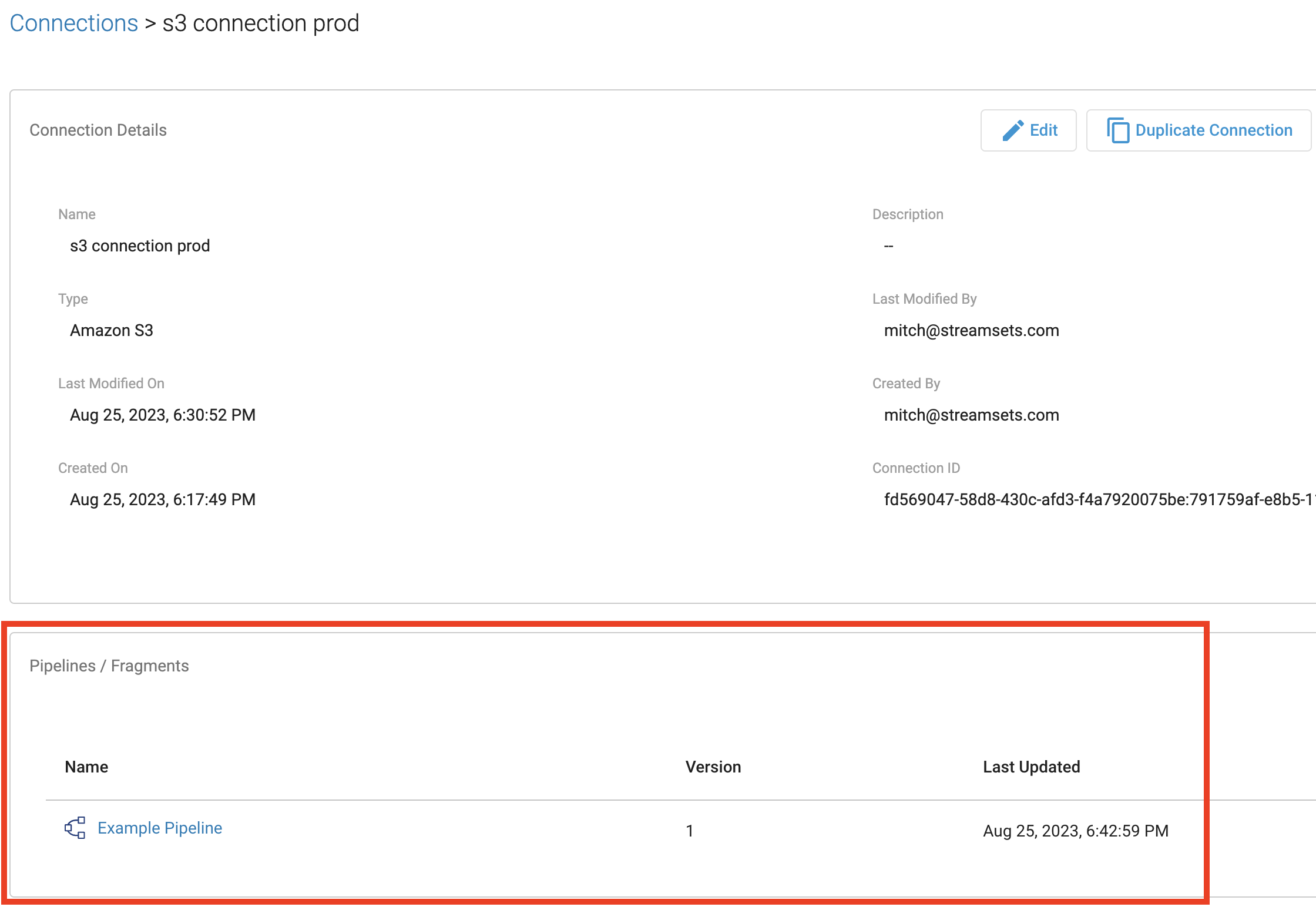
To retrieve all pipelines using a specific Connection via the SDK, first retrieve the streamsets.sdk.sch_models.Connection instance you’re interested in and then reference the streamsets.sdk.sch_models.Connection.pipeline_commits attribute to determine which pipelines are currently using the Connection.
You can further introspect on the pipeline_commits attribute to even retrieve the specific streamsets.sdk.sch_models.Pipeline instance:
# Get the connection, check its pipeline_commits and retrieve the Pipeline instance associated with the first commit
connection = sch.connections.get(name='s3 connection prod')
connection.pipeline_commits
connection.pipeline_commits[0].pipeline
Output:
#connection.pipeline_commits
[<PipelineCommit (commit_id=db1e3b87-1499-44ef-93b8-e4e045318c48:admin, version=1, commit_message=None)>]
# connection.pipeline_commits[0].pipeline
<Pipeline (pipeline_id=5462626e-0243-48dd-8c07-c6787a813e37:admin,
commit_id=db1e3b87-1499-44ef-93b8-e4e045318c48:admin, name=s3, version=1)>
Deleting a Connection#
Deleting a Connection from the Platform UI is done as seen below:

To delete a Connection via the SDK, first retrieve the streamsets.sdk.sch_models.Connection instance you wish to delete and then pass it to the streamsets.sdk.ControlHub.delete_connection() method:
# Retrieve the connection to delete, then delete it from Platform
connection = sch.connections.get(name='s3 connection prod')
sch.delete_connection(connection)
Accessing Snowflake Credentials#
Accessing Snowflake Settings from the Platform UI is done by heading over to Account Settings and clicking ‘Snowflake Settings’ as seen below:

Here you will be able to view and add your Snowflake Credentials as shown below.

Once you click ‘Add’, you will then be able to set up your Snowflake Credentials:
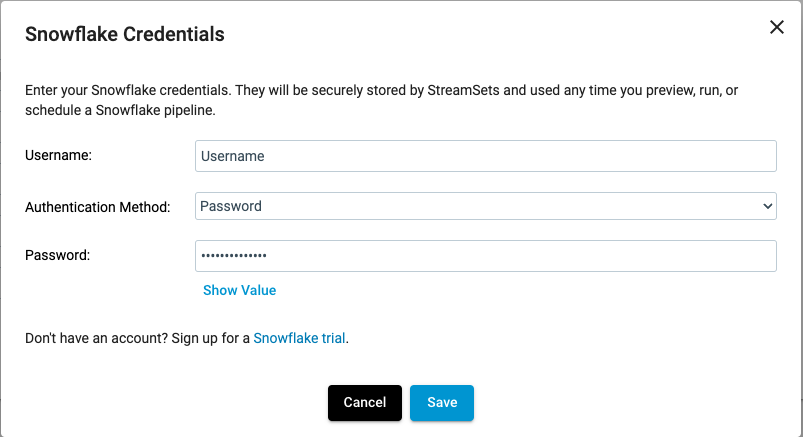
Now you will be able to view your saved Snowflake Credentials and have the ability to ‘Edit’ or ‘Delete them as shown below:
To retrieve your Snowflake Credentials via the SDK, you can use the streamsets.sdk.ControlHub.get_snowflake_user_credentials() method.
Once it is retrieved, you can use the streamsets.sdk.ControlHub.update_snowflake_user_credentials() method to update your snowflake credentials by passing in the following parameters: username, snowflake_login_type, password, private_key & role.
.. note:
If you do not have existing Snowflake Credentials, the :py:meth:`streamsets.sdk.ControlHub.update_snowflake_user_credentials` method will create Snowflake Credentials.
If you would like to delete your Snowflake Credentials, you can do so by calling the streamsets.sdk.ControlHub.delete_snowflake_user_credentials() method.
# Retrieve the Snowflake Credentials
snowflake_credential = sch.get_snowflake_user_credentials()
# Update the Snowflake Credentials
sch.update_snowflake_user_credentials(username='TEST USERNAME', snowflake_login_type='PASSWORD', password='TEST PASSWORD')
# Delete the Snowflake Credentials
sch.delete_snowflake_user_credentials()
Accessing Snowflake Pipeline Defaults#
Accessing Snowflake Settings from the Platform UI is done by heading over to Account Settings and clicking ‘Snowflake Settings’ as seen below:
Here you will be able to view, add & edit your Snowflake Pipeline Defaults as shown below.
Once you click ‘Save’, your Snowflake Pipeline Defaults will be saved and can be then be edited again.
To retrieve your Snowflake Pipeline Defaults via the SDK, you can use the streamsets.sdk.ControlHub.get_snowflake_pipeline_defaults() method.
Once it is retrieved, you can use the streamsets.sdk.ControlHub.update_snowflake_pipeline_defaults() method to update your snowflake credentials by passing in the following parameters: account_url, database, warehouse, schema & role.
.. note:
If you do not have existing Snowflake Pipeline Defaults, the :py:meth:`streamsets.sdk.ControlHub.update_snowflake_pipeline_defaults` method will create Snowflake Pipeline Defaults.
If you would like to delete your Snowflake Pipeline Defaults, you can do so by calling the streamsets.sdk.ControlHub.delete_snowflake_pipeline_defaults() method.
# Retrieve the Snowflake Pipeline Defaults
snowflake_credential = sch.get_snowflake_pipeline_defaults()
# Update the Snowflake Pipeline Defaults
sch.update_snowflake_pipeline_defaults(account_url='https://testurl.snowflakecomputing.com', database='Test Database', warehouse='Test Warehouse', schema='Test Schema', role='PUBLIC')
# Delete the Snowflake Pipeline Defaults
sch.delete_snowflake_pipeline_defaults()
Bringing It All Together#
The complete scripts from this section can be found below. The Using a Connection Inside a Pipeline section’s examples have been excluded as they are very use-case dependent.
Commands that only served to verify some output from the example have been removed.
# Retrieve all existing connections
# sch.connections
# Retrieve all connections with JDBC type
# sch.connections.get_all(connection_type='STREAMSETS_JDBC')
# Retrieve a connection with the name 'amazon s3 connection'
# sch.connections.get(name='amazon s3 connection')
# Retrieve a connection via specific id
# sch.connections.get(id='350020cf-eff6-428a-8484-7078edf532c6:791759af-e8b5-11eb-8015-e592a7dbb2d0')
# Instantiate the ConnectionBuilder instance
connection_builder = sch.get_connection_builder()
# Retrieve the Data Collector engine to be used as the authoring engine
engine = sch.engines.get(engine_url='<engine_url>')
# Build the Connection instance by passing a few key parameters into the build method
connection = connection_builder.build(title='s3 test connection',
connection_type='STREAMSETS_AWS_S3',
authoring_data_collector=engine,
tags=['sdk_example', 's3_connection'])
# Specify the credential mode as 'WITH_CREDENTIALS' to use a key pair, or 'WITH_IAM_ROLES' to use an instance profile
connection.connection_definition.configuration['awsConfig.credentialMode'] = 'WITH_CREDENTIALS'
connection.connection_definition.configuration['awsConfig.awsAccessKeyId'] = 12345
connection.connection_definition.configuration['awsConfig.awsSecretAccessKey'] = 67890
sch.add_connection(connection)
# Retrieve a connection to update via specific name
connection = sch.connections.get(name='s3 test connection')
# Update properties of the connection (in this case the name of the connection as well as the Access Key/Secret Access Key values for accessing S3)
connection.connection_definition.configuration['awsConfig.awsAccessKeyId'] = 234
connection.connection_definition.configuration['awsConfig.awsSecretAccessKey'] = 567
connection.name = 's3 connection prod'
# Publish the updated connection to the Platform
sch.update_connection(connection)
# Run the verification, and then check the results
verification_result = sch.verify_connection(connection)
# Get the connection, check its pipeline_commits and retrieve the Pipeline instance associated with the first commit
connection = sch.connections.get(name='s3 connection prod')
connection.pipeline_commits
Connection.pipeline_commits[0].pipeline
# sch.delete_connection(connection)
# Retrieve the Snowflake Credentials
# snowflake_credential = sch.get_snowflake_user_credentials()
# Update the Snowflake Credentials
# sch.update_snowflake_user_credentials(username='TEST USERNAME', snowflake_login_type='PASSWORD', password='TEST PASSWORD')
# Delete the Snowflake Credentials
# sch.delete_snowflake_user_credentials()
# Retrieve the Snowflake Pipeline Defaults
# snowflake_credential = sch.get_snowflake_user_credentials()
# Update the Snowflake Pipeline Defaults
# sch.update_snowflake_user_credentials(username='TEST USERNAME', snowflake_login_type='PASSWORD', password='TEST PASSWORD')
# Delete the Snowflake Pipeline Defaults
# sch.delete_snowflake_user_credentials()