Creating Pipelines
Section Contents
Creating Pipelines#
Pipeline creation and management in the Platform SDK follows the structure and conventions that you’re already used to in the UI, while offering an extensible, programmatic interaction with pipeline objects.
For more details, refer to the StreamSets Platform Documentation for pipelines.
Hint
All of the examples below have focused on stages for SDC pipelines, however streamsets.sdk.sch_models.SchStStage instances could be swapped into these examples for Transformer pipelines without issue.
Instantiating a Pipeline Builder#
In the UI, a pipeline can be created and modified from the Pipelines section as seen below:
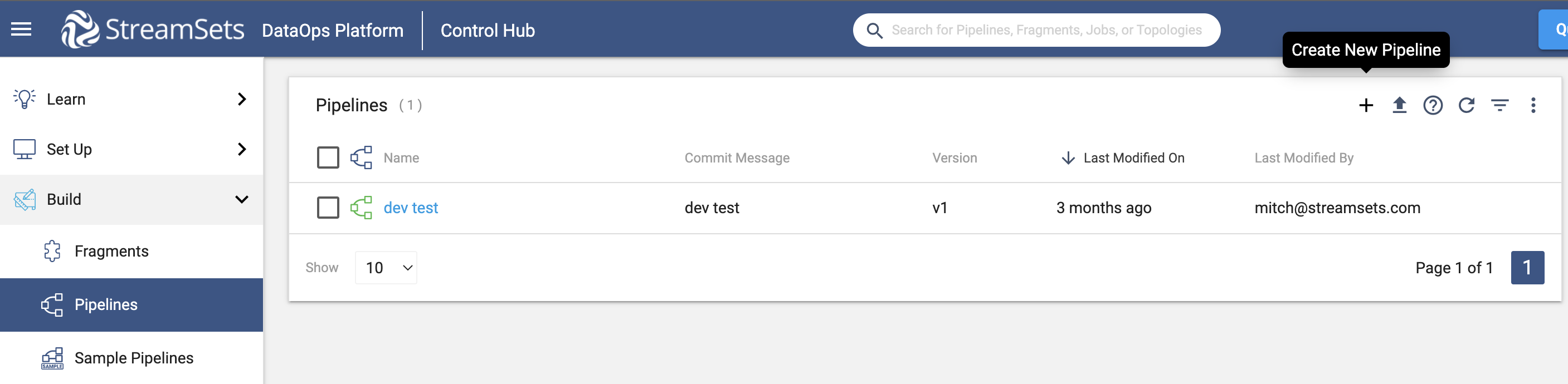
To accomplish the same task and create a pipeline using the SDK, the first step is to instantiate a
streamsets.sdk.sch_models.PipelineBuilder instance. This class handles the majority of the pipeline
configuration on your behalf by building the initial JSON representation of the pipeline, and setting default values for
essential properties (instead of requiring each to be set manually). Use the streamsets.sdk.ControlHub.get_pipeline_builder()
method to instantiate the builder object by passing in the engine_type for the pipeline you plan to create -
available engine types are 'data_collector', 'snowflake', or 'transformer'.
Instantiating a streamsets.sdk.sch_models.PipelineBuilder instance for either
the 'data_collector' or 'transformer' engine types requires the Authoring Engine be specified for the pipeline.
It can be passed into the builder’s instantiation via the engine_id parameter:
sdc = sch.engines.get(engine_url='<data_collector_url>')
# Available engine types are 'data_collector', 'snowflake', or 'transformer'
pipeline_builder = sch.get_pipeline_builder(engine_type='data_collector', engine_id=sdc.id)
The 'transformer' engine type follows the same conventions:
transformer = sch.engines.get(engine_url='<transformer_url>', engine_type='TRANSFORMER')
pipeline_builder = sch.get_pipeline_builder(engine_type='transformer', engine_id=transformer.id)
On the other hand, when instantiating a streamsets.sdk.sch_models.PipelineBuilder instance for the
'snowflake' engine type, the engine_id parameter should not be specified:
pipeline_builder = sch.get_pipeline_builder(engine_type='snowflake')
Adding Stages to the Pipeline Builder#
Once the pipeline is created, you can add stages to it using the Pipeline Canvas UI, seen below:
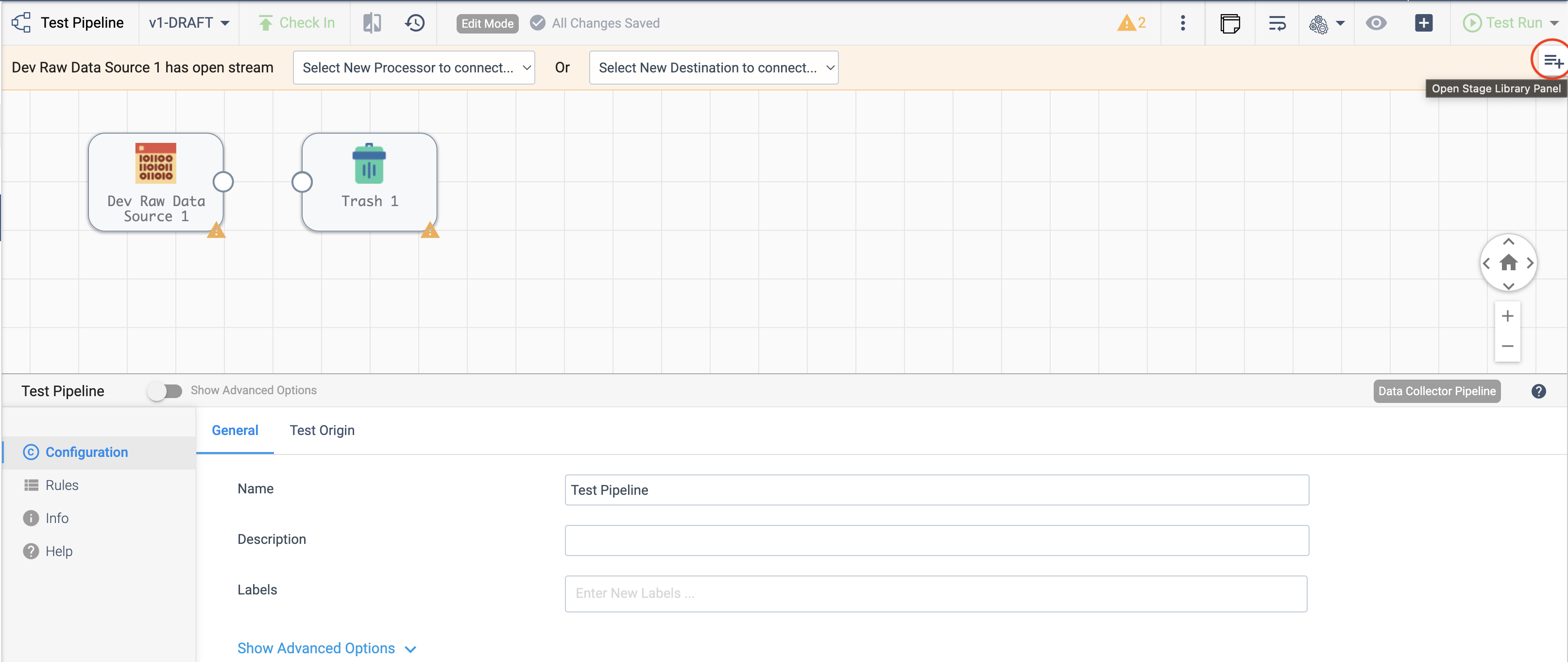
To add stages to the pipeline using the SDK, utilize the streamsets.sdk.sch_models.PipelineBuilder.add_stage()
method - see the API reference for this method for details on the arguments this method takes.
As shown in the image above, the simplest type of pipeline directs one origin into one destination. For this example,
you can do this with Dev Raw Data Source origin and Trash destination, respectively:
dev_raw_data_source = pipeline_builder.add_stage('Dev Raw Data Source')
trash = pipeline_builder.add_stage('Trash')
Note
Dev Raw Data Source origin cannot be used in Transformer for Snowflake pipelines.
Instead, use Snowflake Table or Snowflake Query
Sometimes it is necessary to pass in the type of stage you want to use. If you look at the image below for example, you’ll see that there are two types of Azure Data Lake Storage Gen2.
One of type Destination and another of type Origin.
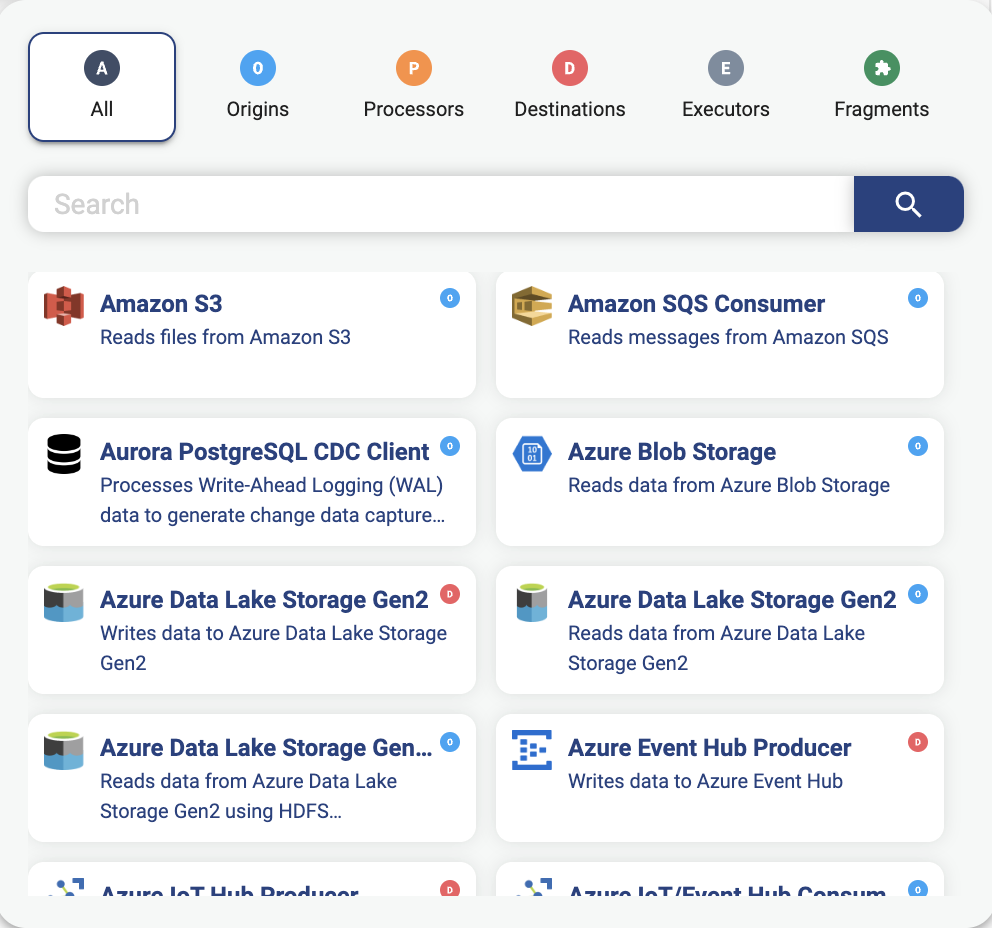
Note
There are four possible value for type namely, 'origin', 'processor', 'executor' and 'destination'.
If you want to specify the type of stage to add through via sdk, you can pass the optional type parameter
to the streamsets.sdk.sch_models.PipelineBuilder.add_stage() method.
azure_data_lake_origin = pipeline_builder.add_stage('Azure Data Lake Storage Gen2', type='origin')
azure_data_lake_processor = pipeline_builder.add_stage('Azure Data Lake Storage Gen2', type='processor')
Warning
When a stage is created by passing a stage label to streamsets.sdk.sch_models.PipelineBuilder.add_stage(), the method picks the first stage that matches that label.
The same label can be used by multiple stages (e.g., the Amazon S3 origin and the Amazon S3 destination both use the ‘Amazon S3’ label).
As a best practice, you should always specify the type parameter for a stage to guarantee the correct stage is selected.
Connecting the Stages#
Preface: Terminology and Conventions#
There are several concepts that should be clarified as they are referenced frequently throughout this section:
- Output Lanes and Output Streams:
Output Lanes and Output Streams refer to the available output “nodes” that can be connected from one stage to another. While Output Lanes and Output Streams are two different entities internally, they can safely be used interchangeably when referring to the output “nodes” for stages.
For example in the screenshot from the above section, the
Dev Raw Data Sourcestage has only a single output lane (or output stream). In later sections and examples, you will find stages with several output lanes - including stages like the Stream Selector which can dynamically allocate output lanes.
- Output Lane Indices:
Because certain stages in a pipeline can have more than one output lane, you must be able to specify which output lane you wish to connect for a particular stage. As such, the SDK makes use of index parameters when using the
streamsets.sdk.sch_models.SchSdcStage.connect_inputs()orstreamsets.sdk.sch_models.SchSdcStage.connect_outputs()methods - these will be covered in greater detail in later sections.In keeping with the example from the screenshot in the above section, the
Dev Raw Data Sourcestage only has a single output lane which could be referenced as the output lane at index of 0 (the first output lane). You will find additional examples in later sections that deal with stages that have multiple output lanes and thus use index values to specify which output lane is desired.
- The
output_lanesattribute: Every
streamsets.sdk.sch_models.SchSdcStageandstreamsets.sdk.sch_models.SchStStageinstance in the SDK, regardless of type, exposes an attribute calledoutput_lanes. This attribute lists the available output lanes for the stage instance in the same order as they would appear in the Pipeline Canvas UI. This attribute will be used in later sections to help determine which output lanes to map certain stages to and will likewise be useful for users connecting stages for the first time.Continuing with the example from the screenshot in the above section, the
Dev Raw Data Sourcestage’soutput_lanesattribute would show a single output lane value at the 0th position in the list.Note
Please note that the
output_lanesattribute cannot be directly set for a stage to avoid accidentally introducing inconsistencies for a stage’s output lanes. Attempting to execute commands likestage.output_lanes = [some, list, of, values]will be ignored.
- The
- Predicates and Output Lanes for Stream Selector stages:
In previous versions of the SDK, it was necessary to specify a dictionary value that contained both a predicate and an output lane when adding conditions for a Stream Selector stage. While this is still possible, the SDK has been updated to handle output lane specification on your behalf - greatly simplifying the interaction with the Stream Selector stage in the process. Instead of providing a full dictionary value:
{'predicate': "${record:value('/field') > '1'}", 'outputLane': 'some_lane_123456'}you are only required to specify the predicate’s string value instead:
"${record:value('/field') > '1'}"This is covered in greater detail in a later section.
Connecting Stages#
Once stages have been added in the Pipeline Canvas, linking the output of one stage to the input of another connects them, as seen below:
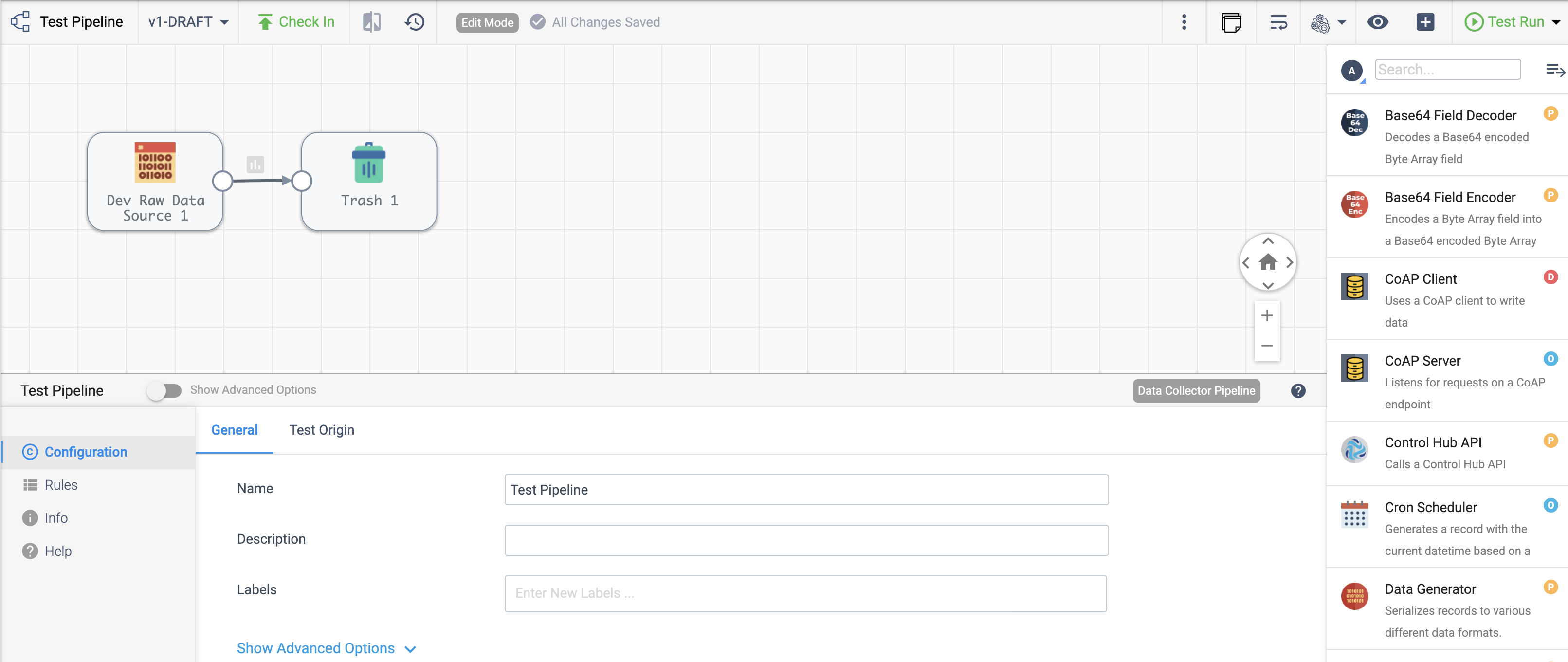
With streamsets.sdk.sch_models.SchSdcStage instances in hand, you can connect them by using the >>
operator. Connecting the Dev Raw Data Source origin and Trash destination from the example above would look
like the following:
dev_raw_data_source >> trash
Output:
<com_streamsets_pipeline_stage_destination_devnull_NullDTarget (instance_name=Trash_01)>
You can also connect stages using either the streamsets.sdk.sch_models.SchSdcStage.connect_inputs() or streamsets.sdk.sch_models.SchSdcStage.connect_outputs() method.
To connect a stage using these methods:
# connect dev_raw_data_source to trash
dev_raw_data_source.connect_outputs(stages=[trash])
# alternatively, you can also use connect_inputs to connect dev_raw_data_source to trash
trash.connect_inputs(stages=[dev_raw_data_source])
As their names suggest, both the streamsets.sdk.sch_models.SchSdcStage.connect_inputs() and streamsets.sdk.sch_models.SchSdcStage.connect_outputs() methods accept a list of stages to connect to.
Continuing with the above example, if you had 3 separate destination stages to connect to the Dev Raw Data Source origin you could use the following to connect them all at once:
# connect dev_raw_data_source to the theoretical destination_one, destination_two and destination_three stages
dev_raw_data_source.connect_outputs(stages=[destination_one, destination_two, destination_three])
A Special Case: Stages With More Than One Output Stream#
In some cases it may be required to specify a particular output stream that you wish to connect for a stage, like when a stage has multiple output streams available. Some stages, such as the File Tail origin or the Record Deduplicator processor, have multiple fixed output streams as seen in the incomplete pipeline example below:
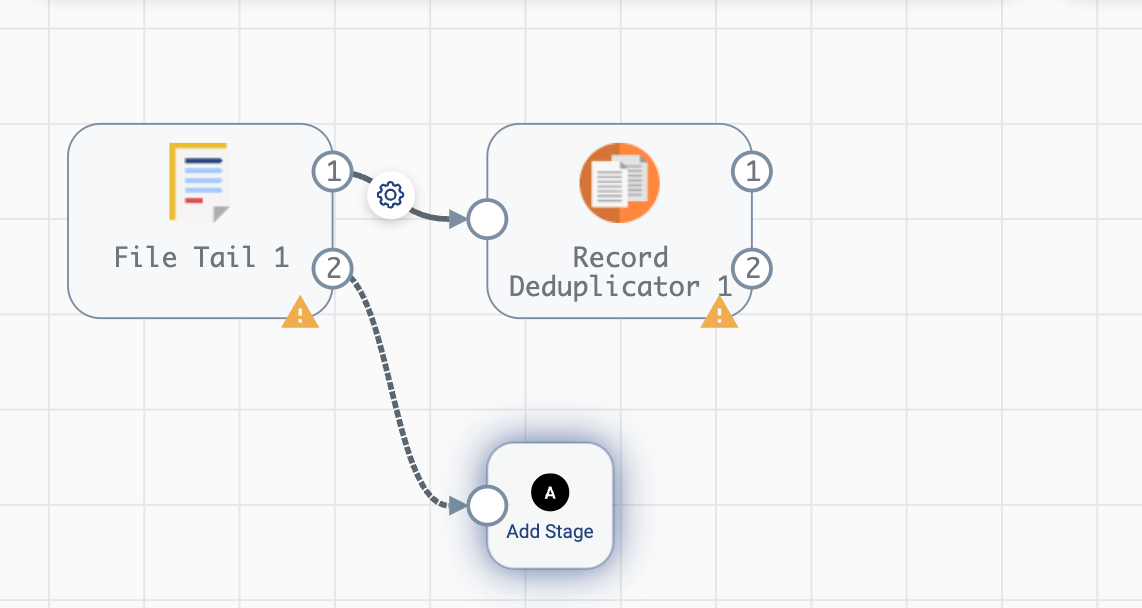
Connecting to a stage with multiple output streams can be handled by specifying an index value to the target_stage_output_lane_index or output_lane_index parameters used by the streamsets.sdk.sch_models.SchSdcStage.connect_inputs() or streamsets.sdk.sch_models.SchSdcStage.connect_outputs() methods, respectively.
When using the streamsets.sdk.sch_models.SchSdcStage.connect_inputs() method, the index supplied for target_stage_output_lane_index refers to the index of the output lane for the stage you’re targeting for connection, i.e. the object provided to the stages parameter.
When using the streamsets.sdk.sch_models.SchSdcStage.connect_outputs() method, the index supplied for output_lane_index refers to the index of the output lane of this stage.
Note
Stages in a Transformer pipeline use the same connect_inputs and connect_outputs methods.
Referring to the example in the screenshot above, you could execute the following if you wanted to connect 3 separate Trash destination stages to each of the open output lanes for both the File Tile and Record Deduplicator stages:
# Add 3 Trash stages to the pipeline
trash_one = pipeline.add_stage('Trash')
trash_two = pipeline.add_stage('Trash')
trash_three = pipeline.add_stage('Trash')
# Grab the two existing stages to connect the new Trash stages to
file_tail = pipeline.stages.get(label='File Tail 1')
record_deduplicator = pipeline.stages.get(label='Record Deduplicator 1')
# Connect trash_one to the open output stream for the File Tail stage using connect_outputs()
file_tail.connect_outputs(stages=[trash_one], output_lane_index=1) # the index of the first output lane for the File Tail stage itself
# Alternatively, connect trash_one to the open output stream for the File Tail origin using connect_inputs()
trash_one.connect_inputs(stages=[file_tail], target_stage_output_lane_index=1) # the index of the first output lane belonging to the stage being targeted - i.e. File Tail
# Connect trash_two and trash_three to the two open output streams for the Record Deduplicator using connect_outputs()
record_deduplicator.connect_outputs(stages=[trash_two], output_lane_index=0) # the index of the first output lane for the Record Deduplicator stage itself
record_deduplicator.connect_outputs(stages=[trash_three], output_lane_index=1) # the index of the second output lane for the Record Deduplicator stage itself
# Alternatively, connect trash_two and trash_three to the two open output streams for the Record Deduplicator using connect_inputs()
trash_two.connect_inputs(stages=[record_deduplicator], target_stage_output_lane_index=0) # the index of the first output lane belonging to the stage being targeted - i.e. Record Deduplicator
trash_three.connect_inputs(stages=[record_deduplicator], target_stage_output_lane_index=1) # the index of the second output lane belonging to the stage being targeted - i.e. Record Deduplicator
# Publish the pipeline changes to Control Hub
sch.publish_pipeline(pipeline)
Executing the above commands will result in a pipeline that looks like the following when viewed in the Pipeline Canvas UI:
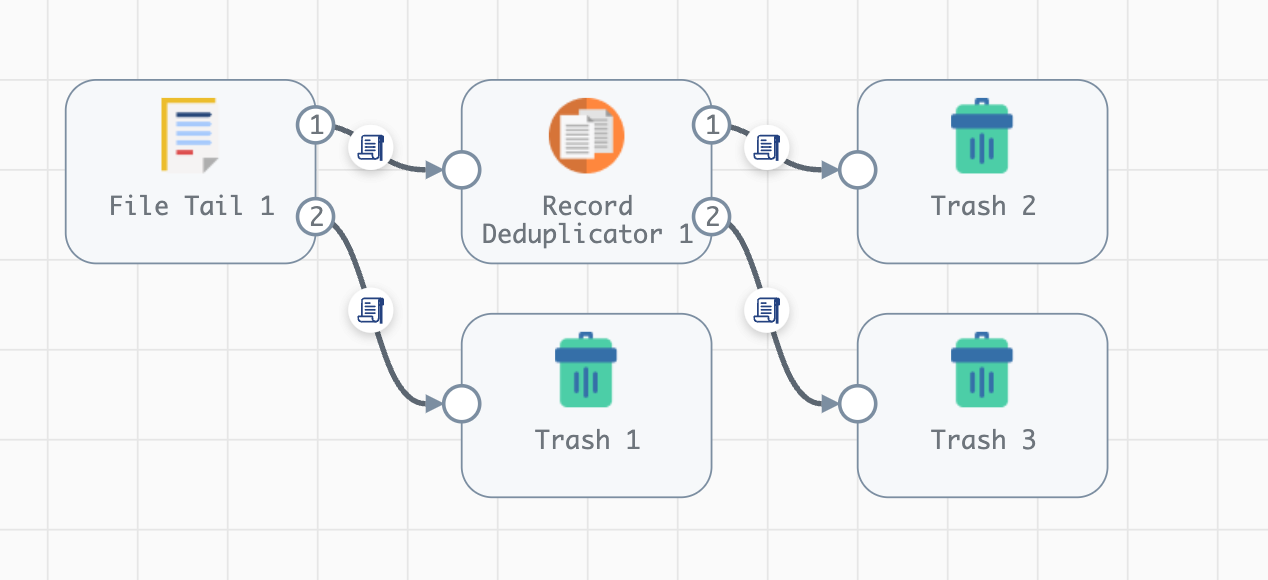
Warning
Stages added to a pipeline via the SDK are not automatically arranged in the UI accordingly. Clicking the “auto-arrange” button in the Pipeline Canvas UI will sort the stages as expected. This will be addressed in a future release of the SDK.
A Special Case: the Stream Selector Stage#
Similar in nature to stages that have a fixed number of output streams greater than one, the Stream Selector stage is capable of creating multiple output streams dynamically. As such, there are special conventions when modifying, updating, or connecting to the output streams of a Stream Selector stage.
In the screenshot below, you will find a Stream Selector stage that exists in a pipeline for which four conditions have been added:
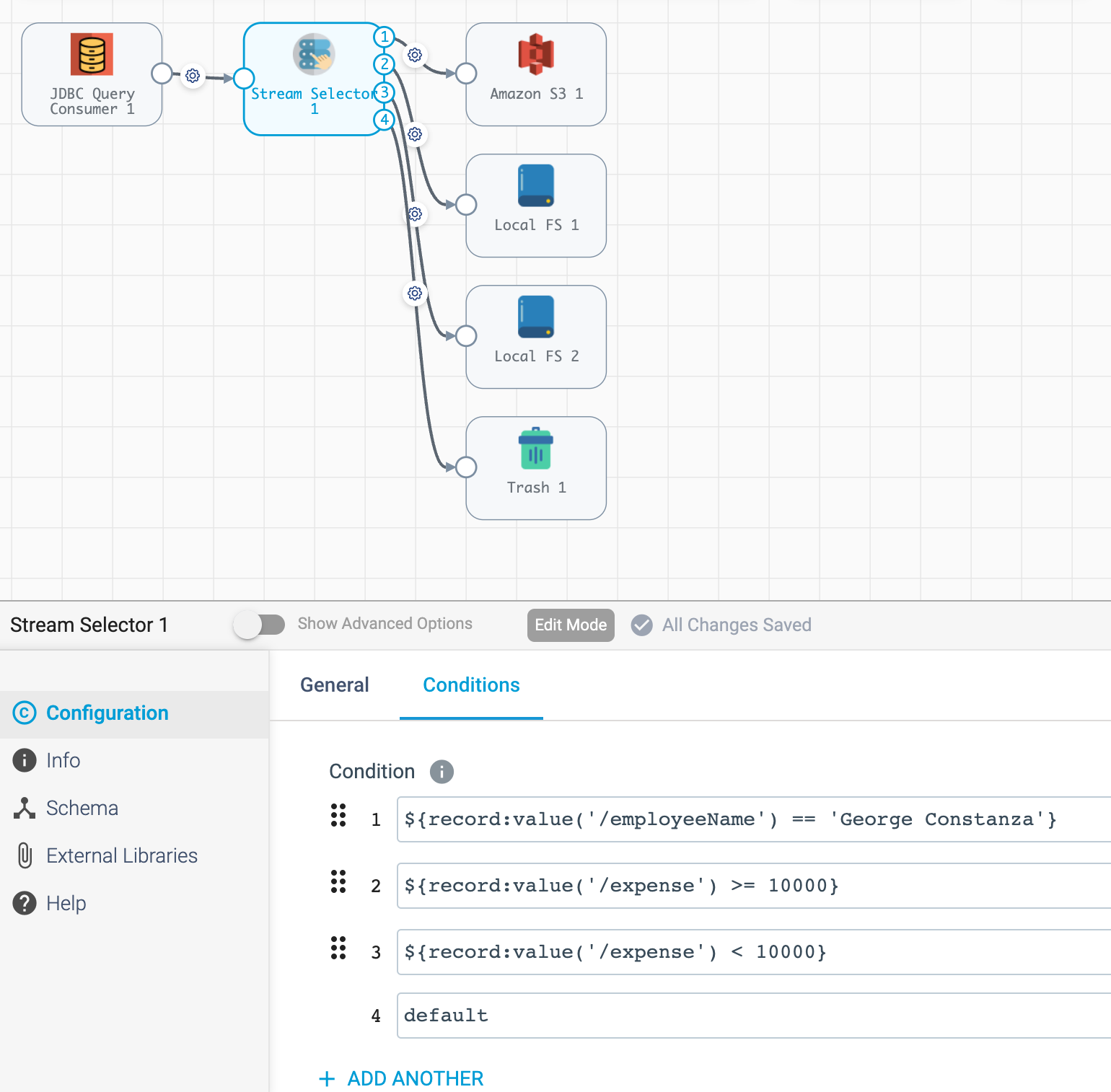
The Stream Selector stage is unique in that it has the predicates attribute which stores a list of dictionaries for the various predicate conditions and the output lanes they correspond to, as seen in the example below:
stream_selector = pipeline.stages.get(label='Stream Selector 1')
# Show the current predicate list
stream_selector.predicates
Output:
# stream_selector.predicates
[{'outputLane': 'StreamSelector_1OutputLane1692224138828', 'predicate': "${record:value('/employeeName') == 'George Constanza'}"},
{'outputLane': 'StreamSelector_1OutputLane1692224137959', 'predicate': "${record:value('/expense') >= 10000}"},
{'outputLane': 'StreamSelector_1OutputLane1692224137294', 'predicate': "${record:value('/expense') < 10000}"},
{'outputLane': 'StreamSelector_1OutputLane1692224133318', 'predicate': 'default'}]
The predicates attribute acts like a list and also exposes several methods for interacting with the list of predicate values.
Adding Predicates to the Stream Selector#
Assume you have a Stream Selector stage that only has the default condition, and you wish to add the other three conditions to make it match the screenshot from the section above.
Adding predicates for a Stream Selector stage can be done either by adding to (extending) the current list of predicates via the add_predicates method, or by setting the list of predicates directly.
Note
It is not required to provide a value for the outputLane that corresponds to the predicate for either of these methods.
The SDK simplifies the addition of predicates compared to previous versions.
It will handle output lane creation on your behalf, and automatically generate a unique output lane value for each predicate provided.
If you would like to completely “reset” a Stream Selector’s predicates list and write in a new list of conditions, you can do so by directly setting the predicates attribute.
The following would set the Stream Selector stage’s predicates equal to the values seen in the screenshot from the section above:
# Wipe out the current list of predicates and "reset" it to the list of predicates provided
# Note that only the predicate conditions are provided as output lanes will be generated on your behalf
stream_selector.predicates = ["${record:value('/employeeName') == 'George Constanza'}",
"${record:value('/expense') >= 10000}",
"${record:value('/expense') < 10000}",
"default"]
Alternatively, if you’d prefer to simply add another condition to the list of predicates and thus create another output lane for the Stream Selector stage, you can use the add_predicates method to add one or more conditions.
These conditions will be appended to the front of the existing list of predicates, consistent with the behavior you would see in the Pipeline Canvas UI:
# Add two additional predicates to the four existing predicates
stream_selector.add_predicates(["${record:value('/employeeName') == 'Cosmo Kramer'}", "${record:value('/employeeName') == 'Newman'}"])
If you’re unsure of the ordering of a Stream Selector stage’s predicates or which condition pertains to which output lane, reference the predicates attribute for the stage.
This will always provided a sorted-order list of predicates and their corresponding output lanes which you can use to determine which stage(s) to connect to which outputs.
For example, assuming you wanted to connect a new S3 destination stage to the output lane that maps to the "${record:value('/expense') >= 10000}" condition:
# Check where in the list of predicates the condition is
predicate_index = stream_selector.predicates.index(next(predicate for predicate in stream_selector.predicates if predicate['predicate'] == "${record:value('/expense') >= 10000}"))
# Connect the stream_selector stage to the new_s3_stage on the output lane found above
stream_selector.connect_outputs(stages=[new_s3_stage], output_lane_index=predicate_index)
Removing Predicates From the Stream Selector#
It is also possible to remove existing predicates, and by extension output lanes, from a Stream Selector stage.
As mentioned above, setting the predicates attribute directly will “reset” all conditions and output lanes for the stage.
Thus, setting it to an empty list will wipe out all conditions except for the base default condition.
This will also disconnect any stages that were previously connected to the output lanes which were removed.
# Set the predicates to an empty list which removes all conditions and output lanes
# This also disconnects any stages that were connected to the output lanes that have been removed
stream_selector.predicates = []
# Verify the new predicates value has been reset to only the "default" condition
stream_selector.predicates
Output:
# stream_selector.predicates
[{'predicate': 'default', 'outputLane': 'StreamSelector_1OutputLane16922482979290'}]
If you wish to remove only a single predicate from the list of predicates, you can do so using the remove_predicate method.
The method expects a single predicate as an argument which must be the full dictionary value of the predicate and corresponding output lane.
For example, if you wanted to remove the "${record:value('/employeeName') == 'George Constanza'}" condition from the list of predicates, the following commands would remove it from the stage:
# Grab the full predicate dictionary from the list of predicates
predicate = next(predicate for predicate in stream_selector.predicates if predicate['predicate'] == "${record:value('/employeeName') == 'George Constanza'}")
# Output the predicate to make sure it's the correct one
predicate
# Remove the predicate via the remove_predicate method
stream_selector.remove_predicate(predicate)
# Verify the predicate has been removed, only 5 should remain
stream_selector.predicates
Output:
# predicate
{'outputLane': 'StreamSelector_1OutputLane1692224138828', 'predicate': "${record:value('/employeeName') == 'George Constanza'}"}
# stream_selector.predicates
[{'predicate': "${record:value('/employeeName') == 'Newman'}", 'outputLane': 'StreamSelector_1OutputLane16922495589631'},
{'predicate': "${record:value('/employeeName') == 'Cosmo Kramer'}", 'outputLane': 'StreamSelector_1OutputLane16922495589620'},
{'outputLane': 'StreamSelector_1OutputLane1692224137959', 'predicate': "${record:value('/expense') >= 10000}"},
{'outputLane': 'StreamSelector_1OutputLane1692224137294', 'predicate': "${record:value('/expense') < 10000}"},
{'outputLane': 'StreamSelector_1OutputLane1692224133318', 'predicate': 'default'}]
Hint
The remove_predicate method will automatically handle disconnecting any stages that were connected to the condition that you removed.
This means that after removing the predicate, you will have stage(s) in the pipeline that will need to be removed or reconnected to other output streams.
Connecting Event Streams#
To add event streams on the Pipeline Canvas in the UI, click the ‘Produce Events’ checkbox on the stage you wish to generate events from as shown below:
Once the ‘Produce Events’ checkbox has been clicked, an event stream symbol should appear on the stage. Then, proceed to link the stage’s event lane to another stage as shown below:
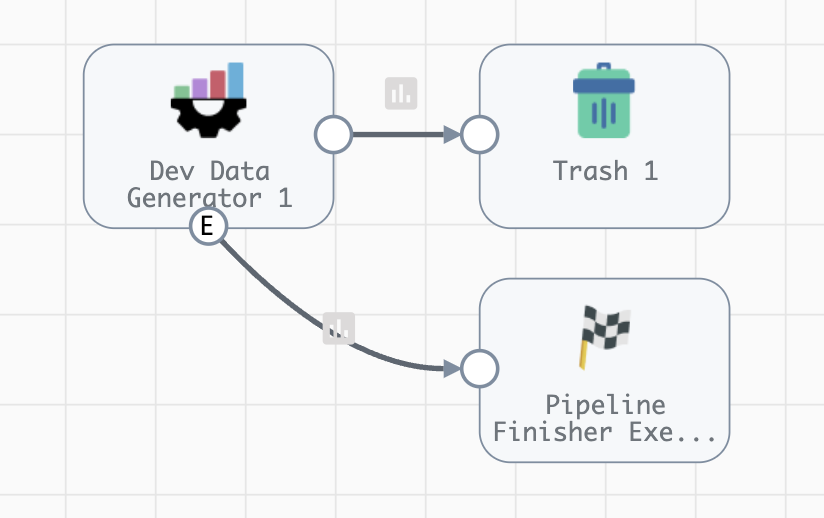
With streamsets.sdk.sch_models.SchSdcStage instances in hand, you can connect a stage’s event stream to another stage using the >=
operator. Connecting the Dev Raw Data Source origin and Trash destination from the example above would look
like the following:
pipeline_finisher = pipeline_builder.add_stage('Pipeline Finisher Executor')
dev_raw_data_source >= pipeline_finisher
You can also use the streamsets.sdk.sch_models.SchSdcStage.connect_inputs() or streamsets.sdk.sch_models.SchSdcStage.connect_outputs() methods to connect a stage’s event stream to another stage.
To connect a stage’s event stream to another stage using either of these methods, set the event_lane parameter to True:
# connect dev_raw_data_source's event stream to pipeline_finisher
dev_raw_data_source.connect_outputs(stages=[pipeline_finisher], event_lane=True)
# alternatively, you can also use connect_inputs to connect dev_raw_data_source's event stream to pipeline_finisher
pipeline_finisher.connect_inputs(stages=[dev_raw_data_source], event_lane=True)
Removing Stages From the Pipeline Builder#
Once a stage has been added, you can remove that stage using the Pipeline Canvas UI, seen below:
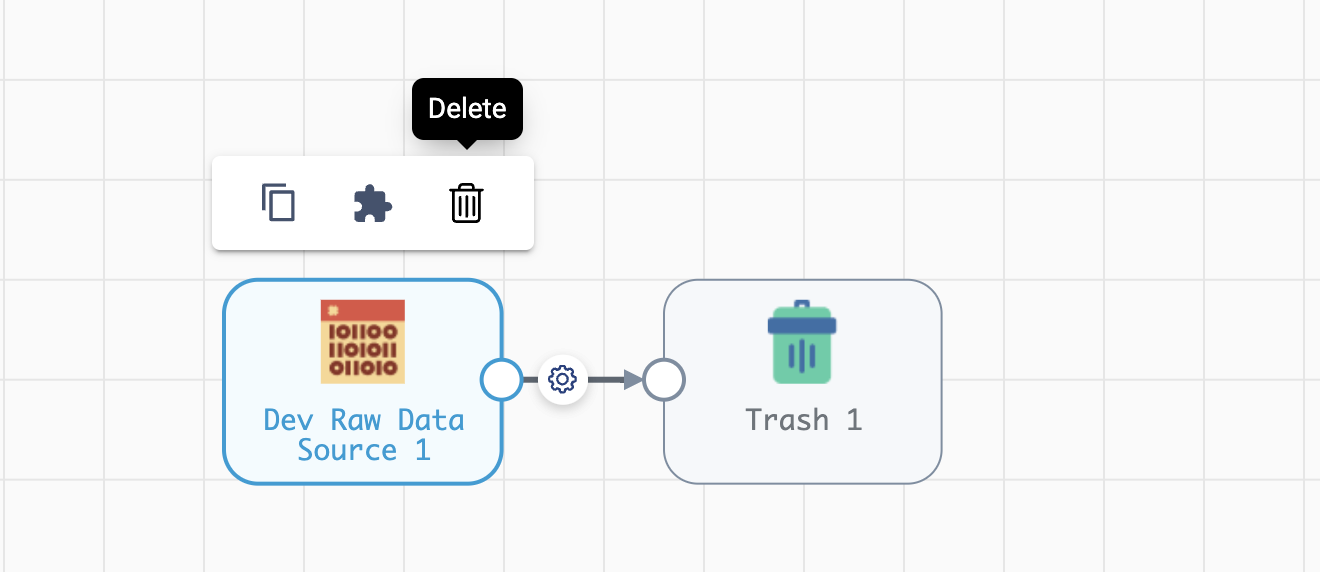
To remove stages from the pipeline_builder using the SDK, utilize the streamsets.sdk.sch_models.PipelineBuilder.remove_stage()
method - see the API reference for this method for details on the arguments this method accepts.
For this example, you can delete the Dev Raw Data Source origin like this:
pipeline_builder.remove_stage(dev_raw_data_source)
Note
Removing a stage from a streamsets.sdk.sch_models.PipelineBuilder instance also removes all output & input lane references that any connected stages had to this stage.
Building the Pipeline From the PipelineBuilder#
Once the stages are connected, you can build the streamsets.sdk.sch_models.Pipeline instance with
the streamsets.sdk.sch_models.PipelineBuilder.build() method:
pipeline = pipeline_builder.build('My first pipeline')
pipeline
Output:
<Pipeline (pipeline_id=None, commit_id=None, name=My first pipeline, version=None)>
When building a Transformer for Snowflake pipeline, there are 4 parameters required by the Pipeline Canvas UI, seen below:
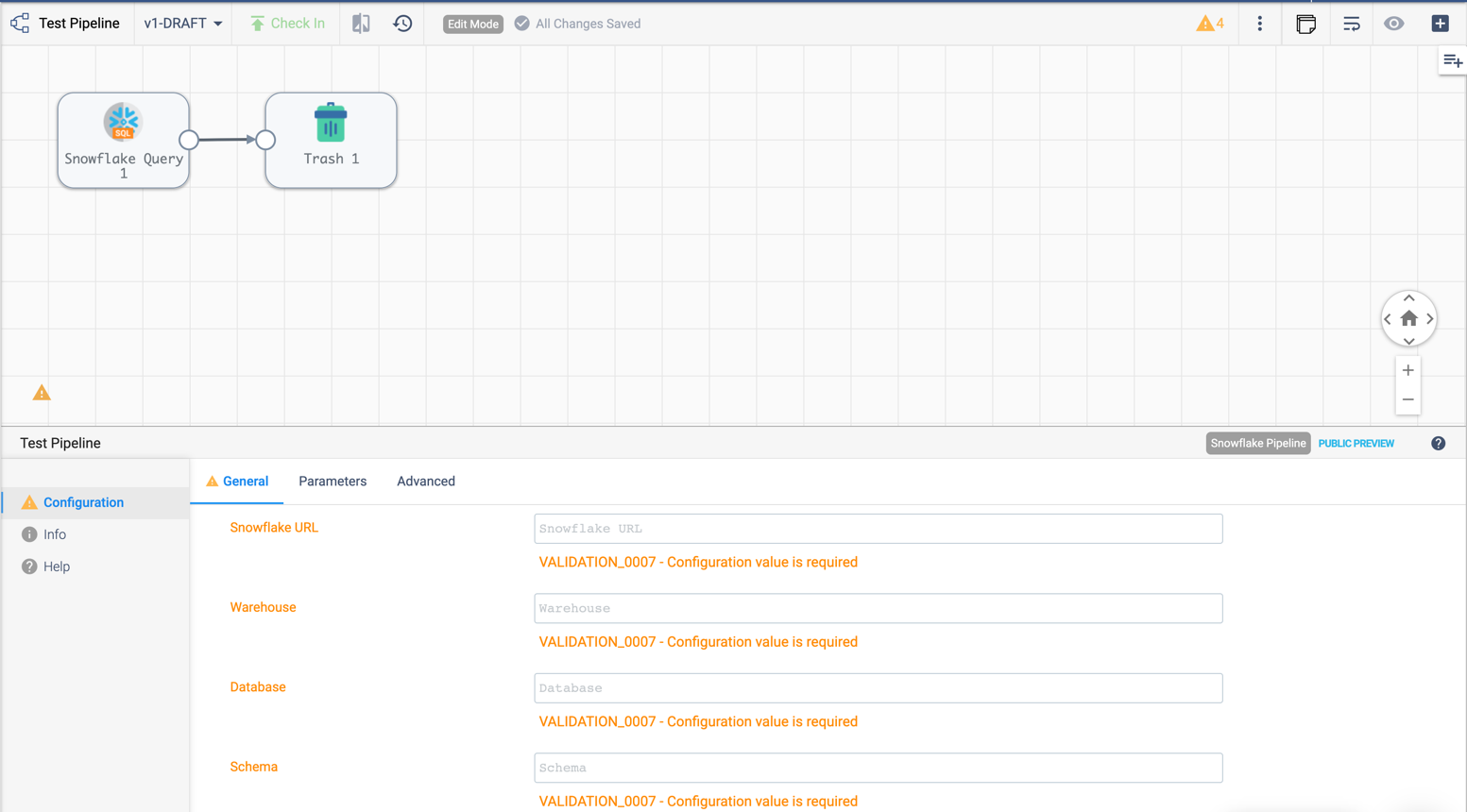
Default values for them can be set in your account (My Account > Snowflake Settings > Snowflake Pipeline Defaults). If they aren’t set, or you want to modify those values, you must do so before publishing the pipeline:
pipeline.configuration['connectionString'] = <Account URL>
pipeline.configuration['warehouse'] = <Warehouse>
pipeline.configuration['db'] = <Database>
pipeline.configuration['schema'] = <Schema>
Importing a Pipeline into the Pipeline Builder#
It is possible to use an existing pipeline as the starting point when creating another pipeline.
Creating a Pipeline based off of an existing Pipeline entails importing an existing streamsets.sdk.sch_models.Pipeline instance into the streamsets.sdk.sch_models.PipelineBuilder object.
Importing a pipeline into the streamsets.sdk.sch_models.PipelineBuilder instance can be performed by making use of the streamsets.sdk.sch_models.PipelineBuilder.import_pipeline() method:
pipeline_to_import = sch.pipelines.get(name='Pipeline To Import')
pipeline_builder.import_pipeline(pipeline_to_import)
Add the Pipeline to Platform#
To add (commit) the pipeline to your Platform organization, you can use the Check In button as seen below:
To add a pipeline to your Platform organization using the SDK, pass the built pipeline to the
streamsets.sdk.ControlHub.publish_pipeline() method:
sch.publish_pipeline(pipeline, commit_message='First commit of my first pipeline')
Output:
<streamsets.sdk.sch_api.Command object at 0x7f8f2e0579b0>
Bringing It All Together#
The complete scripts from this section can be found below (excluding the Special Case sections for multi-lane stages and Stream Selector stage).
Commands that only served to verify some output from the example have been removed.
from streamsets.sdk import ControlHub
sch = ControlHub(credential_id='<credential_id>', token='<token>')
sdc = sch.engines.get(engine_url='<data_collector_url>')
pipeline_builder = sch.get_pipeline_builder(engine_type='data_collector', engine_id=sdc.id)
#transformer = sch.engines.get(engine_url='<transformer_url>', engine_type='TRANSFORMER')
#pipeline_builder = sch.get_pipeline_builder(engine_type='transformer', engine_id=transformer.id)
dev_raw_data_source = pipeline_builder.add_stage('Dev Raw Data Source')
trash = pipeline_builder.add_stage('Trash')
dev_raw_data_source >> trash
# connect dev_raw_data_source to trash
#dev_raw_data_source.connect_outputs(stages=[trash])
# alternatively, you can also use connect_inputs to connect dev_raw_data_source to trash
#trash.connect_inputs(stages=[dev_raw_data_source])
# connect dev_raw_data_source's event stream to pipeline_finisher
#dev_raw_data_source >= pipeline_finisher
#dev_raw_data_source.connect_outputs(stages=[pipeline_finisher], event_lane=True)
# alternatively, you can also use connect_inputs to connect dev_raw_data_source's event stream to pipeline_finisher
#pipeline_finisher.connect_inputs(stages=[dev_raw_data_source], event_lane=True)
# disconnect dev_raw_data_source from trash
#dev_raw_data_source.disconnect_output_lanes(stages=[trash])
# alternatively, you can also use disconnect_input_lanes to disconnect dev_raw_data_source from trash
#trash.disconnect_input_lanes(stages=[dev_raw_data_source])
# Remove an existing stage by passing it into the remove_stage method
# pipeline_builder.remove_stage(dev_raw_data_source)
# Import an existing pipeline into the pipeline_builder object to use as a starting point
#pipeline_to_import = sch.pipelines.get(name='Pipeline To Import')
#pipeline_builder.import_pipeline(pipeline_to_import)
pipeline = pipeline_builder.build('My first pipeline')
sch.publish_pipeline(pipeline, commit_message='First commit of my first pipeline')
Transformer For Snowflake:
from streamsets.sdk import ControlHub
sch = ControlHub(credential_id='<credential_id>', token='<token>')
pipeline_builder = sch.get_pipeline_builder(engine_type='snowflake')
snowflake_query_origin = pipeline_builder.add_stage('Snowflake Query')
trash = pipeline_builder.add_stage('Trash')
snowflake_query_origin >> trash
pipeline = pipeline_builder.build('My first pipeline')
sch.publish_pipeline(pipeline, commit_message='First commit of my first pipeline')