Azure Event Hubs
The Azure Event Hubs origin reads data from a single event hub in Microsoft Azure Event Hubs.
When you configure the origin, you specify the event hub to use and connection information for the event hub. You define a consumer group name and select the default offset to use: latest or earliest. When needed, you can define specific offsets for individual partitions. You can also configure the maximum batch size to use.
Before you use the Azure Event Hubs origin, complete the prerequisite tasks.
Prerequisites
Complete the following prerequisites, as needed, before you configure the Azure Event Hubs origin.
- Authorize access
to the event hub using shared access signatures.
The Azure Event Hubs origin requires read access to the event hub. For information about assigning access to Azure Event Hubs resources, see the Azure documentation.
The origin does not support access through Active Directory at this time.
- Retrieve the Azure
Event Hubs connection string.When you configure the Azure Event Hubs origin, you must provide the namespace, shared access policy, and shared access key. These details are included on the Azure Event Hubs connection string, as follows:
Endpoint=sb://<namespace>.servicebus.windows.net/;SharedAccessKeyName=<shared access policy>;SharedAccessKey=<shared access key>For information about retrieving the connection string, see the Azure documentation.
Default and Specific Offsets
The Azure Event Hubs origin can start reading from the earliest record in partitions or from a specified offset for partitions. It can also read only new data that arrives as the pipeline runs.
When you configure the origin, you can optionally define specific offsets to use for individual partitions. When you define a specific offset, you specify the partition ID and the sequence number where you want to start the read. Both partition IDs and sequence numbers typically start with 0.
- Earliest - The origin reads all available data in the partition before processing incoming data.
- Latest - The origin reads only the data that arrives after you start the pipeline.
For example, say you have four partitions with IDs 0-3. You want to read the first partition from the 100th record in the partition. For all other partitions, you want only events that arrive after you start the pipeline. The following configuration achieves this behavior:
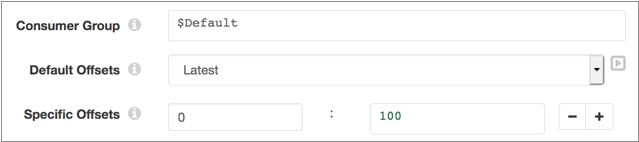
Configuring an Azure Event Hubs Origin
-
On the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Load Data Only Once Reads data while processing the first batch of a pipeline run and caches the results for reuse throughout the pipeline run. Select this property for lookup origins. When configuring lookup origins, do not limit the batch size. All lookup data should be read in a single batch.
Cache Data Caches data processed for a batch so the data can be reused for multiple downstream stages. Use to improve performance when the stage passes data to multiple stages. Caching can limit pushdown optimization when the pipeline runs in ludicrous mode.
Available when Load Data Only Once is not enabled. When the origin loads data once, the origin caches data for the entire pipeline run.
Skip Offset Tracking Skips tracking offsets. The origin reads all available data for each batch that the pipeline processes, limited by any batch-size configuration for the origin.
-
On the Event Hub tab, configure the following
properties:
Event Hub Property Description Namespace Name Name of the namespace that contains the event hub. For help with retrieving this information, see Prerequisites.
Event Hub Name Event hub to read from. Shared Access Policy Name Name of the shared access policy associated with the namespace. When appropriate, you can use the default shared access key policy,
RootManageSharedAccessKey.For help with retrieving this information, see Prerequisites.
Shared Access Key One of the shared access keys associated with the specified shared access policy. For help with retrieving this information, see Prerequisites.
Consumer Group Name of the consumer group to create to read from the event hub. Default Offsets Offset to read from when starting the pipeline: - Earliest - The origin reads all available data in the partition before processing incoming data.
- Latest - The origin reads only the data that arrives after you start the pipeline.
Used for any partitions that do not have specified offsets defined.
Specific Offsets Offset to read from for the specified partitions when starting the pipeline. Define the partition ID and the sequence number to use as the offset for the partition. The origin starts reading from the specified sequence number, inclusive.
Click the Add icon to configure additional partition offsets. You can use simple or bulk edit mode to configure the offsets.
Max Batch Size Maximum number of events to read in a batch. -
On the Data Format tab, configure the following
property:
Data Format Property Description Data Format Format of the data to write. Select one of the following formats: - Avro
- Delimited
- JSON
- Text
-
For Avro data, click the Schema tab and configure the
following properties:
Avro Property Description Avro Schema Location Location of the Avro schema definition to use to process data: - In Pipeline Configuration - Use the schema specified in the Avro Schema property.
- Confluent Schema Registry - Retrieve the schema from Confluent Schema Registry.
Avro Schema Avro schema definition used to process the data. Overrides any existing schema definitions associated with the data. You can optionally use the
runtime:loadResourcefunction to use a schema definition stored in a runtime resource file.Available when Avro Schema Location is set to In Pipeline Configuration.
Register Schema Registers the specified Avro schema with Confluent Schema Registry. Available when Avro Schema Location is set to In Pipeline Configuration.
Schema Registry URLs Confluent Schema Registry URLs used to look up the schema. To add a URL, click Add. Use the following format to enter the URL: http://<host name>:<port number>Available when Avro Schema Location is set to In Pipeline Configuration.
Basic Auth User Info Confluent Schema Registry basic.auth.user.infocredential.Available when Avro Schema Location is set to Confluent Schema Registry.
Lookup Schema By Method used to look up the schema in Confluent Schema Registry: - Subject - Look up the specified Avro schema subject.
- Schema ID - Look up the specified Avro schema ID.
Available when Avro Schema Location is set to In Pipeline Configuration.
Schema Subject Avro schema subject to look up in Confluent Schema Registry. If the specified subject has multiple schema versions, the origin uses the latest schema version for that subject. To use an older version, find the corresponding schema ID, and then set the Look Up Schema By property to Schema ID.
Available when Avro Schema Location is set to In Pipeline Configuration.
Schema ID Avro schema ID to look up in the Confluent Schema Registry. Available when Avro Schema Location is set to In Pipeline Configuration.
-
For delimited data, on the Data Format tab, configure the
following property:
Delimited Property Description Delimiter Character Delimiter character to use in the data. Select one of the available options or select Other to enter a custom character. You can enter a Unicode control character using the format \uNNNN, where N is a hexadecimal digit from the numbers 0-9 or the letters A-F. For example, enter \u0000 to use the null character as the delimiter or \u2028 to use a line separator as the delimiter.
Quote Character Quote character to use in the data. Escape Character Escape character to use in the data -
To use a custom schema for delimited or JSON data, click the
Schema tab and configure the following
properties:
Schema Property Description Schema Mode Mode that determines the schema to use when processing data: - Infer from Data
The origin infers the field names and data types from the data.
- Use Custom Schema - JSON Format
The origin uses a custom schema defined in the JSON format.
- Use Custom Schema - DDL Format
The origin uses a custom schema defined in the DDL format.
Note that the schema is applied differently depending on the data format of the data.
Schema Custom schema to use to process the data. Enter the schema in DDL or JSON format, depending on the selected schema mode.
Error Handling Determines how the origin handles parsing errors: - Permissive - When the origin encounters a problem parsing any field in the record, it creates a record with the field names defined in the schema, but with null values in every field.
- Drop Malformed - When the origin encounters a problem parsing any field in the record, it drops the entire record from the pipeline.
- Fail Fast - When the origin encounters a problem parsing any field in the record, it stops the pipeline.
Original Data Field Field where the data from the original record is written when the origin cannot parse the record. When writing the original record to a field, you must add the field to the custom schema as a String field.
Available when using permissive error handling.
- Infer from Data