Performing Lookups
To insert lookup data into a Transformer pipeline, you can either add a lookup processor to the pipeline or add an origin with a Join processor to the pipeline.
Transformer provides several system-related lookup processors, such as the Delta Lake Lookup processor and the Snowflake Lookup processor. You can also use the JDBC Lookup processor to perform a lookup on a database table.
To look up data from other systems, such as Amazon S3 or a file directory, use an additional origin in the pipeline to read the lookup data. Then, use a Join processor to join the lookup data with the primary pipeline data.
Configuring a Lookup with an Origin and Join Processor
In the Join processor, in most cases, you use either the right outer or left outer join type. The type to use depends on how you join the data in the Join processor. If the primary data in the pipeline is the left input stream of the Join processor, use the left outer join type to return all of the primary data with the additional lookup data added to those records. If the primary data is the right input stream of the Join processor, use the right outer join type.
When necessary, you can join lookup data to multiple streams of data. You simply need to use a separate Join processor to join the lookup origin to each stream.
When configuring lookup origins, do not limit the batch size. All lookup data should be read in a single batch.
If the pipeline execution mode is streaming or the primary origin reads from multiple tables, then enable the Load Data Only Once property in the lookup origin. With this configuration, the lookup origin reads one batch of data and caches it for reuse. Each time the primary origin passes a new data set to the Join processor, the processor joins the data set with the cached lookup data.
Streaming Lookup Example
Say your streaming
pipeline processes sales data that includes item IDs, and you want to use the IDs to
retrieve additional data for each item from an Items file. To do this,
you create the following pipeline:
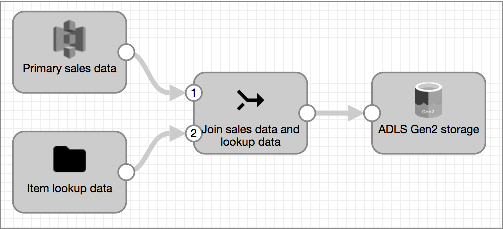
- Configure one origin to read the primary pipeline data, then connect it to the
Join processor.
As the first stage connected to the Join processor, the origin passes data to the processor through the left input stream.
- Configure another origin for the lookup data:
- In the lookup origin, on the General tab, select the Load Data Only Once property. This enables the origin to read the lookup data once and cache it for reuse.
- Some origins provide properties that limit the size of each batch. When configuring the origin, do not limit the batch size. All lookup data should be read in a single batch.
- Connect the lookup origin to the Join processor.
As the second stage connected to the Join processor, the origin passes lookup data to the processor through the right input stream.
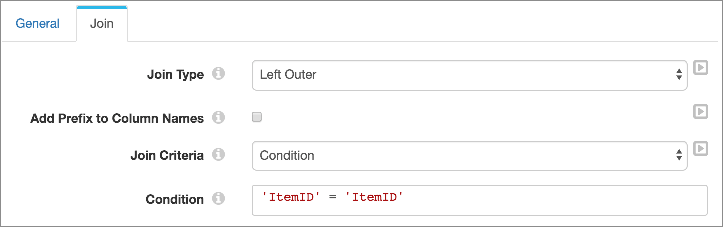
- Configure the Join processor.
Since the primary pipeline data moves through the left input stream, use the left outer join type. Then, you specify the join condition for the lookup, as follows:
- Configure the rest of the pipeline.
Processing
When you run the pipeline, both origins start processing available data. The primary origin begins processing the primary pipeline data, and the lookup origin processes and caches the lookup data from the first batch.
The Join processor joins data from the primary origin with the data from the lookup origin based on the lookup condition and passes the results downstream.
As additional data from the primary origin passes to the Join processor, the processor joins the data with the cached lookup data.