Google Dataproc
You can run Transformer pipelines using Spark deployed on a Google Dataproc cluster. Transformer supports several Dataproc versions. For a complete list, see Cluster Compatibility Matrix.
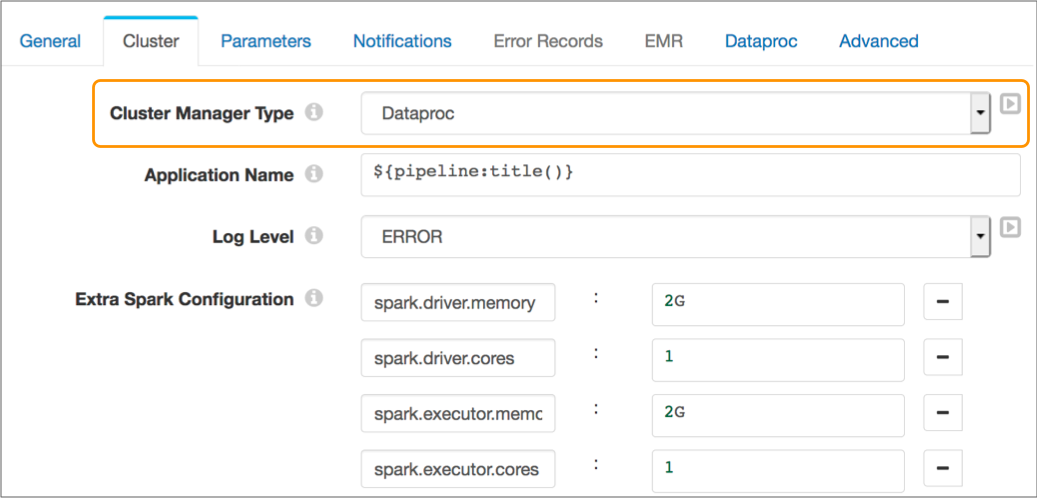
To run a pipeline on a Dataproc cluster, configure the pipeline to use Dataproc as the cluster manager type on the Cluster tab of the pipeline properties.
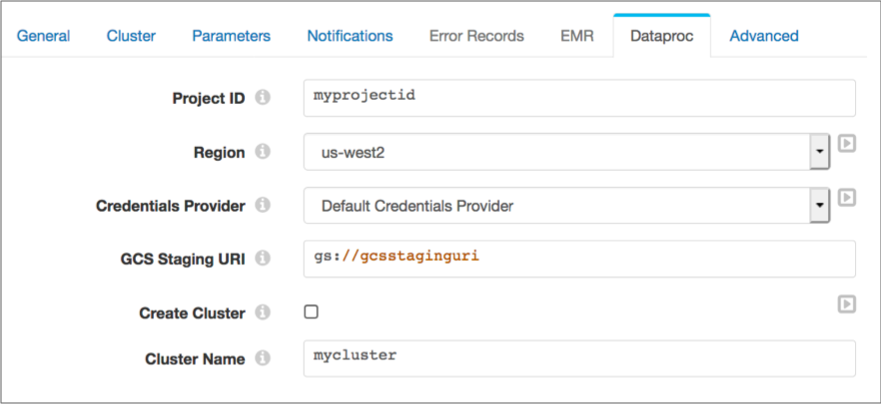
When you configure a pipeline to run on a Dataproc cluster, you specify the Google Cloud project ID and region, and the credentials provider and related properties. You define the staging URI within Google Cloud to store the Transformer libraries and resources needed to run the pipeline.
You can specify an existing cluster to use or you can have Transformer provision a cluster to run the pipeline.
When configuring the pipeline, be sure to include only the supported stages.
The following image shows the Cluster tab of a pipeline configured to run on a Dataproc cluster:
The following image shows the Dataproc tab configured to run the pipeline on an existing Dataproc cluster:
Supported Stages
Transformer does not support using all available stages in pipelines that run on Dataproc clusters at this time.
- Amazon Redshift stage libraries
- AWS Transformer-provided libraries for Hadoop 2.7.7
- Basic stage library, except for the PySpark Evaluator processor
- Google Cloud cluster-provided stage libraries
- JDBC stage libraries
Credentials
To run a pipeline on a Dataproc cluster, you must configure the pipeline to pass Google credentials to Dataproc.
You can provide credentials using one the following options:
- Google Cloud default credentials
- Credentials in a file
- Credentials in a stage property
Default Credentials
You can
configure the pipeline to use Google Cloud default credentials. When using
Google Cloud default credentials, Transformer checks for the credentials file defined in the GOOGLE_APPLICATION_CREDENTIALS
environment variable.
If the environment variable doesn't exist and Transformer is running on a virtual machine (VM) in Google Cloud Platform (GCP), the stage uses the built-in service account associated with the virtual machine instance.
For more information about the default credentials, see Finding credentials automatically in the Google Cloud documentation.
Complete the following steps to define the credentials file in the environment variable:- Use the Google Cloud Platform Console or the
gcloudcommand-line tool to create a Google service account and have your application use it for API access.For example, to use the command line tool, run the following commands:gcloud iam service-accounts create my-account gcloud iam service-accounts keys create key.json --iam-account=my-account@my-project.iam.gserviceaccount.com - Store the generated credentials file in a local directory external to the Transformer installation directory. For example, if you installed Transformer in the following directory:
you might store the credentials file at:/opt/transformer//opt/transformer-credentials - Add the
GOOGLE_APPLICATION_CREDENTIALSenvironment variable to the appropriate file and point it to the credentials file.Modify environment variables using the method required by your installation type.
Set the environment variable as follows:
export GOOGLE_APPLICATION_CREDENTIALS="/var/lib/transformer-resources/keyfile.json" - Restart Transformer to enable the changes.
- On the Dataproc tab, for the Credential Provider property, select Default Credentials Provider.
Credentials in a File
You can configure the pipeline to use credentials in a Google Cloud service account credentials JSON file.
Complete the following steps to use credentials in a file:
- Generate a service account credentials file in JSON format.
Use the Google Cloud Platform Console or the
gcloudcommand-line tool to generate and download the credentials file. For more information, see Generating a service account credential in the Google Cloud Platform documentation. - Store the generated credentials file on the Transformer machine.
As a best practice, store the file in the Transformer resources directory,
$TRANSFORMER_RESOURCES. - On the Dataproc tab for the pipeline, for the Credential Provider property, select Service Account Credentials File. Then, enter the path to the credentials file.
Credentials in a Property
You can configure the pipeline to use credentials specified in a property. When using credentials in a property, you provide JSON-formatted credentials from a Google Cloud service account credential file.
You can enter credential details in plain text, but best practice is to secure the credential details using runtime resources or a credential store.
Complete the following steps to use credentials specified in pipeline properties:
- Generate a service account credentials file in JSON format.
Use the Google Cloud Platform Console or the
gcloudcommand-line tool to generate and download the credentials file. For more information, see Generating a service account credential in the Google Cloud Platform documentation. - As a best practice, secure the credentials using runtime resources or a credential store.
- On the Dataproc tab for the pipeline, for the Credential Provider property, select Service Account Credentials. Then, enter the JSON-formatted credential details or an expression that calls the credentials from a credential store.
Existing Cluster
You can configure a pipeline to run on an existing Dataproc cluster.
To run a pipeline on an existing Dataproc cluster, on the Dataproc tab, clear the Create Pipeline property, then specify the name of the cluster to use.
When a Dataproc cluster runs a Transformer pipeline, Transformer libraries are stored on the GCS staging URI so they can be reused.
For best practices for configuring a cluster, see the Google Dataproc documentation.
Provisioned Cluster
You can configure a pipeline to run on a provisioned cluster. When provisioning a cluster, Transformer creates a new Dataproc Spark cluster upon the initial run of a pipeline. You can optionally have Transformer terminate the cluster after the pipeline stops.
To provision a cluster for the pipeline, select the Create Cluster property on the Dataproc tab of the pipeline properties. Then, define the cluster configuration properties.
When provisioning a cluster, you specify cluster details such as the Dataproc image version, the machine and network types to use, and the cluster prefix to use for the cluster name. You also indicate whether to terminate the cluster after the pipeline stops.
You can define the number of worker instances that the cluster uses to process data. The minimum is 2. To improve performance, you might increase that number based on the number of partitions that the pipeline uses.
For a full list of Dataproc provisioned cluster properties, see Configuring a Pipeline. For more information about configuring a cluster, see the Dataproc documentation.
GCS Staging URI
To run pipelines on a Dataproc cluster, Transformer must store files in a staging directory on Google Cloud Storage.
You can configure the root directory to use as the staging directory. The default staging directory is /streamsets.
- The location must exist before you start the pipeline.
- When a pipeline runs on an existing cluster, configure pipelines to use the same staging directory so that each Spark job created within Dataproc can reuse the common files stored in the directory.
- Pipelines that run on different clusters can use the same staging directory as long as the pipelines are started by the same Transformer instance. Pipelines that are started by different instances of Transformer must use different staging directories.
- When a pipeline runs on a provisioned cluster, using the same staging directory for pipelines is best practice, but not required.
- Files that can be reused across pipelines
- Transformer stores files that can be reused across pipelines, including Transformer libraries and external resources such as JDBC drivers, in the following location:
- Files specific to each pipeline
- Transformer stores files specific to each pipeline, such as the pipeline JSON file and resource files used by the pipeline, in the following directory:
Accessing Dataproc Job Details
When you start a pipeline on a Dataproc cluster, Transformer submits a Dataproc job to the cluster which launches a Spark application.
- After the corresponding Control Hub job completes, on the History tab of the job, click View Summary for the job run. In the Job Metrics Summary, copy the Dataproc Job URL and paste it into the address bar of the browser to access the Dataproc job in the Google Cloud Console.
- Log into the Google Cloud Console and view the list of jobs run on the Dataproc
cluster. Filter the jobs by one of the following labels which are applied to all
Dataproc jobs run for Transformer pipelines:
-
streamsets-transformer-pipeline-id- ID of the Control Hub job that includes the Transformer pipeline. streamsets-transformer-pipeline-name- Name of the Transformer pipeline.
Label values must meet the Google Cloud requirements for Dataproc labels. As a result, the label values might differ slightly from the job ID and pipeline name that display in Control Hub. To meet Google Cloud requirements, StreamSets trims the values to a maximum of 63 characters, converts all characters to lowercase, and replaces an illegal character with an underscore. For example, the pipeline name
ORACLE{WRITE}is converted tooracle_write_to meet the requirements. -