Installing Transformer
The method that you use to install Transformer depends on the location of your Spark installation and where you choose to install Transformer.
- Local Spark installation - To get started with Transformer in a development environment, you can simply install both Transformer and Spark on the same machine and run Spark locally on that machine. You develop and run Transformer pipelines on the single machine.
- Cluster Spark installation - In a production environment, use a Spark installation that runs on a cluster to leverage the performance and scale that Spark offers. Install Transformer on a machine that is configured to submit Spark jobs to the cluster. You develop Transformer pipelines locally on the machine where Transformer is installed. When you run Transformer pipelines, Spark distributes the processing across nodes in the cluster.
- Cloud Spark installation - When you have Spark installed in the cloud, you can use the Azure marketplace to install Transformer as a cloud service. When you run Transformer as a cloud service, you can easily run pipelines on cloud vendor Spark clusters such as Databricks and EMR.
After installing Transformer from a tarball, as a best practice, configure Transformer to use directories outside of the runtime directory.
If you use Docker, you can also run the Transformer image from Docker Hub.
Choosing an Installation Package
You can use Transformer prebuilt with the following Scala version:
- Scala 2.12 - Use with Spark 3.x. Requires Java JDK 11.
The Scala version that Transformer is built with determines the Java JDK version that must be installed on the Transformer machine and the Spark versions that you can use with Transformer. The Spark version that you choose determines the cluster types and the Transformer features that you can use.
For example, Amazon EMR 7.5 clusters use Spark 3.5. To run Transformer pipelines on those clusters, you use Transformer prebuilt with Scala 2.12. And since Transformer prebuilt with Scala 2.12 requires Java JDK 11, you install that JDK version on the Transformer machine.
For more information, see Cluster Compatibility Matrix, Scala, Spark, and Java JDK Requirements, and Spark Versions and Available Features.
Installing when Spark Runs Locally
To get started with Transformer in a development environment, install both Transformer and Spark on the same machine. This allows you to easily develop and test local pipelines, which run on the local Spark installation.
All users can install Transformer from a tarball and run it manually. Users with an enterprise account can install Transformer from an RPM package and run it as a service. Installing an RPM package requires root privileges.
transformer. If a transformer user and a
transformer group do not exist on the machine, the installation
creates the user and group for you and assigns them the next available user ID and group
ID.transformer user
and group, create the user and group before installation and specify the IDs that
you want to use. For example, if you're installing Transformer on
multiple machines, you might want to create the system user and group before
installation to ensure that the user ID and group ID are consistent across the
machines.Before you start, ensure that the machine meets all installation requirements and choose the installation package that you want to use.
-
Download the Transformer installation package from one of the following locations:
- StreamSets Support portal if you have an enterprise account.
- StreamSets website if you do not have an enterprise account.
If using the RPM package, download the appropriate package for your operating system:
- For CentOS 6, Oracle Linux 6, or Red Hat Enterprise Linux 6, download the RPM EL6 package.
- For CentOS 7, Oracle Linux 7, or Red Hat Enterprise Linux 7, download the RPM EL7 package.
-
If you downloaded the tarball, use the following command to extract the tarball
to the desired location:
tar xf streamsets-transformer-all_<scala version>-<transformer version>.tgz -C <extraction directory>For example, to extract Transformer version 6.1.0 prebuilt with Scala 2.12.x, use the following command:
tar xf streamsets-transformer-all_2.12-6.1.0.tgz -C /opt/streamsets-transformer/ -
If you downloaded the RPM package, complete the following steps to extract and
install the package:
-
Download Apache Spark from the Apache Spark Download page to the same machine as the Transformer installation.
Download a supported Spark version that is valid for the Transformer features that you want to use.
- Extract the downloaded Spark file.
-
Add the SPARK_HOME environment variable to the Transformer environment configuration file to define the Spark installation path on the
Transformer machine.
Modify environment variables using the method required by your installation type.
Set the environment variable as follows:export SPARK_HOME=<Spark path>For example:export SPARK_HOME=/opt/spark-2.4.0-bin-hadoop2.7/
Installing when Spark Runs on a Cluster
All users can install Transformer from a tarball and run it manually. Users with an enterprise account can install Transformer from an RPM package and run it as a service. Installing an RPM package requires root privileges.
transformer. If a transformer user and a
transformer group do not exist on the machine, the installation
creates the user and group for you and assigns them the next available user ID and group
ID.transformer user
and group, create the user and group before installation and specify the IDs that
you want to use. For example, if you're installing Transformer on
multiple machines, you might want to create the system user and group before
installation to ensure that the user ID and group ID are consistent across the
machines.Before you start, ensure that the machine meets all installation requirements and choose the installation package that you want to use.
-
Download the Transformer installation package from one of the following locations:
- StreamSets Support portal if you have an enterprise account.
- StreamSets website if you do not have an enterprise account.
If using the RPM package, download the appropriate package for your operating system:
- For CentOS 6, Oracle Linux 6, or Red Hat Enterprise Linux 6, download the RPM EL6 package.
- For CentOS 7, Oracle Linux 7, or Red Hat Enterprise Linux 7, download the RPM EL7 package.
-
If you downloaded the tarball, use the following command to extract the tarball
to the desired location:
tar xf streamsets-transformer-all_<scala version>-<transformer version>.tgz -C <extraction directory>For example, to extract Transformer version 6.1.0 prebuilt with Scala 2.12.x, use the following command:
tar xf streamsets-transformer-all_2.12-6.1.0.tgz -C /opt/streamsets-transformer/ -
If you downloaded the RPM package, complete the following steps to extract and
install the package:
-
Edit the Transformer configuration file,
$TRANSFORMER_CONF/transformer.properties.
-
Add the following environment variables to the Transformer environment configuration file.
Modify environment variables using the method required by your installation type.
Environment Variable Description JAVA_HOME Path to the Java installation on the machine. SPARK_HOME Path to the Spark installation on the machine. Required for Hadoop YARN and Spark standalone clusters only. Clusters can include multiple Spark installations. Be sure to point to a supported Spark version that is valid for the Transformer features that you want to use.
On Cloudera CDH clusters, Spark is generally installed into the parcels directory. For example, for CDH 6.3, you might use: /opt/cloudera/parcels/CDH/lib/spark.
Tip: To verify the version of a Spark installation, you can run thespark-shellcommand. Then, usesc.getConf.get("spark.home")to return the installation location.HADOOP_CONF_DIR or YARN_CONF_DIR Directory that contains the client side configuration files for the Hadoop cluster. Required for Hadoop YARN and Spark standalone clusters only. For more information about these environment variables, see the Apache Spark documentation.
Enabling Kerberos for Hadoop YARN Clusters
When a Hadoop YARN cluster uses Kerberos authentication, Transformer uses the user who starts the pipeline as the proxy user to launch the Spark application and to access files in the Hadoop system, unless you configure a Kerberos principal and keytab for the pipeline. The Kerberos keytab source can be defined in the Transformer properties file or in the pipeline configuration.
Using a Kerberos principal and keytab enables Spark to renew Kerberos tokens as needed, and is strongly recommended. For more information about how to configure pipelines when Kerberos is enabled, see Kerberos Authentication.
Before pipelines can use proxy users or use the keytab source defined in the Transformer properties file, you must enable these options in the Transformer installation.
Enabling Proxy Users
Before pipelines can use proxy users with Kerberos authentication, you must install
the required Kerberos client packages on the Transformer machine and then configure the environment variables used by the K5start
program.
-
On Linux, install the following Kerberos client packages on the Transformer machine:
krb5-workstationkrb5-clientK5start, also known askstart
- Copy the keytab file that contains the credentials for the Kerberos principal to the Transformer machine.
-
Add the following environment variables to the Transformer environment configuration file.
Modify environment variables using the method required by your installation type.
Environment Variable Description TRANSFORMER_K5START_CMD Absolute path to the K5startprogram on the Transformer machine.TRANSFORMER_K5START_KEYTAB Absolute path and name of the Kerberos keytab file copied to the Transformer machine. TRANSFORMER_K5START_PRINCIPAL Kerberos principal to use. Enter a service principal. - Restart Transformer.
Enabling the Properties File as the Keytab Source
Before pipelines can use the keytab source defined in the Transformer configuration properties, you must configure a Kerberos keytab and principal for Transformer.
-
Copy the keytab file that contains the credentials for the Kerberos principal
to the Transformer machine.
The default location is the Transformer configuration directory, $TRANSFORMER_CONF.
-
Modify the Transformer configuration file,
$TRANSFORMER_CONF/transformer.properties
Configure the following Kerberos properties in the file:
Kerberos Property Description kerberos.client.principal Kerberos principal to use. Enter a service principal. kerberos.client.keytab Path and name of the Kerberos keytab file copied to the Transformer machine. Enter an absolute path or a path relative to the $TRANSFORMER_CONFdirectory. - Restart Transformer.
Installation through the Azure Marketplace
You can install Transformer as a service through the Microsoft Azure marketplace.
If you have an account with Databricks, you can install StreamSets for Databricks through the Azure marketplace. StreamSets for Databricks includes both Data Collector and Transformer on the same virtual machine.
Installing Transformer on Azure
You can install Transformer on Microsoft Azure.
Transformer is installed as an RPM package on a Linux virtual machine hosted on Microsoft Azure. Transformer is available as a service on the instance after the deployment is complete.
- Log in to the Microsoft Azure portal.
- In the Navigation panel, click Create a resource.
-
Search the Marketplace for StreamSets Transformer.
The Marketplace includes a small, medium, and large Transformer offer, based on the maximum number of Spark executors allowed for each pipeline. For more information, see the details in the Marketplace listing or see Spark Executors.
- Select the appropriate Transformer offer, and then click Create.
-
On the page, enter a name for the new virtual machine, the user name to
log in to that virtual machine, and the authentication method to use for
logins.
Important: Do not use transformer as the user name to log in to the virtual machine. The transformer user account must be reserved as the system user account that runs Transformer as a service.
You can create the virtual machine in a new or existing resource group.
You can optionally change the virtual machine size, but the default size is sufficient in most cases. If you change the default, select a size that meets the minimum requirements.
For example, the following configuration creates a Basic A3 size virtual machine named transformer with a user named txuser who can log in using password authentication. The virtual machine is created in a new resource group named transformer:
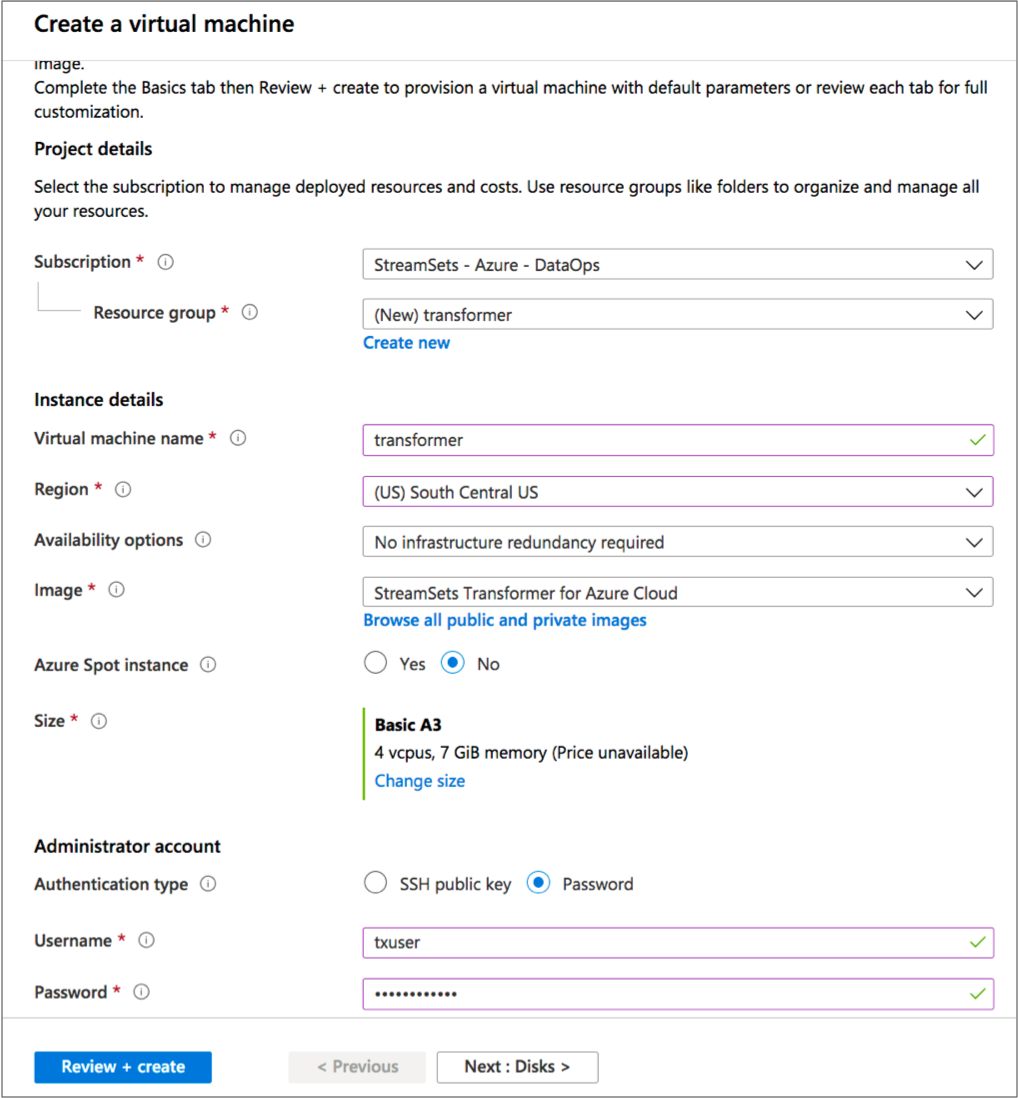
- Click Next.
- On the Disks page under Advanced, verify that Use managed disks is enabled.
- On the Networking page, select an existing group or create a new network security group for the virtual machine.
- On the remaining pages, accept the defaults or configure the optional features.
-
Verify the details in the Review and Create page, and
then click Create.
It can take several minutes for the resource to deploy and for Transformer to start as a service.
- On the Overview page for the deployment, click the name of the network security group.
-
In the Inbound security rules section for the security
group, click the name of each of the following rules and then configure the
range of IP addresses allowed for each port.
Important: By default, the rules give all IP addresses access to Transformer. Be sure to modify the default values to restrict access to known IP addresses only.
Inbound Security Rule Description Transformer Range of IP addresses that can access the Transformer web-based UI on port 19630. default-allow-ssh Range of IP addresses that can use SSH to access the Transformer virtual machine on port 22 to run the Transformer command line interface. Note: If you change the default port or enable HTTPS after installation, you also need to modify the Transformer rule to reflect the changed port number.
Installing StreamSets for Databricks on Azure
You can install StreamSets for Databricks on Microsoft Azure. StreamSets for Databricks includes both Data Collector and Transformer.
Data Collector and Transformer are installed as RPM packages on a Linux virtual machine hosted on Microsoft Azure. Data Collector and Transformer are available as services on the instance after the deployment is complete.
- Log in to the Microsoft Azure portal.
- In the Navigation panel, click Create a resource.
-
Search the Marketplace for StreamSets, and then select
StreamSets for Databricks. - Click Create.
-
On the page, enter a name for the new virtual machine, the user name to
log in to that virtual machine, and the authentication method to use for
logins.
Important: Do not use sdc or transformer as the user name to log in to the virtual machine. The sdc and transformer user accounts must be reserved as the system user accounts that run Data Collector and Transformer as services.
You can create the virtual machine in a new or existing resource group.
You can optionally change the virtual machine size, but the default size is sufficient in most cases. If you change the default, select a size that meets the minimum requirements.
For example, the following configuration creates a Basic A3 size virtual machine named streamsets-databricks with a user named streamsets-user who can log in using password authentication. The virtual machine is created in a new resource group named streamsets-databricks:
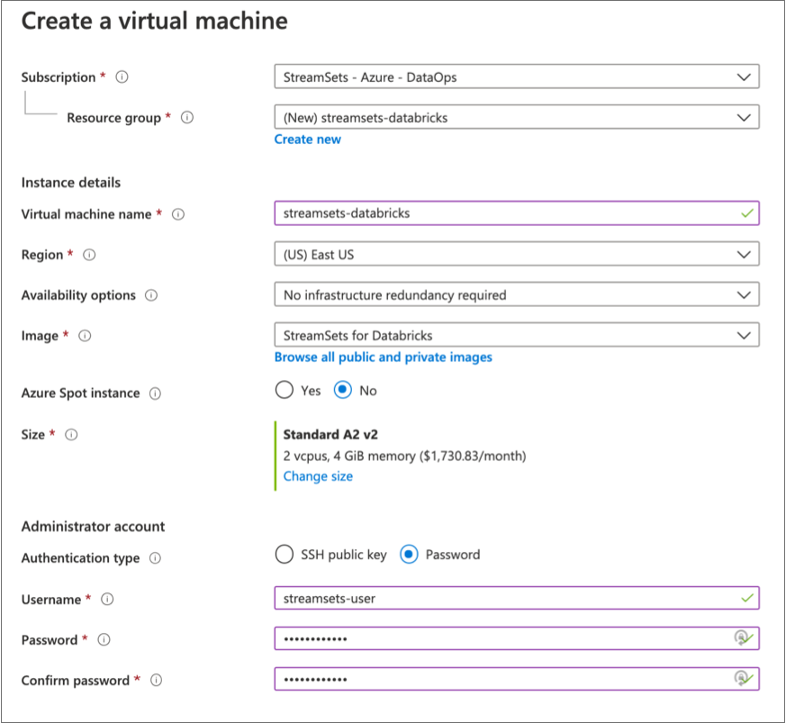
- Click Next.
- On the Disks page under Advanced, verify that Use managed disks is enabled.
- On the Networking page, select an existing group or create a new network security group for the virtual machine.
- On the remaining pages, accept the defaults or configure the optional features.
-
Verify the details in the Review and Create page, and
then click Create.
It can take several minutes for the resource to deploy and for Data Collector and Transformer to start as services.
- On the Overview page for the deployment, click the name of the network security group.
-
In the Inbound security rules section for the security
group, click the name of each of the following rules and then configure the
range of IP addresses allowed for each port.
Important: By default, the rules give all IP addresses access to Data Collector and Transformer. Be sure to modify the default values to restrict access to known IP addresses only.
Inbound Security Rule Description Data_Collector Range of IP addresses that can access the Data Collector web-based UI on port 18630. Transformer Range of IP addresses that can access the Transformer web-based UI on port 19630. default-allow-ssh Range of IP addresses that can use SSH to access the virtual machine on port 22 to run the Data Collector or Transformer command line interface. Note: If you change the default port or enable HTTPS for Data Collector or Transformer after installation, you also need to modify the appropriate rule to reflect the changed port number.
Configuring Directories (Tarball Installation)
As a best practice, after installing Transformer from a tarball, configure Transformer to use directories outside of the runtime directory after installation. This enables the use of the directories after Transformer upgrades.
Configure the directories that store files used by Transformer so they are outside of the $TRANSFORMER_DIST directory, the base Transformer runtime directory.
You can use the default locations within the $TRANSFORMER_DIST runtime directory. However, if you use the default values, make sure the user who starts Transformer has write permission on the base Transformer runtime directory.
- Create directories outside of the $TRANSFORMER_DIST runtime directory for files used by Transformer, such as configuration files, log files, and runtime resources..
-
In the $TRANSFORMER_DIST/libexec/transformer-env.sh file,
set the following environment variables to the newly created directories:
- TRANSFORMER_CONF - The Transformer configuration directory.
- TRANSFORMER_DATA - The Transformer directory for pipeline state and configuration information.
- TRANSFORMER_LOG - The Transformer directory for logs.
- TRANSFORMER_RESOURCES - The Transformer directory for runtime resource files.
- STREAMSETS_LIBRARIES_EXTRA_DIR - The Transformer directory for external files.
Modify environment variables using the method required by your installation type. - Copy all files from $TRANSFORMER_DIST/etc to the newly created $TRANSFORMER_CONF directory.
Run Transformer from Docker
- Enterprise account
- Users with an enterprise account register the Transformer image with Control Hub and use Control Hub authentication to access the Transformer image.
- IBM StreamSets
- Users without an enterprise account can create a free account with IBM StreamSets, then create a self-managed deployment and use it to manage a Transformer image.