Topologies
Section Contents
Topologies#
Topologies provide an end-to-end view of multiple, connected pipelines as data flows through them. The SDK allows you to interact with topologies including creation, modification, import/export, and deletion.
Creating a Topology#
To create a new streamsets.sdk.sch_models.Topology object, use the streamsets.sdk.sch_models.TopologyBuilder
class. Use the streamsets.sdk.ControlHub.get_topology_builder() method to instantiate the builder object:
topology_builder = sch.get_topology_builder()
After instantiating the builder, you can utilize the streamsets.sdk.sch_models.TopologyBuilder.add_job()
method to add a streamsets.sdk.sch_models.Job instance to the topology being built, which in turn creates the
representative job and system nodes for that job in the Topology. Find more information on job and system nodes in the
Control Hub topology documentation.
Note
While it is possible to a add a new system node (representing origins/destinations), the SDK does not currently support connecting new system nodes to existing nodes in a Topology. If you wish to visually represent a new flow by adding a a new system node and connecting it to existing nodes in the Topology, it is encouraged to do so through the Topology UI in Control Hub directly.
Once the desired jobs are added to the Topology, the streamsets.sdk.sch_models.TopologyBuilder.build()
method can be called with a topology_name provided. The resulting topology can then be passed to the
streamsets.sdk.ControlHub.publish_topology() method to add it to Control Hub:
# Get the jobs to be added to the topology
job1 = sch.jobs.get(job_name='job1 to add to topology')
job2 = sch.jobs.get(job_name='job2 to add to topology')
# Add the jobs to the topology via the topology_builder
topology_builder.add_job(job1)
topology_builder.add_job(job2)
# Build the topology, and then add it to Control Hub
topology = topology_builder.build(topology_name='New Test Topology')
sch.publish_topology(topology)
Output:
<streamsets.sdk.sch_api.Command object at 0x7f8f2e0579b0>
Retrieving an Existing Topology#
To retrieve existing topologies from a Control Hub instance, you can reference the streamsets.sdk.ControlHub.topologies
attribute of your streamsets.sdk.ControlHub instance:
sch.topologies
Output:
[<Topology (topology_id=ec7e5456-d935-4696-9c0f-01ea3c8e9003:admin, topology_name=test topology)>,
<Topology (topology_id=ec7e5456-d935-4696-9c0f-01ea3c8e9003:admin, topology_name=Sample Topology)>,
<Topology (topology_id=f30a63da-13e4-4dd1-b719-ec799ba598e6:admin, topology_name=topology_AAA)>]
You can also further filter and refine the topologies based on attributes like name or topology_id:
topology = sch.topologies.get(name='Sample Topology')
topology
Output:
[<Topology (topology_id=ec7e5456-d935-4696-9c0f-01ea3c8e9003:admin, topology_name=Sample Topology)>]
Modifying an Existing Topology#
You can modify existing topologies, like adding nodes to a topology or deleting nodes from a topology, directly via the SDK. The steps for modifying a topology are similar to the steps for creating a brand new one, except that an existing topology is imported rather than starting from scratch.
First, retrieve the streamsets.sdk.sch_models.Topology instance to be modified from Control Hub. Then,
instantiate a streamsets.sdk.sch_models.TopologyBuilder object and pass the topology you retrieved to the
streamsets.sdk.sch_models.TopologyBuilder.import_topology() method:
topology = sch.topologies.get(topology_name='Topology A')
topology_builder = sch.get_topology_builder()
topology_builder.import_topology(topology)
Once the topology has been imported into the builder, you can add or delete nodes as required.
Adding a Node to a Topology#
To add a job node to a streamsets.sdk.sch_models.Topology instance after importing it into a
streamsets.sdk.sch_models.TopologyBuilder object, simply retrieve the streamsets.sdk.sch_models.Job
instance to be added to the topology and pass it to the streamsets.sdk.sch_models.TopologyBuilder.add_job()
method:
job = sch.jobs.get(job_name='Job for new pipeline')
topology_builder.add_job(job)
You can then build the updated topology via the streamsets.sdk.sch_models.TopologyBuilder.build() method and
pass it into the streamsets.sdk.ControlHub.publish_topology() method:
updated_topology = topology_builder.build()
sch.publish_topology(updated_topology)
Output:
<streamsets.sdk.sch_api.Command object at 0x7f7e6c070240>
Deleting a Node From a Topology#
In order to facilitate the removal of nodes from a Topology, the streamsets.sdk.sch_models.TopologyBuilder
class keeps a list of all available streamsets.sdk.sch_models.TopologyNode instances within the
streamsets.sdk.sch_models.TopologyBuilder.topology_nodes attribute.
To delete an existing node from a streamsets.sdk.sch_models.Topology instance after importing it into a
streamsets.sdk.sch_models.TopologyBuilder object, retrieve the streamsets.sdk.sch_models.TopologyNode
instance to be deleted from the Topology. Then, pass the node into the streamsets.sdk.sch_models.TopologyBuilder.delete_node()
method:
# Show the initial TopologyNode instances contained within this topology_builder
topology_builder.topology_nodes
node_to_delete = topology_builder.topology_nodes.get(name='Job for Pipeline A')
topology_builder.delete_node(node_to_delete)
# Show the TopologyNode instances after one has been deleted
topology_builder.topology_nodes
Output:
# topology_builder.topology_nodes before deletion
[<TopologyNode (name=Dev Data Generator 1, node_type=SYSTEM)>, <TopologyNode (name=Job for Pipeline A, node_type=JOB)>,
<TopologyNode (name=Trash 1, node_type=SYSTEM)>, <TopologyNode (name=Syslog 1, node_type=SYSTEM)>,
<TopologyNode (name=Local FS 1, node_type=SYSTEM)>, <TopologyNode (name=Error -Discard, node_type=SYSTEM)>]
# topology_builder.topology_nodes after deletion
[<TopologyNode (name=Dev Data Generator 1, node_type=SYSTEM)>, <TopologyNode (name=Trash 1, node_type=SYSTEM)>,
<TopologyNode (name=Syslog 1, node_type=SYSTEM)>, <TopologyNode (name=Local FS 1, node_type=SYSTEM)>,
<TopologyNode (name=Error -Discard, node_type=SYSTEM)>]
You can then build the updated topology via the streamsets.sdk.sch_models.TopologyBuilder.build() method and
pass it into the streamsets.sdk.ControlHub.publish_topology() method:
updated_topology = topology_builder.build()
sch.publish_topology(updated_topology)
Output:
<streamsets.sdk.sch_api.Command object at 0x7fd08adf9648>
Tip
Rather than finding each System node connected to a Job and removing them from the topology one by one, you can remove just the Job node itself then build and publish the pipeline. Once published, you can utilize the Topology’s auto_discover_connections() method which will automatically remove any System nodes not associated with a Job in the Topology, as well as restore any System nodes that are associated with a Job but are missing from the Topology.
Deleting a Topology#
The SDK also allows for deletion of existing topologies from Control Hub. Since topologies are versioned, you can delete all versions of a topology or just a specific version of a topology.
To delete all versions of a topology, retrieve the streamsets.sdk.sch_models.Topology object that you wish
to delete and pass it to the streamsets.sdk.ControlHub.delete_topology() method:
topology = sch.topologies.get(name='Sample Topology')
sch.delete_topology(topology)
Output:
<streamsets.sdk.sch_api.Command object at 0x7f5bdc905f28>
To delete only the latest version of a topology, you can specify the only_selected_version parameter and set it to
True:
topology = sch.topologies.get(name='Sample Topology')
# Show the current version of this topology, and then delete only that version
topology.version
sch.delete_topology(topology, only_selected_version=True)
Output:
# topology.version
'15'
# sch.delete_topology(topology, only_selected_version=True)
<streamsets.sdk.sch_api.Command object at 0x7f5be522dcc0>
Stopping or Starting the Jobs in a Topology#
The jobs within a given topology can also be started and stopped directly from the SDK. Utilize the
streamsets.sdk.sch_models.Topology.start_all_jobs() and streamsets.sdk.sch_models.Topology.stop_all_jobs()
methods to start and stop jobs respectively:
topology = sch.topologies.get(topology_name='Topology A')
topology.start_all_jobs()
topology.stop_all_jobs()
Output:
# topology.start_all_jobs()
<streamsets.sdk.sch_api.Command object at 0x7fc475b7ab38>
# topology.stop_all_jobs()
<streamsets.sdk.sch_api.Command object at 0x7fc475c453c8>
Updating Jobs in a Topology#
The streamsets.sdk.sch_models.Job instances in Control Hub frequently have their pipelines updated and new
pipeline versions published, driving the need to update the jobs themselves.
The SDK allows you to check for newer versions of the pipelines used by the streamsets.sdk.sch_models.Job
instances in a streamsets.sdk.sch_models.Topology, and provides a method for updating jobs to the latest
pipeline version - all from within the streamsets.sdk.sch_models.Topology instance itself! This allows you
to update only the jobs within a particular topology, without having to search for which jobs are part of the topology
and update them on your own.
Note
This scenario does not apply if a job has already been updated to utilize a newer version of its pipeline, thus creating a new version of the job. Please refer to the section on Fixing and Maintaining a Topology for steps on fixing a topology when a new version is published for one of the jobs it contains.
To verify whether or not any streamsets.sdk.sch_models.Job instance has a newer pipeline version within a
topology (indicating that the job can be updated to use the newer pipeline version) you can reference the
streamsets.sdk.sch_models.Topology.new_pipeline_version_available attribute:
topology = sch.topologies.get(topology_name='new pipeline versions')
topology.new_pipeline_version_available
Output:
True
Note
This attribute is purely informational for the benefit of the user. You can blindly call the streamsets.sdk.sch_models.Topology.update_jobs_to_latest_change()
method, discussed below, without having to first check the streamsets.sdk.sch_models.Topology.new_pipeline_version_available
attribute - the method will verify that there is a new pipeline version to update the job(s) to before attempting it,
and will simply exit if no new pipeline versions are found.
If there is a new pipeline version available for any of the jobs within a topology, utilize the
streamsets.sdk.sch_models.Topology.update_jobs_to_latest_change() method to update those jobs in place. This
method will:
Update any
streamsets.sdk.sch_models.Jobinstances to the latest versions of their pipeline.Publish the updated job to Control Hub.
Create a draft version of the
streamsets.sdk.sch_models.Topologywith the updated job definition.Update the topology definition on Control Hub with the new draft of the topology.
Since the updated topology definition is still a draft, the streamsets.sdk.ControlHub.publish_topology()
method will need to be used to publish the topology:
# Create a new draft of the topology, update any jobs in the topology that have newer pipeline versions, and
# push the draft version of the topology to Control Hub
topology.update_jobs_to_latest_change()
# The topology is still a draft, and thus needs to be published
sch.publish_topology(topology)
Output:
# topology.update_jobs_to_latest_change()
<streamsets.sdk.sch_api.Command object at 0x7f12290a79e8>
# sch.publish_topology(topology)
<streamsets.sdk.sch_api.Command object at 0x7f8f2e0579b0>
Fixing and Maintaining a Topology#
A topology can encounter issues that prevent it from being used appropriately, such as job instances being permanently deleted or a topology not yet being updated with newer versions of its jobs that have been published. These issues can result in an invalid topology, outdated versions of jobs being executed, or even jobs failing to start because they’ve been removed.
To help with fixing and maintaining issues with streamsets.sdk.sch_models.Topology instances, the SDK makes
two methods available: streamsets.sdk.sch_models.Topology.auto_fix() and streamsets.sdk.sch_models.Topology.auto_discover_connections().
Auto-fixing a Topology#
To determine whether or not a streamsets.sdk.sch_models.Topology instance is in an erroneous state, you can
reference the validation_issues attribute for the instance. This will validate the topology in question, and
determine whether or not any issues are detected - such as an out of date job, or a job that’s been removed from Control
Hub but is still referenced in the topology.
If any validation issues are found, it will return the JSON representation of each issue for the topology:
topology = sch.topologies.get(topology_name='Topology with issues')
topology.validation_issues
Output:
# One of the jobs in the topology was updated, but the topology is still using the old version.
[{'code': 'TOPOLOGY_08', 'message': "Job 'Job for Pipeline A' has been updated to a different pipeline version,
so the topology is no longer valid. Would you like to automatically fix this by updating the topology to use the
new version of the job?", 'additionalInfo': {'jobId': '04a89487-f224-4b10-afa9-9b483108da8b:admin',
'pipelineCommitId': 'cf2a5aa1-78fb-4ba2-b6c9-45814b560e10:admin'}}]
Note
This attribute is purely informational for the benefit of the user. You can blindly call the streamsets.sdk.sch_models.Topology.auto_fix()
method, discussed below, without having to first check the streamsets.sdk.sch_models.Topology.validation_issues
attribute - the method will verify whether or not any validation issues exist prior to taking any corrective action.
Use the streamsets.sdk.sch_models.Topology.auto_fix() method to automatically correct the topology. If the
topology has a job node that has a newer version published, the streamsets.sdk.sch_models.Topology.auto_fix()
method will update the job node to the latest version. Likewise if the topology is still referencing a job that
has been removed from Control Hub, the streamsets.sdk.sch_models.Topology.auto_fix() method will remove that
job definition entirely.
The streamsets.sdk.sch_models.Topology.auto_fix() method will also handle creation of a new topology draft with
the corrected streamsets.sdk.sch_models.Topology definition, and will update it on Control Hub. Since the
updated topology definition is still a draft, the streamsets.sdk.ControlHub.publish_topology() method will need
to be used to publish the topology:
topology.auto_fix()
sch.publish_topology(topology)
Output:
# topology.auto_fix()
<streamsets.sdk.sch_api.Command object at 0x7faa6cb416a0>
# sch.publish_topology(topology)
<streamsets.sdk.sch_api.Command object at 0x7faa6cb41668>
Tip
Use the streamsets.sdk.sch_models.Topology.auto_fix() method to correct job version issues and remove deleted
jobs from the topology. To fix job and system node connections, including restoring deleted nodes, use the
auto_discover_connections() method.
Auto-discovering Connections in a Topology#
Auto-discovery of connections in a topology will retrieve any missing nodes in a topology and replace them (like a system node that was accidentally removed), and will likewise remove any nodes that don’t belong in the topology (like a standalone system node that’s not associated with any job in the topology).
Note
The SDK currently only supports the ‘default’ option for the streamsets.sdk.sch_models.Topology.auto_discover_connections()
method. The default option will treat each job in a topology as a standalone entity, and will not connect any common
system nodes between jobs.
You can call the streamsets.sdk.sch_models.Topology.auto_discover_connections() method on any published
streamsets.sdk.sch_models.Topology instance regardless of the current state of the nodes. The method will
only take action if it determines there are missing nodes that need to be replaced, or extra nodes that aren’t
associated with any job in the topology.
The streamsets.sdk.sch_models.Topology.auto_discover_connections() method will also handle creation of a new
topology draft with the corrected streamsets.sdk.sch_models.Topology definition, and will update it on
Control Hub. Since the updated topology definition is still a draft, the streamsets.sdk.ControlHub.publish_topology()
method will need to be used to publish the topology.
To help visualize the changes made by the streamsets.sdk.sch_models.Topology.auto_discover_connections()
method, assume the topology being operated on is the one below:
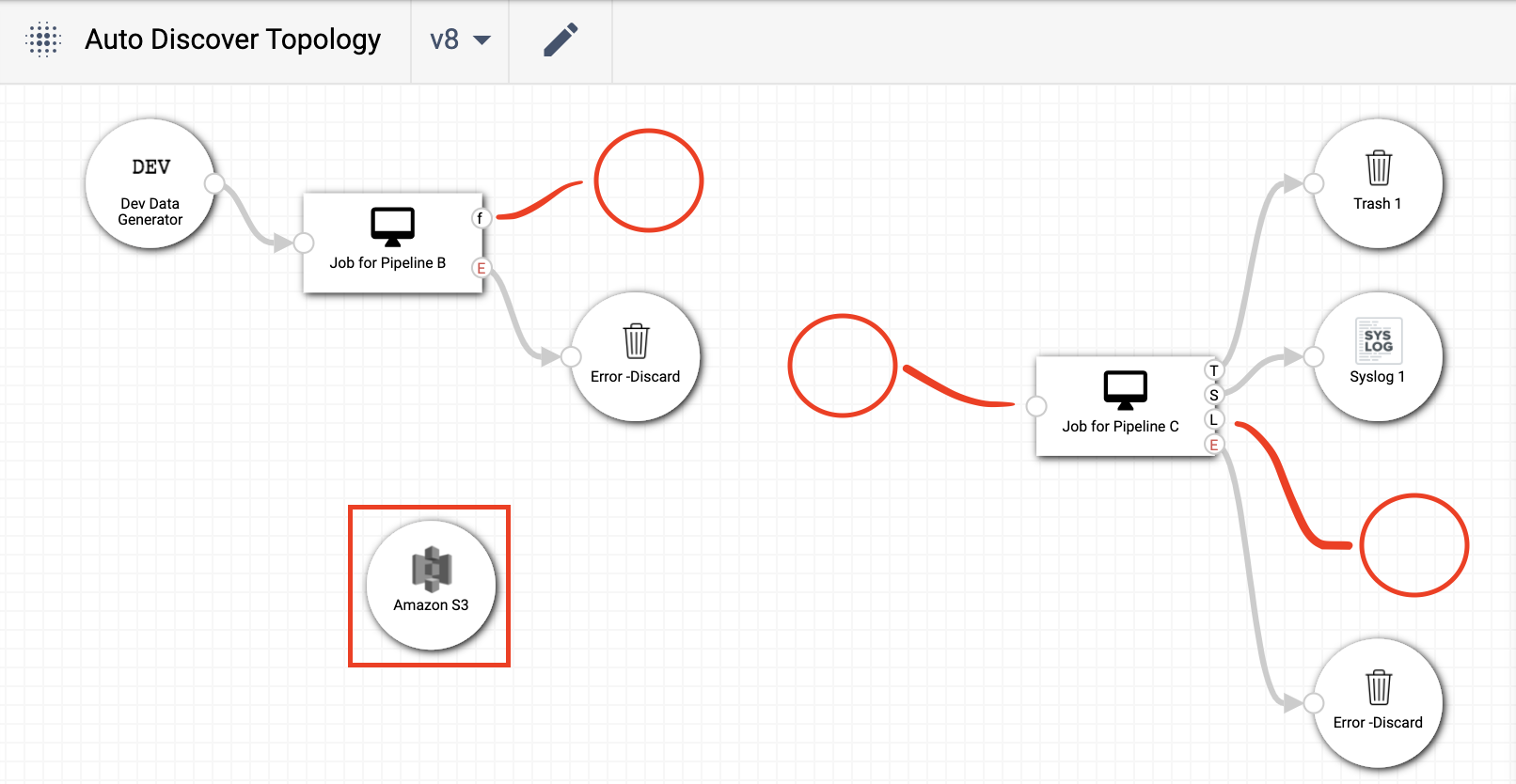
As can be seen by the red markings, this topology is missing two destination nodes, an origin node, and has an extra ‘Amazon S3’ node that’s not associated with either of the two jobs in the topology. To fix the layout, the steps mentioned above can be used:
# Get the topology from Control Hub
topology = sch.topologies.get(topology_name='Sample Topology')
# Call auto_discover_connections() for this topology, and then publish the changes
topology.auto_discover_connections()
sch.publish_topology(topology)
Output:
# topology.auto_discover_connections()
<streamsets.sdk.sch_api.Command object at 0x7fd08ae8f278>
# sch.publish_topology(topology)
<streamsets.sdk.sch_api.Command object at 0x7fd08acd9631>
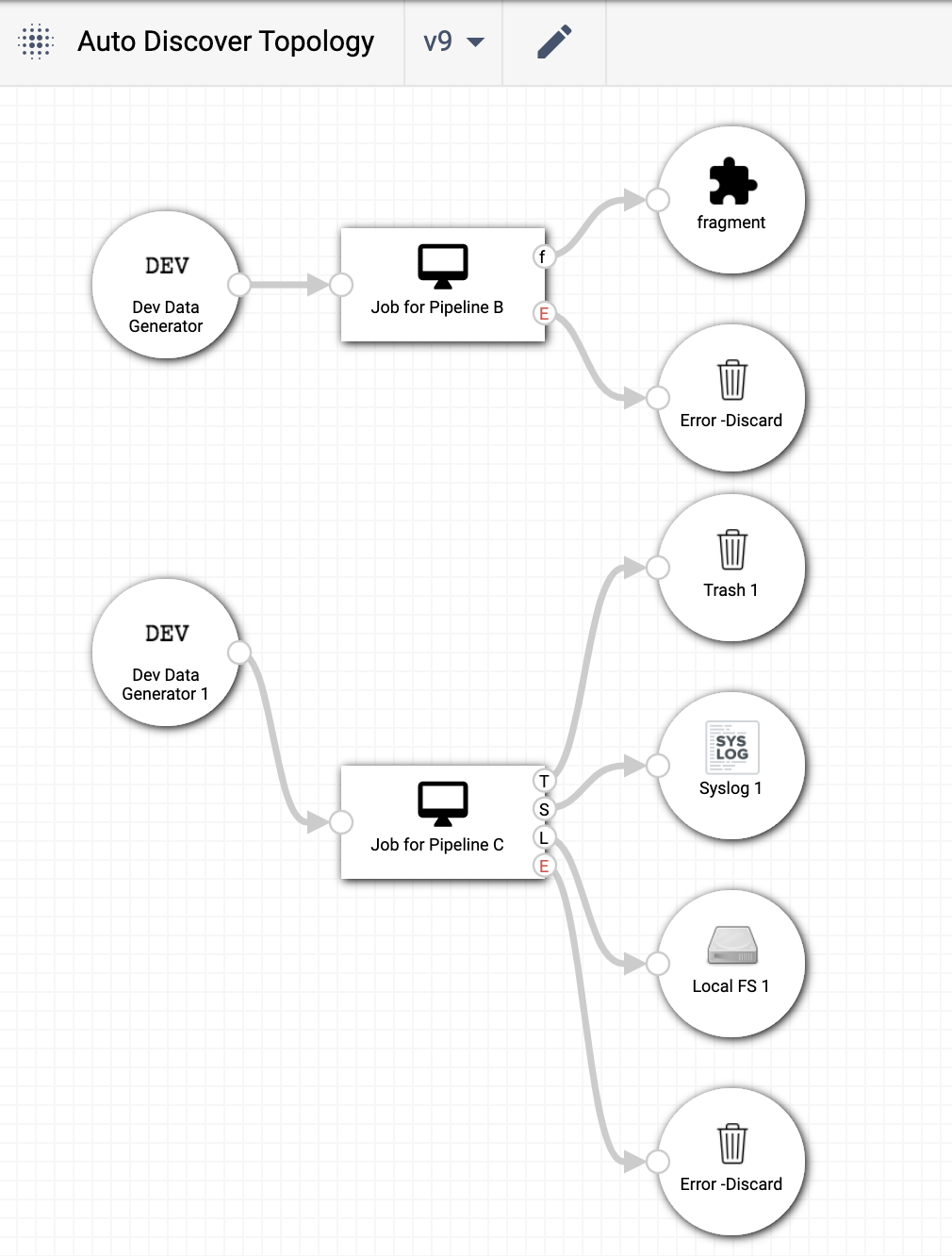
After calling the streamsets.sdk.sch_models.Topology.auto_discover_connections() method and publishing the
topology via streamsets.sdk.ControlHub.publish_topology(), the topology has the missing nodes restored, the
extra ‘Amazon S3’ node removed, and the version of the topology has been incremented:
Importing Topologies#
To import a topology, or set of topologies, from a compressed archive, you can use the
streamsets.sdk.ControlHub.import_topologies() method:
# Open the .zip archive for reading, then import the topologies
with open('topologies.zip', 'rb') as topologies_file:
topologies = sch.import_topologies(archive=topologies_file)
Exporting Topologies#
Similar to importing topologies, you can export a topology, or set of topologies, from Control Hub by using the
streamsets.sdk.ControlHub.export_topologies() method:
# Export all topologies from Control Hub
topologies_zip_data = sch.export_topologies(topologies=sch.topologies)
# Open a .zip archive for writing, and write the topologies out to a file
with open('./sch_topologies_export.zip', 'wb') as output_file:
output_file.write(topologies_zip_data)
Data SLAs in a Topology#
Data SLAs define the data processing rates that jobs within a topology must meet. The SDK enables you to add, delete, activate and deactivate data SLAs for a given topology.
You can find more information on Data SLAs in the Control Hub documentation.
Retrieving Data SLAs#
To retrieve a data SLA for a specific topology, first retrieve the streamsets.sdk.sch_models.Topology
object, and then reference its data_slas attribute:
topology = sch.topologies.get(topology_name='Sample Topology')
topology.data_slas
Output:
[<DataSLA (label='Sample Data SLA', last_modified_on=1607558436834, status='INACTIVE')>]
Adding Data SLAs#
The SDK also allows you to add a new data SLA to a job within an existing topology. Retrieve the
streamsets.sdk.sch_models.Topology object that has the job you wish to set a data SLA for, and then retrieve
the streamsets.sdk.sch_models.Job instance:
topology = sch.topologies.get(topology_name='Sample Topology')
job = topology.jobs.get(job_id='Example Job in Sample Topology')
Next, instantiate a streamsets.sdk.sch_models.DataSlaBuilder object and pass in the streamsets.sdk.sch_models.Job
and streamsets.sdk.sch_models.Topology instances as well as the required label and alert_text to the
streamsets.sdk.sch_models.DataSlaBuilder.build() method.
The streamsets.sdk.sch_models.DataSlaBuilder.build() method
also allows you to optionally specify the Quality of Service parameter to track for the SLA (qos_parameter), the
value of the expected threshold (min_max_value), whether the SLA should be measuring a maximum or minimum for
that value (function_type), and whether or not the SLA should be enabled upon creation (enabled). Refer to the
API reference on this method for details on the arguments this method takes, and their default values.
To build an SLA that would monitor the records per second throughput rate of the job above and generate an alert if processing dropped below 1000 records per second, the following parameters would be used:
data_sla_builder = sch.get_data_sla_builder()
# The default values qos_parameter=THROUGHPUT_RATE and enabled=True will be used
data_sla = data_sla_builder.build(topology=topology,
label='Sample Data SLA',
job=job,
alert_text='Sample Alert',
function_type='Min',
min_max_value='1000')
Finally, pass the built SLA to the streamsets.sdk.sch_models.Topology.add_data_sla() method to
add it to the topology:
topology.add_data_sla(data_sla)
Activating Data SLAs#
Once a data SLA has been created, you can activate it to enable monitoring on the job it belongs to. To activate data
SLAs from the SDK, simply retrieve the SLA you wish to activate and pass it to the streamsets.sdk.sch_models.Topology.activate_data_sla()
method. You can activate a single SLA, or multiple SLAs at once:
data_sla1 = topology.data_slas.get(label='Sample Data SLA')
data_sla2 = topology.data_slas.get(label='Another Sample Data SLA')
data_sla3 = topology.data_slas.get(label='A Third Sample Data SLA')
topology.activate_data_sla(data_sla1, data_sla2, data_sla3)
Output:
<streamsets.sdk.sch_api.Command at 0x10b3e8a90>
Deactivating Data SLAs#
Deactivating a data SLA is identical to activation. Simply retrieve the SLA you wish to deactivate and pass it to the
streamsets.sdk.sch_models.Topology.deactivate_data_sla() method. You can deactivate a single SLA, or multiple
SLAs at once:
data_sla1 = topology.data_slas.get(label='Sample Data SLA')
data_sla2 = topology.data_slas.get(label='Another Sample Data SLA')
topology.deactivate_data_sla(data_sla1, data_sla2)
Output:
<streamsets.sdk.sch_api.Command at 0x10b3e8a90>
Deleting Data SLAs#
Deleting a data SLA is similar to the other operations mentioned above. Simply retrieve the SLA you wish to delete, and
pass it to the streamsets.sdk.sch_models.Topology.delete_data_sla() method. You can delete a single SLA, or
multiple SLAs at once:
data_sla1 = topology.data_slas.get(label='Sample Data SLA')
data_sla3 = topology.data_slas.get(label='A Third Sample Data SLA')
topology.delete_data_sla(data_sla1, data_sla3)
Output:
<streamsets.sdk.sch_api.Command at 0x10b3e8a90>