Azure Synapse SQL
The Azure Synapse SQL destination loads data into one or more tables in Microsoft Azure Synapse. For information about supported versions, see Supported Systems and Versions.
To load data, the destination first stages the pipeline data in CSV files in a staging area, either Azure Blob Storage or Azure Data Lake Storage Gen2. Then, the destination loads the staged data into Azure Synapse.
The following image displays the steps that the destination completes to load the data:
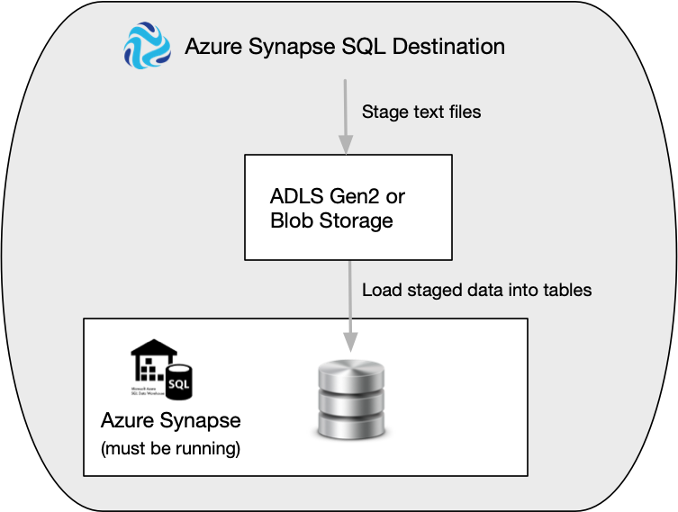
When you configure the Azure Synapse SQL destination, you specify the instance type to connect to. You configure authentication information for the instance and for your Azure staging area.
You can use the Azure Synapse SQL destination to write new data or change data capture (CDC) data to Azure Synapse. When processing new data, the destination loads data to Azure Synapse using the COPY command. When processing CDC data, the destination uses the MERGE command. When using the COPY load method, you can also specify copy statement authentication details for bulk loading to Azure Synapse.
You specify the name of the schema and tables to load the data into. The destination writes data from record fields to table columns based on matching names.
You can configure the destination to compensate for data drift by creating new columns in existing database tables when new fields appear in records or by creating new database tables as needed. When creating new tables, you can specify a partition column and partition boundary values to use.
You can configure the root field for the row, and any first-level fields that you want to exclude from the record. You can specify characters to represent null values.
You can configure the destination to replace missing fields or fields with invalid data types with user-defined default values. You can also configure the destination to replace newline characters and trim leading and trailing spaces.
Before you use the Azure Synapse SQL destination, you must complete some prerequisite tasks.
Prerequisites
Prepare the Azure Synapse Instance
Before configuring the destination, prepare your Azure Synapse instance.
- If necessary, create a database in Azure Synapse.
- If necessary, create a schema within the database.
You can use the default schema named
dboor any other user-defined schema. - If necessary, create tables within the schema.
If the tables defined in the destination do not exist, the destination can create new tables in the schema. You can configure the destination to load data into existing tables only, as described in Specifying Tables.
- Set up a user that can connect to Azure Synapse using SQL Login or Azure Active
Directory password authentication.
For more information about these authentication methods, see the Azure documentation.
- Grant the user the required permissions, based on whether you are loading new or
changed data:
- When using the COPY command to load new data, grant the following
permissions:
- INSERT
- ADMINISTER DATABASE BULK OPERATIONS
- When using the MERGE command to load changed data, grant the following
permissions:
- INSERT
- UPDATE
- DELETE
For either load method, if you want the destination to handle data drift automatically, grant the user the additional permission:- ALTER TABLE
For either load method, if you want the destination to create tables automatically while handling data drift, grant the user the additional permission:- CREATE TABLE
- When using the COPY command to load new data, grant the following
permissions:
Prepare the Azure Storage Staging Area
Before configuring the destination, prepare a staging area in Azure Blob Storage or Azure Data Lake Storage Gen2. The destination stages CSV files in the staging area before loading them to Azure Synapse.
- If necessary, create an Azure storage account in Azure Blob Storage or Azure Data
Lake Storage Gen2.
For information about creating an account, see the Azure documentation.
- If necessary, create a container to act as the staging area for the destination.
Azure Data Lake Storage Gen2 refers to storage as either a file system or container.
For information about creating storage, see the Azure documentation.
- If you plan to use Azure Active Directory with Service Principal authentication to
connect to the staging area, complete the following steps. If you plan to use
Storage Account Key authentication to connect to the staging area, you can skip
these steps:
- If necessary, create a new Azure Active Directory application for Data Collector.
If the storage account already has an existing Azure Active Directory application, you can use the existing application for Data Collector.
For information about creating a new application, see the Azure documentation.
- Grant the application the Storage Blob Data Contributor or Storage Blob Data
Owner role.
For information about configuring access control, see the Azure documentation.
- If necessary, create a new Azure Active Directory application for Data Collector.
Enable Access to the Container
The Azure Synapse SQL destination loads files from the staging area to Azure Synapse.
- Staging connection
- By default, the destination uses the authentication defined in the staging
connection to access the container and perform the load. The
access required for the connection depends on the authentication method that
you use:
- Azure Active Directory with Service Principal - The minimum required RBAC roles are Storage Blob Data Contributor, Storage Blob Data Owner, or Storage Blob Data Reader.
- Storage Account Key - No permissions are required.
- Copy statement connection
- When using the COPY load method and you enable the use of a copy
statement connection, the destination uses the authentication
defined in the copy statement connection to connect to the container and
issue the COPY command. The access required for the connection depends on
the authentication method that you use:
- Azure Active Directory User - The minimum required RBAC roles are Storage Blob Data Contributor or Storage Blob Data Owner for the storage account.
- Azure Active Directory with Service Principal - The minimum required RBAC roles are Storage Blob Data Contributor, Storage Blob Data Owner, or Storage Blob Data Reader.
- Managed Identity - The minimum required RBAC roles are Storage Blob Data Contributor or Storage Blob Data Owner for the AAD-registered SQL database server.
- Shared Access Signature (SAS) - The minimum required permissions are Read and List.
- Storage Account Key - No permissions are required.
Load Methods
The Azure Synapse SQL destination can load data to Azure Synapse using the following methods:
- COPY command for new data
- The COPY command, the default load method, performs a bulk synchronous load from the staging area to Azure Synapse, treating all records as INSERTS. Use this method to write new data to Azure Synapse tables.
- MERGE command for CDC data
- Like the COPY command, the MERGE command performs a bulk synchronous load from the staging area to Azure Synapse. But instead of treating all records as INSERT, it inserts, updates, upserts, and deletes records as appropriate. Use this method to write change data capture (CDC) data to Azure Synapse tables using CRUD operations.
Connections and Authentication
- Azure Synapse - Determines how the destination connects to Azure Synapse.
- Staging - Determines how the destination connects to the staging area.
- Copy Statement - Optional authentication when using the COPY load method to bulk load data from the staging area to Azure Synapse. When not defined, the destination uses the authentication defined for the staging connection.
Azure Synapse Connection
The Azure Synapse SQL destination requires connection details to connect to your Azure Synapse instance.
On the Azure Synapse SQL tab, you specify the name of the Azure Synapse server and the database to connect to.
- SQL Login
- The destination connects to Azure Synapse using a user name and password created in the database.
- Azure Active Directory
- The destination connects to Azure Synapse using an Azure Active Directory
user identity and password. The user identity and
password are the credentials used to sign in to the Azure
portal. Enter the full user identity, for example:
user@mycompany.com.
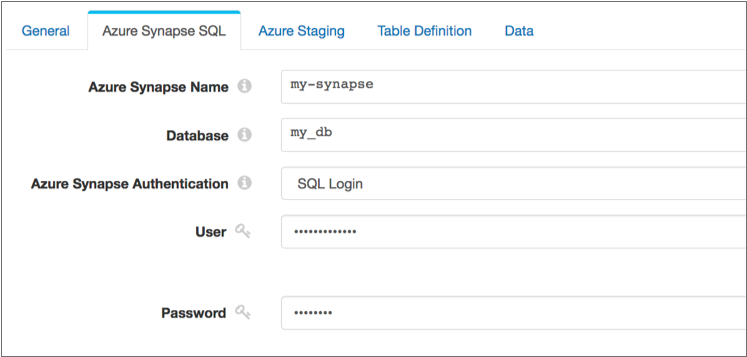
The following image displays a destination configured to connect to the
my_db database in the my-synapse server using the
SQL Login authentication method:
Staging Connection
The Azure Synapse SQL destination requires connection details to connect to the storage account that stages pipeline data. You can use Azure Blob Storage or Azure Data Lake Gen2 as the staging area.
On the Azure Staging tab, you specify the name of the storage account and the name of the container or file system to use.
- Azure Active Directory with Service Principal
- The destination connects to the staging area using the following
information:
- Application ID - Application ID for the Azure Active Directory Data Collector
application. Also known as the client ID.
For information on accessing the application ID from the Azure portal, see the Azure documentation.
- Tenant ID - Tenant ID for the Azure Active Directory Data Collector application.
- Application Key - Authentication key or client secret
for the Azure Active Directory application. Also known as the
client secret.
For information on accessing the application key from the Azure portal, see the Azure documentation.
- Application ID - Application ID for the Azure Active Directory Data Collector
application. Also known as the client ID.
- Storage Account Key
- The destination connects to the staging area using the following
information:
- Storage Account Key - Shared access key that Azure
generated for the storage account.
For more information on accessing the shared access key from the Azure portal, see the Azure documentation.
- Storage Account Key - Shared access key that Azure
generated for the storage account.
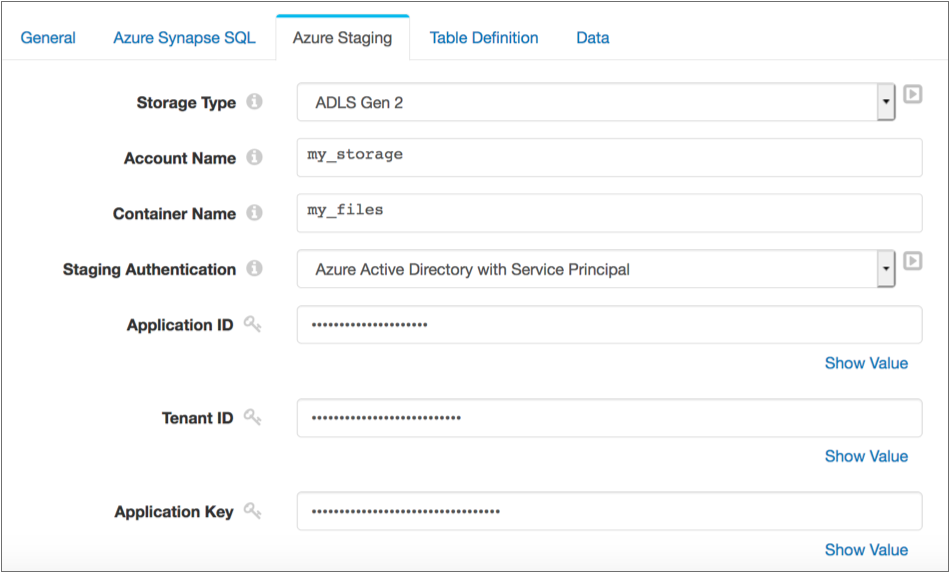
The following image displays as destination configured to connect to the
my_files file system in the my_storage Azure Data
Lake Storage Gen2 storage account using the Azure Active Directory with Service
Principal authentication method:
Copy Statement Connection
When using the COPY load method, the Azure Synapse SQL destination creates a connection to issue a COPY command that reads from the staging area and bulk loads the data into Azure Synapse.
The destination uses the connection information specified for the Azure Synapse and staging connections for the copy statement connection. That is, the copy statement connection uses configuration details for the Azure Synapse server and database that you define for the Azure Synapse connection. The copy statement connection also uses configuration details for the staging storage account and container that you define for the staging connection.
By default, the copy statement connection also uses the staging authentication method and configuration details that you define for the staging connection. When needed, you can specify authentication details specifically for the copy statement connection, instead of reusing the staging authentication details.
On the Azure Staging tab, you can enable the use of copy statement authentication and specify the authentication method and details to use.
- Azure Active Directory User
- Can be used only when the Azure Synapse connection uses Azure Active Directory authentication.
- Azure Active Directory with Service Principal
- The destination connects from Azure Synapse to the staging area using the
following information:
- Application ID - Application ID for the Azure Active Directory Data Collector
application. Also known as the client ID.
For information on accessing the application ID from the Azure portal, see the Azure documentation.
- Tenant ID - Tenant ID for the Azure Active Directory Data Collector application.
- Application Key - Authentication key or client secret
for the Azure Active Directory application. Also known as the
client secret.
For information on accessing the application key from the Azure portal, see the Azure documentation.
- Application ID - Application ID for the Azure Active Directory Data Collector
application. Also known as the client ID.
- Managed Identity
- The destination connects from Azure Synapse to the staging area using a managed identity. You can use this authentication method when your storage account is attached to a VNet.
- Shared Access Signature (SAS)
- The destination connects from Azure Synapse to the staging area using an SAS
token. The SAS token must be configured to allow all permissions and the
HTTPS protocol.
You can create the SAS token using the Azure portal by selecting Shared Access Signature from Settings in the storage account menu. Or you can create the SAS token using the Azure CLI as described in the Azure documentation.
Copy and save the generated token so that you can use it to configure the destination.
The minimum required permissions are Read and List.
- The destination connects from Azure Synapse to the staging area using the
following information:
- Account Shared Key -
The following image displays a destination configured to use the Managed Identity authentication method for copy statement authentication:
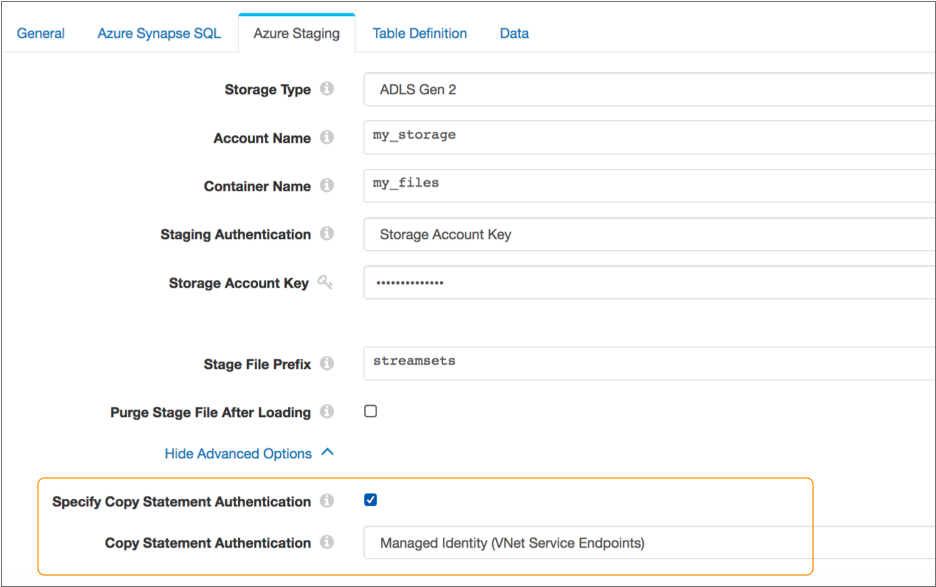
The destination also uses a staging connection that connects to the
my_files file system in the my_storage Azure Data
Lake Storage Gen2 storage account using Storage Account Key authentication. If you did
not configure copy statement authentication, the destination would use the specified
storage account key for copy statement authentication.
Specifying Tables
You can use the Azure Synapse SQL destination to write to one or more tables in a schema. The Azure Synapse SQL destination can load data into a single existing schema.
- Single table
- To write data to a single table, simply enter table name as
follows:
<table_name> - Multiple tables
- To write data to multiple tables, specify a field in the record that defines the tables.
Use the Table property on the Table Definition tab to specify the tables to write to.
Enabling Data Drift Handling
The Azure Synapse SQL destination can automatically compensate for changes in column or table requirements, also known as data drift.
- Create new columns
- The destination can create new columns in existing tables when new fields
appear in records. For example, if a record suddenly includes a new
Address2field, the destination creates a newAddress2column in the target table. - Create new tables
- When data drift handling is enabled, you can also configure the destination
to create new tables as needed. For example, say the destination writes data
to tables based on the region name in the
Regionfield. When a newSW-3region shows up in a record, the destination creates a newSW-3table and writes the record to the new table.
Row Generation
When loading a record to a table, the Azure Synapse SQL destination includes all
record fields in the resulting row, by default. The destination uses the root field,
/, as the basis for the resulting row.
You can configure the Row Field property on the Data tab to specify a map or list-map field in the record as the basis for the row. The resulting record includes only the data from the specified map or list-map field and excludes all other record data. Use this functionality when the data that you want to load to Azure Synapse exists in a single map or list-map field within the record.
If you want to use the root field, but do not want to include all fields in the resulting row, you can configure the destination to ignore all specified first-level fields.
/, as the basis for the resulting row. A record contains the
following
fields:{
"name": "Jane Smith",
"id": "557",
"address": {
"street": "101 3rd St",
"city": "Huntsville",
"state": "NC",
"zipcode": "27023"
}
}The destination treats the address map field as a field with an invalid
data type, ignoring the field by default and processing the remaining record data. You
can configure the destination to treat fields with invalid data types as an error
record, as described in Missing Fields and Fields with Invalid Types.
Missing Fields and Fields with Invalid Types
By default, the destination ignores missing fields or fields with invalid data types, replacing the data in the field with a null value.
The default for each data type is an empty string, which represents a null value in Azure
Synapse. You can specify a different default value to use for each data type on the Data
tab. For example, you might define the default value for a missing Varchar field or a
Varchar field with an invalid data type as none or
not_applicable.
You can configure the destination to treat records with missing fields or with invalid data types in fields as error records. To do so, clear the Ignore Missing Fields and the Ignore Fields with Invalid Types properties on the Data tab.
Performance Optimization
Use the following tips to optimize for performance and cost-effectiveness when using the Azure Synapse SQL destination:
- Increase the batch size
- The maximum batch size is determined by the origin in the pipeline and typically has a default value of 1,000 records. To take advantage of the loading abilities that Azure Synapse provides, increase the maximum batch size in the pipeline origin to 20,000-50,000 records. Be sure to increase the Data Collector java heap size, as needed.
- Use multiple threads
- You can use multiple threads to improve performance when you include a multithreaded origin in the pipeline. When Data Collector resources allow, using multiple threads enables processing multiple batches of data concurrently.
- Enable additional connections to Azure Synapse
- When loading data into multiple tables, increase the number of connections that the destination makes to Azure Synapse. Each additional connection allows the destination to load data into an additional table, concurrently.
Azure Synapse Data Types
The Azure Synapse SQL destination converts Data Collector data types into Azure Synapse data types before loading data into Azure.
When you configure the destination to compensate for data drift, you can also configure the destination to create all new columns as Varchar. However, by default, the destination converts record data to the appropriate data type.
| Data Collector Data Type | Azure Synapse Data Type |
|---|---|
| Boolean | Bigint, Bit, Char, Decimal, Float, Int, Nchar, Numeric, Nvarchar,
Real, Smallint, Tinyint, or Varchar. New columns are created as Bit. |
| Byte | Bigint, Char, Decimal, Float, Int, Nchar, Numeric, Nvarchar,
Real, Smallint, Tinyint, or Varchar. New columns are created as Smallint. |
| Byte_Array | Binary, Char, Nchar, Nvarchar, Varbinary, or Varchar. New columns are created as Binary. |
| Date | Char, Date, Nchar, Nvarchar, or Varchar. New columns are created as Date. |
| Datetime | Char, Date, Datetime, Datetime2, Nchar, Nvarchar, Smalldatetime,
Time, or Varchar. New columns are created as Datetime. |
| Decimal | Char, Decimal, Money, Nchar, Numeric, Nvarchar, Smallmoney, or
Varchar. New columns are created as Numeric. |
| Double | Char, Decimal, Float, Money, Nchar, Numeric, Nvarchar,
Smallmoney, or Varchar. New columns are created as Float. |
| Float | Char, Decimal, Float, Money, Nchar, Numeric, Nvarchar, Real,
Smallmoney, or Varchar. Note: Converting to Decimal or Numeric can
result in some precision loss. New columns are created as Real. |
| Integer | Bigint, Char, Decimal, Float, Int, Money, Nchar, Numeric,
Nvarchar, Real, Smallmoney, or Varchar. New columns are created as Int. |
| Long | Bigint, Char, Decimal, Float, Money, Nchar, Numeric, Nvarchar,
Smallmoney, or Varchar. New columns are created as Bigint. |
| Short | Bigint, Char, Decimal, Float, Int, Money, Nchar, Numeric,
Nvarchar, Real, Smallint, Smallmoney, Tinyint, or Varchar. New columns are created as Smallint. |
| String | Char, Datetimeoffset, Nchar, Nvarchar, or Varchar. New columns are created as Varchar. |
| Time | Char, Nchar, Nvarchar, Time, or Varchar. New columns are created as Time. |
| Zoned_Datetime | Char, Nchar, Nvarchar, or Varchar. |
- Geography
- Geometry
CRUD Operation Processing
The Azure Synapse SQL destination can insert, update, upsert, or delete data when you configure the destination to process CDC data. When processing CDC data, the destination uses the MERGE command to write data to Azure Synapse.
sdc.operation.type record header attribute. The destination
performs operations based on the following numeric values:- 1 for INSERT
- 2 for DELETE
- 3 for UPDATE
- 4 for UPSERT
If
your pipeline has a CRUD-enabled origin that processes
changed data, the destination simply reads the operation
type from the sdc.operation.type header
attribute that the origin generates. If your pipeline has
a non-CDC origin, you can use the Expression Evaluator
processor or a scripting processor to define the record
header attribute. For more information about Data Collector changed data processing and a list of CDC-enabled
origins, see Processing Changed Data.
Configuring an Azure Synapse SQL Destination
Configure an Azure Synapse SQL destination to load data into Azure Synapse. Be sure to complete the necessary prerequisites before you configure the destination.
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
-
On the Azure Synapse SQL tab, configure the following
properties used to connect to Azure
Synapse:
Azure Synapse Property Description Azure Synapse Name Name of the Azure Synapse server. The server name is the first portion of the FQDN.
For example, in the
my_synapse.database.windows.netFQDN, the server name ismy_synapse.Azure Synapse Instance Type Azure Synapse Instance type to write to: - SQL Pool (database.windows.net) - Use to write to an Azure Synapse dedicated SQL pool.
- Managed SQL (sql.azuresynapse.net) - Use to write to an Azure SQL Managed Instance.
Database Name of the database within Azure Synapse. Azure Synapse Authentication Authentication method used to connect to Azure Synapse: - Azure Active Directory Authentication
- SQL Login
User User name for the connection to the database. Available when using the SQL Login authentication method.
Password Password for the account. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores.Available when using the SQL Login authentication method.
Azure Active Directory ID Azure Active Directory user identity for the connection to the database. The user identity and password are the credentials used to sign in to the Azure portal. Enter the full user identity, for example:
user@mycompany.com.Available when using the Azure Active Directory authentication method.
Password Password for the user identity. Tip: To secure sensitive information such as user names and passwords, you can use runtime resources or credential stores.Available when using the Azure Active Directory authentication method.Azure Government Account Enables the use of an Azure Government account. For more information about government accounts, see the Azure documentation.
Connection Pool Size Maximum number of connections that the destination uses to load data into Azure Synapse. Default is 0, which ensures that the destination uses the same number of connections as threads used by the pipeline. When loading to multiple tables, increasing this property can improve performance.
-
On the Azure Staging tab, configure the following
properties used to connect to the
staging area to stage the data:
Azure Staging Property Description Storage Type Location of the storage area: - Blob Storage - Azure Blob Storage
- ADLS Gen1 - Azure Data Lake Storage Gen2
Account Name Name of the storage account. Container Name Name of the container or file system in the storage account where the destination stages data. Staging Authentication Authentication method used to connect to the Azure staging area: - Azure Active Directory with Service Principal
- Storage Account Key
Application ID Application ID for the Azure Active Directory Data Collector application. Also known as the client ID. For information on accessing the application ID from the Azure portal, see the Azure documentation.
Available when using the Azure Active Directory with Service Principal authentication method.
Tenant ID Tenant ID for the Azure Active Directory Data Collector application. Available when using the Azure Active Directory with Service Principal authentication method.
Application Key Authentication key or client secret for the Azure Active Directory application. Also known as the client secret. For information on accessing the application key from the Azure portal, see the Azure documentation.
Available when using the Azure Active Directory with Service Principal authentication method.
Storage Account Key Shared access key that Azure generated for the storage account. For more information on accessing the shared access key from the Azure portal, see the Azure documentation.
Available when using the Storage Account Key authentication method.
Stage File Prefix Prefix to use for the name of the staged files. To create a unique name for each staged file, the destination appends a unique number to the prefix. For example, if you define the prefix as
streamsets, the destination might name one of the staged filesstreamsets-69021a22-1474-4926-856f-eb4589d14cca.Purge Stage File After Loading Purges a staged file after its data is successfully loaded into Azure Synapse. Specify Copy Statement Authentication Enables configuring an authentication method for the COPY command that bulk loads data from the staging area to Azure Synapse. When not configured, the destination uses staging authentication details for the connection.
Copy Statement Authentication Authentication method used with the COPY command that bulk loads data from the staging area to Azure Synapse: - Azure Active Directory User - Can be used only when the Azure Synapse connection uses Azure Active Directory authentication.
- Azure Active Directory with Service Principal
- Managed Identity
- Shared Access Signature (SAS)
- Storage Account Key
Application ID Application ID for the Azure Active Directory Data Collector application. Also known as the client ID. For information on accessing the application ID from the Azure portal, see the Azure documentation.
Available when using the Azure Active Directory with Service Principal authentication method.
Tenant ID Tenant ID for the Azure Active Directory Data Collector application.
Available when using the Azure Active Directory with Service Principal authentication method.
Application Key Authentication key or client secret for the Azure Active Directory application. Also known as the client secret. For information on accessing the application key from the Azure portal, see the Azure documentation.
Available when using the Azure Active Directory with Service Principal authentication method.
Storage Account Key Shared access key that Azure generated for the storage account. For more information on accessing the shared access key from the Azure portal, see the Azure documentation.
Available when using the Storage Account Key authentication method.
SAS Token Shared access signature (SAS) token created for the storage account. Available when using the Shared Access Signature authentication method.
-
On the Table Definition tab, configure the following
properties:
Table Definition Property Description Schema Name of the database schema to use. Default is dbo.
Table Tables to load data into. To load data into a single table, enter the table name.
To load data into multiple tables, enter an expression that evaluates to the field in the record that contains the table name.
For example:
${record:value('/table')}Or, to load data into tables based on the table name in the
jdbc.tablesrecord header attribute generated by an origin that reads from a relational database, you can use the following expression:${record:attribute('jdbc.tables')}The destination writes data from record fields to table columns based on matching names.
Enable Data Drift Creates new columns in existing tables when new fields appear in records. When not enabled, the destination treats records that have new fields as error records.
Create New Columns as Varchar Creates all new columns as Varchar. By default, the destination infers the data type based on the type of data in the field. For example, if a new field contains an integer, the destination creates a column with the Int data type.
Available when data drift handling is enabled.
Propagate Numeric Precision and Scale Creates new numeric columns with the precision and scale specified in JDBC record header attributes. When not enabled or when JDBC header attributes are not available, the destination creates numeric columns with the default precision of 38 and scale of 0.
Available when data drift handling is enabled.
Auto Create Table Automatically creates tables when needed. When not enabled, the destination treats a record attempting to load to a table that doesn't exist as an error record.
Available when data drift handling is enabled.
Case Insensitive Ignores case differences in table and schema names. For example, when selected, the destination matches a table named
customerwith a table namedCustomer. When cleared, the destination fails to match a table namedcustomerwith a table namedCustomer.By default, Azure Synapse is case insensitive. In most cases, you should leave this property selected.
Partition Table Partitions automatically created tables. Available when data drift handling and automatically creating tables are both enabled.
Partition Column Column name to partition by. Available when partitioning is enabled.
Partition Boundary Determines the boundary that you define with the specified partition values, as well as the partition that the values are included in: - Lower Boundary - Partition values are used as the lower boundary of the partition. The values are included in the partition to the right.
- Upper Boundary - Partition values are used as the upper boundary of the partition. The values are included in the partition to the left.
Available when partitioning is enabled.
Partition Values Values to use as partition boundaries. Available when partitioning is enabled.
-
On the Data tab, configure the following
properties:
Data Property Description Row Field Map or list_map field to use as the basis for the generated row. Default is /, which includes all record fields in the resulting row.Column Fields to Ignore List of fields to ignore when loading into Azure Synapse. You can enter a comma-separated list of first level fields to ignore. Merge CDC Data Uses the MERGE command to perform CRUD operations when writing to Azure Synapse tables. Select to process CDC data. Important: To maintain the original order of data, do not use multiple threads when processing CDC data.For more information about the MERGE command, see Load Methods. For information about optimizing pipeline performance, see Performance Optimization.
Key Columns Key columns in each Azure Synapse table used to evaluate the MERGE condition. Click the Add icon to add additional tables. Click the Add Another in the Key Columns field to add additional key columns for a table.
Null Value Characters to use to represent null values. Ignore Missing Fields Allows loading records with missing fields to tables. Uses the specified default value for the data type of the missing field. When not enabled, records with missing fields are treated as error records.
Ignore Fields with Invalid Types Allows replacing fields that contain data of an invalid type with the specified default value for the data type. When not enabled, records with data of invalid types are treated as error records.
Bit Default Default value to use when replacing missing Bit fields or Bit fields with invalid data. Default is an empty string, which represents a null value in Azure Synapse.
Numeric Default Default value to use when replacing missing fields or fields with invalid data that use one of the numeric data types. Numeric data types include Decimal, Numeric, Float, Real, Int, Bigint, Smallint, Tinyint, Money, and Smallmoney. Maximum size is 38 digits.
Default is an empty string, which represents a null value in Azure Synapse.
Date Default Default value to use when replacing missing Date fields or Date fields with invalid data. Use the following format:
yyyy-mm-dd. For example:2019-10-05.Default is an empty string, which represents a null value in Azure Synapse.
Time Default Default value to use when replacing missing Time fields or Time fields with invalid data. Use the following format:
hh:mm.ss.fffffff. For example:05:48:10.7490000.Default is an empty string, which represents a null value in Azure Synapse.
Datetime Default Default value to use when replacing missing Datetime fields or Datetime fields with invalid data. Use the following format:
yyyy-mm-dd hh:mm:ss.fff. For example:2019-10-05 05:48:10.749.Default is an empty string, which represents a null value in Azure Synapse.
Varchar Default Default value to use when replacing missing Varchar fields or Varchar fields with invalid data. Maximum size is 8,000 characters.
Default is an empty string, which represents a null value in Azure Synapse.
Binary Default Default value to use when replacing missing Binary fields or Binary fields with invalid data. Maximum size is 500 bytes.
Default is an empty string, which represents a null value in Azure Synapse.
Replace Newlines Replaces newline characters with a specified character. Newline Replacement Character Character to replace newline characters. Trim Spaces Trims leading and trailing spaces from field data.