Custom Schemas
When reading delimited or JSON data, you can configure an origin to use a custom schema to process the data. By default, origins infer the schema from the data.
You might use a custom schema to specify data types for potentially ambiguous fields, such as BigInt for a field that might be inferred as Integer. Inferring data can require Transformer to perform a full read on the data before processing to determine the correct data type for ambiguous fields, so using a custom schema can improve performance.
You can use a custom schema to reorder fields in JSON data or to rename fields in delimited data. When processing delimited files or objects, you can use a custom schema to define field names and types when files or objects do not include a header row.
Use custom schemas with care. When the data contains fields that are not defined in the schema, the origin drops the fields from the record. When the schema contains fields that are not in the data, the origin includes the fields in the record and populates them with null values.
You can define a custom schema using the JSON or Data Definition Language (DDL) format. When you define a schema, you specify the name and data type for each field, as well as the field order. The custom schema is applied differently depending on the data format of the data.
When you define a custom schema, you also specify how the origin handles parsing errors.
Schema Application
When using a custom schema to process data, an origin applies the schema differently depending on the data format of the data:
- Delimited data
- When processing delimited data with a custom schema, the origin applies the first field name and data type in the schema to the first field in the record, and so on. Since existing field names are ignored, this enables you to rename fields while defining their data types.
- JSON data
- When processing JSON data with a custom schema, an origin locates fields in the data based on the field names defined in the schema, then applies the specified data types to those fields. The origin also reorders the fields based on the order specified in the schema.
Error Handling
When you define a custom schema, you specify how the origin handles parsing errors. Parsing errors can occur when the data in a field is not compatible with the data type specified in the schema.
- Permissive - When the origin encounters a problem
parsing any field in the record, it creates a record with the field names
defined in the schema, but with null values in every field. An origin
can optionally write the data from the original record to a specified field in
the record.
When writing the original record to a field, you must add the field to the custom schema as a String field. That is, to have the origin write the original record to a field named
originalData, include anoriginalDataString field in the custom schema. - Drop Malformed - When the origin encounters a problem parsing any field in the record, it drops the entire record from the pipeline.
- Fail Fast - When the origin encounters a problem parsing any field in the record, it stops the pipeline.
DDL Schema Format
To use DDL to define a custom schema, specify a comma-separated list of field names and data types. Here's an example of the basic structure:
<first field name> <data type>, <second field name> <data type>, <third field name> <data type><list field name> Array <subfields data type><map field name> Struct < <first subfield name>:<data type>, <second subfield name>:<data type> >`count`.Example
TransactionID String, Verified Boolean, User Struct <ID:Integer, Name:String>, Items Array <String>{"Verified":true,"User":{"ID":23005,"Name":"Marnee Gehosephat"},"Items":["T-35089", "M-00352", "Q-11044"],"TransactionID":"G-23525-3350"}The origin generates the following record:
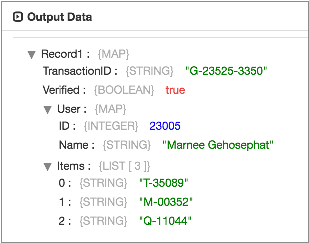
Notice the User Map field with the Integer and String subfields and
the Items List field with String subfields. Also note that the
order of the fields now match the order in the custom schema.
JSON Schema Format
To use JSON to define a custom schema, specify the field names and data types within a root field that uses the Struct data type.
nullable attribute is required for most fields.{
"type": "struct",
"fields": [
{
"name": "<first field name>",
"type": "<data type>",
"nullable": <true|false>
},
{
"name": "<second field name>",
"type": "<data type>",
"nullable": <true|false>
}
]
}{
"name": "<list field name>",
"type": {
"type": "array",
"elementType": "<subfield data type>",
"containsNull": <true|false>
}
}{
"name": "<map field name>",
"type": {
"type": "struct",
"fields": [ {
"name": "<first subfield name>",
"type": "<data type>",
"nullable": <true|false>
}, {
"name": "<second subfield name>",
"type": "<data type>",
"nullable": <true|false>
} ] },
"nullable": <true|false>
}Example
{
"type": "struct",
"fields": [
{
"name": "TransactionID",
"type": "string",
"nullable": false
},
{
"name": "Verified",
"type": "boolean",
"nullable":false
},
{
"name": "User",
"type": {
"type": "struct",
"fields": [ {
"name": "ID",
"type": "long",
"nullable": true
}, {
"name": "Name",
"type": "string",
"nullable": true
} ] },
"nullable": true
},
{
"name": "Items",
"type": {
"type": "array",
"elementType": "string",
"containsNull": true},
"nullable":true
}
]
}{"Verified":true, "Items":["T-35089", "M-00352", "Q-11044"], "TransactionID":"G-23525-3350", "User":{"ID":23005,"Name":"Marnee Gehosephat"}}The origin generates the following record:
Notice the User Map field with the Integer and String subfields and the
Items List field with String subfields. Also note that the order of the
fields now match the order in the custom schema.