Slowly Changing Dimension
The Slowly Changing Dimension processor generates updates to a Type 1 or Type 2 slowly changing dimension by evaluating change data against master dimension data. Use the processor in a pipeline to update slowly changing dimension data stored in a database table or a set of files.
The processor loads master dimension data and change data, and then compares the change data to the master data, matching records based on key fields. For each change record, the processor determines whether to update an existing master record, create a new master record, or ignore the change record as a duplicate. The processor maintains tracking fields, which track the changes in the master dimension. By default, the processor outputs only the changes and a destination updates the master dimension data with that output. Alternatively, with proper configuration, the processor outputs all the master data along with the changes and a destination overwrites the master dimension data with that output.
- Slowly changing dimension type.
- Action to take when a change record has fields that are not included in the master records.
- Key fields used to match change and master data.
- Flag to trigger the replacement of null values in change data with corresponding master data.
- Tracking fields along with the tracking type of the fields.
- Fields in a Type 2 dimension that trigger the retention of previous data.
- Flag to trigger the inclusion of all master data in the output. This enables the destination to overwrite file dimensions as needed.
When you configure a slowly changing dimension pipeline it's important to configure pipeline properties and all stage properties appropriately for your use case. For more information, see Pipeline Configuration.
Slowly Changing Dimension Pipeline
A slowly changing dimension pipeline compares change data to master dimension data, and then writes the changes to the master dimension data.
A slowly changing dimension pipeline can process a traditional table dimension, where the dimension data is stored in a database table. The pipeline can also process a file dimension, where the dimension data is stored in a set of files in a directory.
The simplest slowly changing dimension pipeline looks like this:
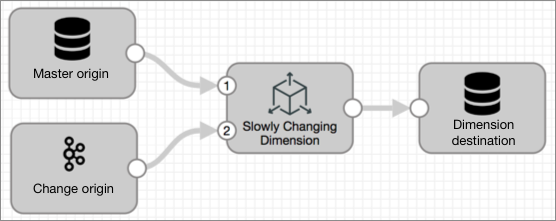
- Master origin - Reads the master dimension data. Use one of the following
origins:
- Whole Directory - Reads a file dimension. The dimension files must reside in a single directory. No non-dimension files should exist in the directory. Do not use the Whole Directory origin with a grouped file dimension.
- File - Reads a file dimension. The dimension files can reside in a directory and its subdirectories. No non-dimension files should exist in the directory or subdirectories.
- JDBC Table - Reads a table dimension.
- Change origin - Reads change data. Use any Transformer origin to read change data.
- Slowly Changing Dimension processor - Compares change data to master data and flags change records for insert or update.
- Dimension destination - Writes results to the master
dimension. Use one of the following destinations:
- ADLS Gen1 - Writes to a file dimension on Azure Data Lake Storage Gen1.
- ADLS Gen2 - Writes to a file dimension on Azure Data Lake Storage Gen2.
- Amazon S3 - Writes to a file dimension on Amazon S3.
- File - Writes to a file dimension on HDFS or a local file system.
- JDBC - Writes to a database table dimension.
Pipeline Configuration
You configure a slowly changing dimension pipeline differently, depending on whether it updates a dimension stored in a table or in files.
Table Dimension Pipeline
- Pipeline
- On the General tab of the pipeline properties panel, enable ludicrous mode to read only master data that is related to the change data, and thereby improve pipeline performance.
- Origins
- Configure the master origin, the JDBC Table origin, to read the master dimension data. Configure a change origin to read change data. Then, connect them to the Slowly Changing Dimension processor.
- Processor
- After receiving both sets of data, the Slowly Changing Dimension processor compares change records to master records, updates tracking fields, and passes records flagged for insert or update downstream.
- Destination
- Configure the JDBC destination to write to the master dimension.
File Dimension Pipeline
For a file dimension, the pipeline must overwrite dimension files because updating a record in a file is not possible. To ensure that new dimension files contain both the master data and the change data, the processor must pass the master data and the change data to the destination.
A file dimension can be organized as a grouped file dimension or an ungrouped file dimension. A grouped file dimension has a set of files grouped by field values. An ungrouped file dimension has files stored in one directory. The pipeline configuration is slightly different for grouped file dimensions and ungrouped file dimensions.
Here's how to configure a file dimension pipeline:
Pipeline
- Grouped file dimension
-
For a grouped file dimension, configure the following properties:
- Enable Spark to overwrite partitions dynamically. This
allows the destination to overwrite only the files with
changes.
For more information, see Grouped File Dimension Prerequisite.
- On the General tab of the pipeline properties panel, enable ludicrous mode to avoid reading master data that is not related to the change data, thereby improving pipeline performance.
With this configuration, if change data includes five records in two file groups, then the master origin only reads the files from those two groups. The destination overwrites the files in those two groups.
- Enable Spark to overwrite partitions dynamically. This
allows the destination to overwrite only the files with
changes.
- Ungrouped file dimension
- For an ungrouped file dimension, all dimension data must be read and written, so no special pipeline properties are required. Each time a batch of change data is read, the master origin must read the entire dimension. When writing the change, the destination must overwrite the entire dimension.
Origins
Configure the master origin to read the master dimension data. Configure a change origin to read the change data. Then, connect them to the Slowly Changing Dimension processor.
Each time the change origin reads a batch of data, the master origin must read the dimension data. This ensures that the Slowly Changing Dimension processor compares the change data to the latest dimension data.
Whether the master origin reads the entire dimension or just related master records depends on whether ludicrous mode is enabled at a pipeline level.
- Grouped file dimension
- For a grouped file dimension, use the File origin. Be sure to configure
the following properties:
- Clear the Load Data Only Once property. The origin must read the master data for each batch processed.
- Select the Skip Offset Tracking property. The origin must read all available data for each batch processed.
- In the Partition Base Path property, enter the path to the root directory of files grouped by fields. The origin must add the field and value from the group names to the data set.
- Set the Max Files Per Batch property to 0. The origin must read all the files from the master dimension in each batch.
- Ungrouped file dimension
- For an ungrouped file dimension, use either the Whole Directory origin
or the File origin.
The Whole Directory origin requires no special configuration. The origin does not cache data or track offsets, so it reads all of the master dimension data each time the change origin reads a batch of data.
The File origin requires the following property configurations:- Clear the Load Data Only Once property. The origin must read the master data for each batch processed.
- Select the Skip Offset Tracking property. The origin must read all available data for each batch processed.
- Set the Max Files Per Batch property to 0. The origin must read all the files from the master dimension in each batch.
Processor
After receiving both sets of data, the Slowly Changing Dimension processor compares change records to master records, updates tracking fields, and passes the inserted and updated change records along with the unchanged master dimension records downstream.
- Ensure that the master origin is connected to the master data input and the
change origin to the change data input for the processor.
If they are connected to the wrong locations, you can easily reverse the connections by clicking the Change Input Order link on the General tab of the processor.
- Specify the SCD Type and related properties. These properties determine the logic the processor uses to flag records for insert or update.
- List the key fields used to match change fields with master fields.Note: For grouped file dimensions, enter these key fields in the Partition by Fields property of the destination.
- For Type 2 dimensions, specify one or more tracking field names and types. For Type 1 dimensions, this is optional.
- Enable the Output Full Master Data property so the master data is passed to
the destination along with the change data.
The destination can then determine whether to write the entire master data set or a subset of the master data to the dimension.
- Optionally configure other properties, such as whether to replace null values with data from the latest master record and the action to take when change data includes additional fields.
Destination
- Grouped file dimension
-
For a grouped file dimension, configure the following properties:
- Select the Exclude Unrelated SCD Master Records property to filter out master records that are not related to the change records.
- Set the Write Mode property to Overwrite Related Partitions to overwrite only files in groups with changes.
- In the Partition by Fields property, enter the fields from the Key Fields property in the Slowly Changing Dimension processor to group files for the dimension by these fields.
With this configuration, the destination overwrites only files related to the change records, leaving files in other groups as is.
- Ungrouped file dimension
-
For an ungrouped file dimension, configure the following properties:
- Set the Write Mode property to Overwrite Files.
- Do not enable the Exclude Unrelated SCD Master Records property.
With this configuration, the destination deletes all existing master dimension files and writes a new master dimension file that contains all master data with the latest changes.
Grouped File Dimension Prerequisite
To write to a grouped file dimension, configure Spark to overwrite partitions dynamically.
Set the Spark configuration property
spark.sql.sources.partitionOverwriteMode to
dynamic.
You can configure the property in Spark, or you
can configure the property in individual pipelines. For example, you might set the
property to dynamic in Spark when you plan to enable the Overwrite
Related Partitions mode in most of your pipelines, and then set the property to
static in individual pipelines that do not use that mode.
To configure the property in an individual pipeline, add an extra Spark configuration property on the Cluster tab of the pipeline properties.
Slowly Changing Dimension Type
- Type 1
- A Type 1 dimension retains only the current version of each record. For each change record, the processor determines whether to update an existing master record, create a new master record, or ignore the change record as a duplicate. For a Type 1 dimension you can specify a date-based tracking field that stores when the record was updated or inserted.
- Type 2
- A Type 2 dimension retains historical versions of records. For each change record, the processor determines
whether to update an existing master record, create a new master record, or ignore
the change record as a duplicate.
For each change record that updates an existing record, the processor triggers a Type 2 update to retain the history of the record when the values in specific fields change. You specify the fields by configuring one of the following properties:
- Type 2 for All Changes - A change in any field triggers a Type 2 update.
- Type 2 for Specified Fields - A change in any of the specified fields triggers a Type 2 update.
- Type 2 Exceptions - A change in any field except a specified field triggers a Type 2 update.
Note: If a change record contains changes only in fields that do not trigger a Type 2 update, the processor updates the existing record with the new values but does not retain the historical values and does not update tracking fields to track when the change occurred.Type 2 dimensions require at least one tracking field. The tracking field indicates the active record among all the records with the same key field values.
Tracking Fields
In the master dimension, tracking fields indicate which record is active or the most recently updated and can indicate when an update occurred. There are four types of tracking fields. A Type 2 dimension requires at least one tracking field and supports up to four, one of each type. A Type 1 dimension supports a timestamp tracking field to indicate when the record was updated, but does not require a tracking field.
To support timestamp tracking fields, you can configure a timestamp basis field, which the processor can use to determine the timestamp to insert in a timestamp tracking field.
- Version Increment
- Integer field that indicates a
version.
Among records with the same key field values, the record with the highest value in this field is current or active.
In insert records without a matching master record, the processor sets the version increment field to 1. In insert records with a matching master record, the processor sets the version increment field to the value in the active matching master record incremented by one.
- Active Flag
- Boolean field that indicates whether the
record is the current or active version.
Among records with the same key field values, the record with a
truevalue in this field is current or active.In insert records, the processor sets the active flag field to
true. For insert records that are part of a Type 2 update, the processor also sets the active flag field tofalsein the update record created for the previously active record. - As Of/Start Timestamp
- Datetime field that indicates
the time that the record became active or current. Note: This is the only type of tracking field that a Type 1 dimension supports.
Among records with the same key field values, the record with the latest timestamp in this field is the current or active record.
In insert records, the processor sets this field to a timestamp value. The set timestamp value depends on the configuration of the Timestamp Basis property:Timestamp Basis Set Timestamp Value From Data Value of the change-record field specified in the Timestamp Basis Field property. Calculate (Now) Pipeline start time from the Transformer machine. - End Timestamp
- Datetime field that indicates the time
that use of the record stopped.
Among records with the same key field values, the record with an empty value in this field is the current or active record.
In insert records, the processor sets the end timestamp field to a null value. For insert records that are part of a Type 2 update, the processor also sets the end timestamp field in the update record created for the previously active record. The set timestamp value depends on the configuration of the Timestamp Basis property:Timestamp Basis Set Timestamp Value From Data Value of the change-record field specified in the Timestamp Basis Field property. Calculate (Now) Pipeline start time from the Transformer machine.
Multiple Tracking Fields
- Version Increment - The record with the highest value in this field is the current or active record.
- As Of / Start Timestamp - The record with the latest timestamp in this field is the current or active record.
- End Timestamp - The record with an empty value in this field is the current or active record.
- Active Flag - The record with a
truevalue in this field is the current or active record.
For example, if a dimension has Active Flag and Version Increment tracking fields, then the processor determines the current record by examining the Version Increment field. The record with the highest value is the current or active record. If a dimension has Active Flag and End Timestamp fields, then the processor determines the current record by examining the End Timestamp field. The record with an empty value in the field is the current or active record.
Timestamp Basis Field
A timestamp basis field is a field in the change record that contains the value that the processor inserts in the start or end timestamp tracking field.
- Extra field
- The timestamp basis field can exist only in the change record, not in the master dimension. In this case, the field is an extra field. After saving the value for setting timestamp tracking fields, the processor drops the timestamp basis field from the change record. Unlike other extra fields, a timestamp basis field never results in an error, regardless of the Extra Field Mode setting.
- Tracking field
- The timestamp basis field can have the same name as a tracking field in the master dimension. In this case, the processor saves the value for setting timestamp tracking fields and then ignores the value, just like other tracking fields in the change record. The processor does not use the field to evaluate change and overwrites the value in the field when setting tracking fields.
- Data field
- The timestamp basis field can match a data field in the master dimension - that is, a field other than a tracking field or a key field. The processor uses the field to evaluate change and for setting timestamp tracking fields.
Change Processing
Once the Slowly Changing Dimension processor loads the master dimension data and the change data, the processor evaluates each record in the change data and creates an output data set.
- If the change record contains extra fields, the processor either drops the fields or triggers an error that stops the pipeline, as configured in the Extra Field Mode property.
- If the change record is missing fields, the processor adds the fields and sets their values to missing.
Subsequent processing differs for a Type 1 dimension and a Type 2 dimension.
Type 1 Dimension Processing
- Searches for a matching master dimension record with identical values in the key fields.
- If no matching record is found, flags the change record for insert.
- If a matching record is found, completes the following:
- If configured to replace nulls, replaces any null values in the change record with the value from the same field in the matching master record.
- Compares the values of data fields in the change record to the data
fields in the master record.
Data fields are fields not designated as key fields or tracking fields.
- If the data fields contain no change, drops the change record, which is a duplicate of an existing record.
- If the data fields contain at least one change, flags the change record for update to replace the existing master record.
- If an As Of/Start Timestamp tracking field is configured, sets the value.
- Adds the flagged change record to the output data set.
Type 2 Dimension Processing
- Searches for a matching master dimension record with identical values in the key fields.
- If no matching record is found, flags the change record for insert.
- If the change record matches a master dimension record, completes the
following tasks:
- Finds the active record among multiple matching records by examining a tracking field.
- If configured to replace nulls, replaces any null values in the change record with values from matching fields in the active master record.
- Compares the values of data fields in the change record to the data
fields in the master record.
Data fields are those not designated as key fields or tracking fields.
- If the data fields contain no change, drops the change record, which is a duplicate of an existing record.
- If none of the data fields with changes are configured for a Type 2
update, flags the change record for update and copies the values of
the tracking fields from the master record. Note: No data fields are configured for a Type 2 update if all the data fields with changes are listed in the Type 2 Exceptions property or if none of the data fields with changes are listed in the Type 2 for Specified Fields property.
- If at least one of the data fields with changes is configured for
Type 2 update, flags the change record for insert. If the active
master record has an End Date or Active Flag tracking field, also
creates an update record for that master record. Master records that
have an End Date or Active Flag tracking field require an update for
the tracking field. Note: Data fields are configured for Type 2 update if the Type 2 for All Changes property is selected, the fields are listed in the Type 2 for Specified Fields property, or the fields are not listed in the Type 2 Exceptions property.
- Sets the tracking fields in insert records and in update records created for
Type 2 updates.
The processor does not update tracking fields in update records for non-Type 2 updates - that is, in cases where none of the data fields are configured for Type 2 update.
- Adds records flagged for insert or update to the output data set.
Processor Output
By default, the Slowly Changing Dimension processor outputs the set of records that results from change processing, the change records flagged for insert or update. Enable the Output Full Master Data property to configure the processor to also output all the master dimension data.
The processor must output all the master dimension data for the pipeline to overwrite the slowly changing dimension rather than updating affected records in the dimension. Pipelines must overwrite file dimensions because destinations cannot update single lines in files.
Pipelines can efficiently overwrite only the files with changes in grouped file dimensions. To implement such a pipeline, configure the pipeline to use ludicrous mode, configure Spark to overwrite partitions dynamically, and configure the destination to overwrite related partitions. For more information, see File Dimension Pipeline.
With the Output Full Master Data property enabled, the processor adds all of the records from the master dimension to the output data set and flags the records for pass through. When adding the records, the processor does not add the master record that corresponds to a change record flagged update.
Examples of a Slowly Changing Dimension
Suppose a town needs a dimension of its streets. The dimension must store the street name, number of lanes, and surface type. The town needs a historical record of when the number of lanes or surface type changes, but does not need a record of changes to street names. The town needs a Type 2 dimension with three tracking fields, one that flags the active record, one that stores the end date, and one that stores the effective date of the record.
| ID | Street | Lanes | Surface | Active | End_Date | Eff_Date |
|---|---|---|---|---|---|---|
| 1 | El Camino Real | 6 | Asphalt | True | 2000-01-01 | |
| 2 | Market St | 4 | Asphalt | False | 2018-06-01 | 2000-01-01 |
| 2 | Market St | 2 | Asphalt | True | 2018-06-01 |
To reduce potential errors and misunderstandings, the town wants to stop change processing if the change records contain extra fields and wants the change record to provide the effective date of records. To meet the town's requirements, you configure the Slowly Changing Dimension processor as follows:
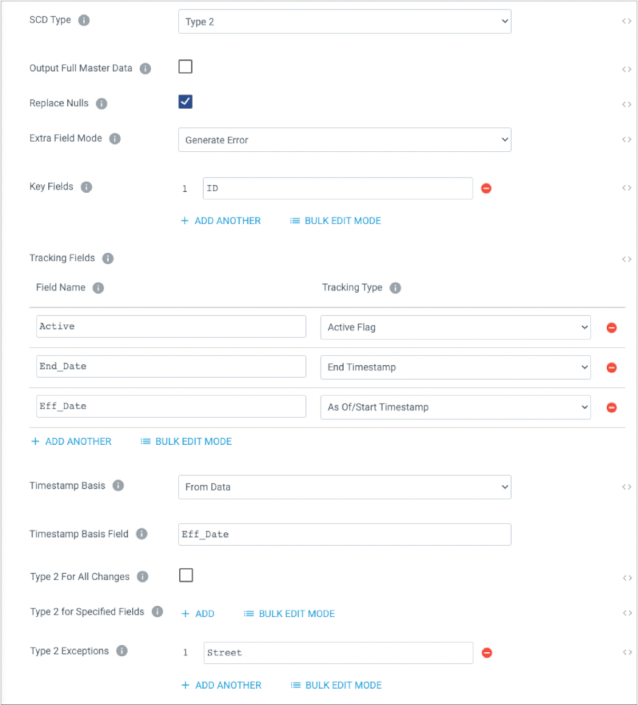
The following sections describe different change records and the resulting output from the processor.
Type 2 Update
| ID | Street | Surface | Eff_Date |
|---|---|---|---|
| 2 | Market St | Concrete | 2020-09-30 |
The processor compares the change record with the schema of the master dimension and
adds the missing fields, set to null values. The processor finds master records that
have the same ID as the change record. In this case, there are two records, the
records for Market St. The processor finds the active record by examining the As
Of/Start Date tracking field, Eff_Date, for the record with the
latest value. In this case, that is the record effective 2018-06-01. The processor
replaces null values in the change record with the values from the active record.
The processor determines that the Surface field changed. Because
changes to the Surface field trigger a Type 2 update, the processor
flags the change record for insert and sets the tracking fields. Because the record
has tracking fields for the active field and end date, the processor creates an
update record for the currently active master record, setting the tracking fields
appropriately.
| Op Type | ID | Street | Lanes | Surface | Active | End_Date | Eff_Date |
|---|---|---|---|---|---|---|---|
| Insert | 2 | Market St | 2 | Concrete | True | 2020-09-30 | |
| Update | 2 | Market St | 2 | Asphalt | False | 2020-09-30 | 2018-06-01 |
The insert record adds the change record to the master dimension. The update record updates the tracking fields in the former active record in the master dimension.
| Op Type | ID | Street | Lanes | Surface | Active | End_Date | Eff_Date |
|---|---|---|---|---|---|---|---|
| Insert | 2 | Market St | 2 | Concrete | True | 2020-09-30 | |
| Update | 2 | Market St | 2 | Asphalt | False | 2020-09-30 | 2018-06-01 |
| Pass through | 1 | El Camino Real | 6 | Asphalt | True | 2000-01-01 | |
| Pass through | 2 | Market St | 4 | Asphalt | False | 2018-06-01 | 2000-01-01 |
Note that the processor adds the records from the master dimension, flagged as pass through, except for the record that the change record updates.
Non-Type 2 Update
| ID | Street | Eff_Date |
|---|---|---|
| 1 | Royal Road | 2020-06-01 |
The processor compares the change record with the schema of the master dimension and adds the missing fields, set to null values. The processor finds master records that have the same ID as the change record. In this case, there is one record, the record for El Camino Real effective 2000-01-01. The processor replaces the null values with values from the active record.
The processor determines that the Street field changed. Because
changes to the Street field do not trigger a Type 2 update, the
processor flags the change record for update and copies the tracking fields from the
current active record. In the change record, the Eff_Date field
serves as a time basis field, which is not needed in this case. The processor does
not update any tracking fields because the change did not trigger a Type 2
update.
| Op Type | ID | Street | Lanes | Surface | Active | End_Date | Eff_Date |
|---|---|---|---|---|---|---|---|
| Update | 1 | Royal Road | 6 | Asphalt | True | 2000-01-01 |
No Update
| ID | Street | Surface | Eff_Date |
|---|---|---|---|
| 2 | Market St | Asphalt | 2020-09-30 |
The processor compares the change record with the schema of the master dimension and adds the missing fields, set to null values. The processor matches the change record with the active record for Market St, which was effective 2018-06-01. The processor replaces the null values with values from the active record, as configured.
The processor determines that no field changed. Because the Eff_Date
field is a tracking field in the master record, the processor does not consider the
field when evaluating the change record. The processor discards the change record
without adding it to the output.
Extra Fields
| ID | Street | Surface | Type | Eff_Date |
|---|---|---|---|---|
| 2 | Market St | New Asphalt | Scheduled | 2020-09-30 |
The processor compares the change record with the schema of the master dimension and
finds an extra field, Type. The processor triggers an error, as
configured by the Extra Field Mode property, and the pipeline stops.
If you had configured the Extra Field Mode property to discard extra fields, then the processor would discard the record and continue processing.
Inconsistent Data
| ID | Street | Surface | Eff_Date |
|---|---|---|---|
| 2 | Market St | Concrete | 2006-06-06 |
The processor compares the change record with the schema of the master dimension and
adds the missing fields, set to null values. The processor finds master records that
have the same ID as the change record. In this case, there are two records, the
records for Market St. The processor finds the active record by examining the As
Of/Start Date tracking field, Eff_Date, for the record with the
latest value. In this case, that is the record effective 2018-06-01. The processor
replaces null values in the change record with values from the active record.
The processor determines that the Surface field changed. Because
changes to the Surface field trigger a Type 2 update, the processor
flags the change record for insert and sets the tracking fields. Because the record
has tracking fields for the active field and end date, the processor creates an
update record for the currently active master record, setting the tracking fields
appropriately.
| Op Type | ID | Street | Lanes | Surface | Active | End_Date | Eff_Date |
|---|---|---|---|---|---|---|---|
| Insert | 2 | Market St | 2 | Concrete | True | 2006-06-06 | |
| Update | 2 | Market St | 2 | Asphalt | False | 2006-06-06 | 2018-06-01 |
Note that the Eff_Date field in the change record is the time basis
field. The processor inserts the value from that field into the
Eff_Date field of the newly current record and into the
End_Date field of the previously active record. Unfortunately,
that value is in the past and is inconsistent with the existing data in the master
dimension. As a result, the end date is now before the effective date in the
previous active record. The processor does not check for such inconsistencies.
Configuring a Slowly Changing Dimension Processor
Configure a Slowly Changing Dimension processor as part of a slowly changing dimension pipeline that updates a slowly changing dimension.
Before configuring a slowly changing dimension pipeline, consider the processing that you want to achieve. When writing to a grouped file dimension, complete the Spark prerequisite.
For information about configuring a slowly changing dimension pipeline, see Pipeline Configuration.
-
On the General tab, configure the following
properties:
General Property Description Name Stage name. Description Optional description. Input Streams Displays the master data and change data input streams, as well as the names of the origins connected to the streams. To reverse the origins connected to each stream, click Change Input Order.
-
On the Dimensions tab, configure the following
properties:
Dimension Property Description SCD Type Slowly changing dimension type: - Type 1 - The dimension contains active records and no historical records.
- Type 2 - The dimension contains active records and earlier versions of those records for historical reference.
Output Full Master Data Includes all existing master data in the output. Use this option when writing to a slowly changing dimension that must be overwritten instead of updated, such as a file dimension, to ensure that the master dimension data is written along with the latest changes. Replace Nulls Replaces null or missing values in a change record with the values from the corresponding active master record. If not enabled and a field with a value in the active master record matches a field with a null value in the change record, the processor updates the master record with the null value from the change record.
Extra Field Mode Action taken when a change record includes fields that do not exist in the schema of the master dimension: - Drop - Drops extra fields from the record.
- Error - Generates an error, which stops the
pipeline.Note: The processor never generates an error for a timestamp basis field not found in the master dimension. The processor always drops those fields after storing the value for use in processing.
Key Fields One or more nontracking fields that identify a unique record in the master dimension. In a Type 2 dimension, multiple records can have the same values of key fields but with unique tracking field values. The processor matches change records with master dimension records by finding records with the same values in the key fields.
Tracking Fields Master dimension fields that provide information about when a record is active. Type 1 dimensions support use of an As Of/Start Timestamp tracking field to indicate the update timestamp. In a Type 1 dimension, this field is optional.
Type 2 dimensions require at least one tracking field to determine the active record.
To configure additional fields, click the Add icon.
Field Names Name of the tracking field. Tracking Type Tracking type to use for the field: - Version Increment - Integer field that indicates a version.
- Active Flag - Boolean field that indicates whether the record is the current or active version.
- As of/Start Timestamp - Datetime field that indicates the time that the record became active or current.
- End Timestamp - Datetime field that indicates the time that use of the record stopped.
Timestamp Basis Method for determining the value to insert in the start and end timestamp tracking fields: - Calculate (Now) - Insert the pipeline start time from the Transformer machine.
- From Data - Insert the timestamp from a specified field in the change record.
Timestamp Basis Field Field in the change record that contains the value to insert in the start and end timestamp tracking fields. Important: You must ensure that the timestamp basis field contains the correct values to insert. The Slowly Changing Dimension processor does not check for data consistency.Type 2 for All Changes Triggers a Type 2 update when any field has a changed value. Clear to specify a subset of fields to trigger a Type 2 update.
Type 2 for Specified Fields Fields that trigger a Type 2 update. If a change record contains a changed value in any of the listed fields, the processor triggers a Type 2 update for the record. Cannot be used with the Type 2 Exceptions property.
Type 2 Exceptions Fields that do not trigger a Type 2 update. If a change record contains changes only in the values of listed fields, the processor does not trigger a Type 2 update for the record. Cannot be used with the Type 2 for Specified Fields property.