PySpark
The PySpark processor transforms data based on custom PySpark code. You develop the custom code using the Python API for Spark, or PySpark. The PySpark processor supports Python 3.
You can use the PySpark processor in pipelines that provision a Databricks cluster, in standalone pipelines, and in pipelines that run on any existing cluster except for Dataproc. Do not use the processor in Dataproc pipelines or in pipelines that provision non-Databricks clusters.
Prerequisites
Complete all prerequisite tasks before using the PySpark processor in pipelines that run on existing clusters or in standalone pipelines.
When using the processor in pipelines that provision a Databricks cluster, you must perform the required tasks.
Provisioned Databricks Cluster Requirements
When you use the PySpark processor in a pipeline that provisions a Databricks cluster, you must include several environment variables in the pipeline properties.
On the Cluster tab of the pipeline properties, add the following Spark environment variables to the cluster details configured in the Cluster Configuration property:
"spark_env_vars": {
"PYTHONPATH": "/databricks/spark/python/lib/py4j-<version>-src.zip:/databricks/spark/python:/databricks/spark/bin/pyspark",
"PYSPARK_PYTHON": "/databricks/python3/bin/python3",
"PYSPARK_DRIVER_PYTHON": "/databricks/python3/bin/python3"
} Note that the PYTHONPATH variable requires the py4j version used by the cluster.
For example, the following cluster configuration provisions a Databricks cluster that uses py4j version 0.10.7 to run a pipeline with a PySpark processor:
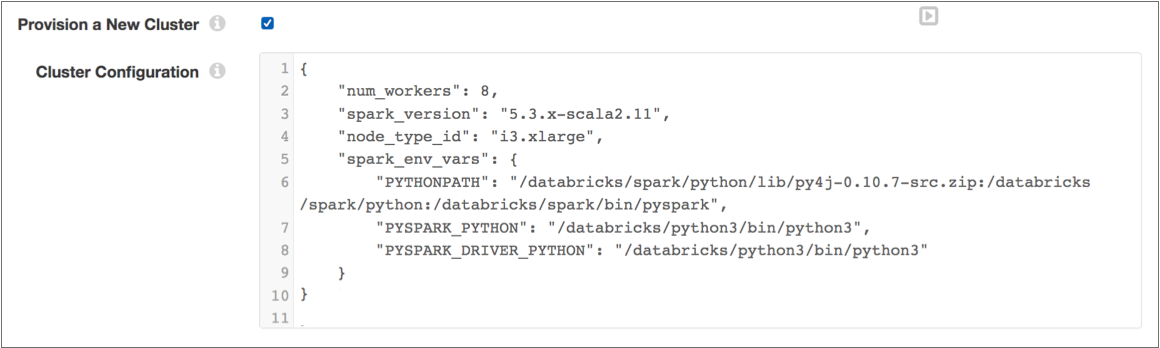
For more information about provisioning a Databricks cluster, see Provisioned Cluster.
Develop the PySpark Code
When you develop custom code for the PySpark processor, you can include any valid code available with PySpark, as described in the Spark Python API documentation.
The PySpark processor receives one or more Spark DataFrames as input. Your custom code calls PySpark operations to transform the DataFrames. The custom code must produce a single DataFrame as output.
In the custom code, use the inputs and output variables
to interact with DataFrames. Reference fields in the DataFrames using the notation
required by Spark.
Input and Output Variables
- inputs
- Use the
inputsvariable to access input DataFrames. - output
- Use the
outputvariable to pass the transformed DataFrame downstream.
Referencing Fields
To reference specific DataFrame fields in the custom code, use dot notation (.) after
the inputs variable and then use the field reference notation required by
Spark.
ID field in the input DataFrame,
use:inputs[0].IDzip_code field nested in the
address map field in the input DataFrame,
use:inputs[0].address.zip_codeorder_item list field in the input
DataFrame, use:inputs[0].order_item[2]For more details, see Referencing Fields.
Examples
Here are a few simple examples of custom PySpark code developed for the PySpark processor.
Compute Summary Statistics of a DataFrame
Let's say that
your pipeline processes order data. You want to use the PySpark
describe operation to calculate basic summary statistics
including the mean, standard deviation, count, min, and max for all numeric and
string columns.
output = inputs[0].describe()Combine Data in Two DataFrames
Let's say that your pipeline processes employee data from two separate databases. The
employee data sets contain the same number of columns with the same data types. You
want to use the PySpark union operation to combine data from both
DataFrames into a single DataFrame.
output = inputs[0].union(inputs[1])Configuring a PySpark Processor
Configure a PySpark processor to transform data based on custom PySpark code. You can use the PySpark processor in pipelines that provision a Databricks cluster, in standalone pipelines, and in pipelines that run on any existing cluster except for Dataproc. Do not use the processor in Dataproc pipelines or in pipelines that provision non-Databricks clusters.
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Cache Data Caches data processed for a batch so the data can be reused for multiple downstream stages. Use to improve performance when the stage passes data to multiple stages. Caching can limit pushdown optimization when the pipeline runs in ludicrous mode.
-
On the PySpark tab, enter the PySpark code to
run.
Ensure that the custom PySpark code is valid before using it in the processor. When you validate a pipeline, Transformer does not validate the PySpark code.