Offloading Data from Relational Sources to Hadoop
This solution describes how to offload data from relational database tables to Hadoop.
Let's say that you want to batch-load data from a set of database tables to Hive, basically replacing an old Apache Sqoop implementation. Before processing new data, you want to delete the previous tables. And you'd like to create a notification file when the pipeline stops to trigger subsequent actions from other applications, like a _SUCCESS file to launch a MapReduce job.
- Batch processing
-
To perform batch processing, where the pipeline stops automatically after all processing is complete, you use an origin that creates the no-more-data event, and you pass that event to the Pipeline Finisher executor. We'll step through this quickly, but for a solution centered on the Pipeline Finisher, see Stopping a Pipeline After Processing All Available Data.
To process database data, we can use the JDBC Multitable Consumer - it generates the no-more-data event and can spawn multiple threads for greater throughput. For a list of origins that generate the no-more-data event, see Related Event Generating Stages in the Pipeline Finisher documentation.
- Remove existing data before processing new data
- To perform tasks before the pipeline starts processing data, use the pipeline start event. So, for example, if you wanted to run a shell command to perform a set of tasks before the processing begins, you could use the Shell executor.
- Create a notification file when the pipeline stops
- Use the pipeline stop event to perform tasks after all processing completes, before the pipeline comes to a full stop. To create an empty success file, we'll use the HDFS File Metadata executor.
- First create the pipeline that you want to use.
We use the JDBC Multitable Consumer in the following simple pipeline, but your pipeline can be as complex as needed.

- To set up batch processing, enable event generation in the origin by selecting
the Produce Events property on the
General tab. Then, connect the event output stream to
the Pipeline Finisher executor.
Now, when the origin completes processing all data, it passes a no-more-data event to the Pipeline Finisher. And after all pipeline tasks are complete, the executor stops the pipeline.
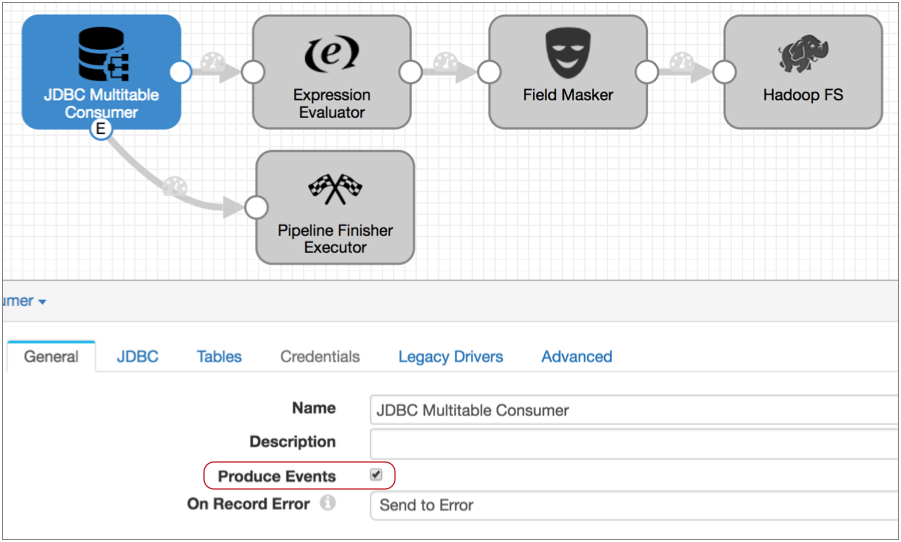 Note: The JDBC Multitable Consumer origin generates only the no-more-data event, so you don't need to use a Stream Selector or executor precondition to manage other event types. But if the origin you want to use generates additional event types, you should ensure that only the no-more-data event is routed to the Pipeline Finisher. For details, see the Stop the Pipeline solution.
Note: The JDBC Multitable Consumer origin generates only the no-more-data event, so you don't need to use a Stream Selector or executor precondition to manage other event types. But if the origin you want to use generates additional event types, you should ensure that only the no-more-data event is routed to the Pipeline Finisher. For details, see the Stop the Pipeline solution. - To truncate Hive tables before processing begins, configure the pipeline to pass
the pipeline start event to the Hive Query executor.
To do this, on the General tab, you configure the Start Event property, selecting the Hive Query executor as follows:
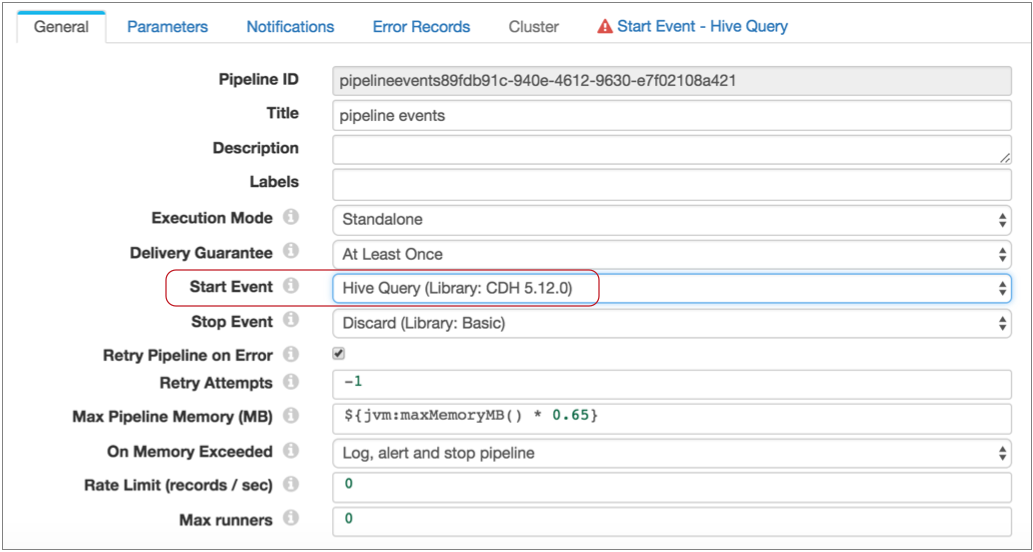
Notice, a Start Event - Hive Query tab now displays. This is because the executors for pipeline start and stop events do not display in the pipeline canvas - you configure the selected executor as part of the pipeline properties.
Also note that you can pass each type of pipeline event to one executor or to another pipeline for more complex processing. For more information about pipeline events, see Pipeline Event Generation.
- To configure the executor, click the Start Event - Hive
Query tab.
You configure the connection properties as needed, then specify the query to use. In this case, you can use the following query, filling in the table name:
TRUNCATE TABLE IF EXISTS <table name>Also, select Stop on Query Failure. This ensures that the pipeline stops and avoids performing any processing when the executor cannot complete the truncate query. The properties should look like this:
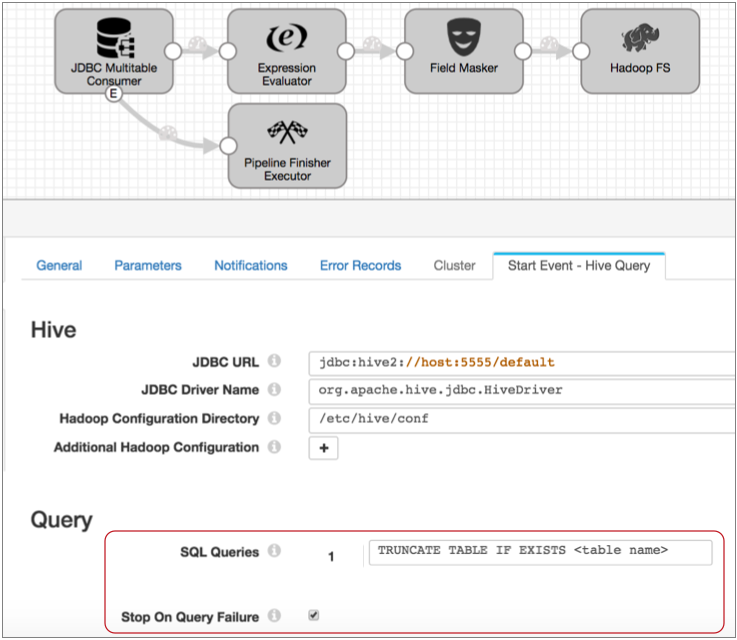
With this configuration, when you start the pipeline, the Hive Query executor truncates the specified table before data processing begins. And when the truncate completes successfully, the pipeline begins processing.
- Now, to generate a success file after all processing is complete, you perform
similar steps with the Stop Event property.
Configure the pipeline to pass the pipeline stop event to the HDFS File Metadata executor as follows:
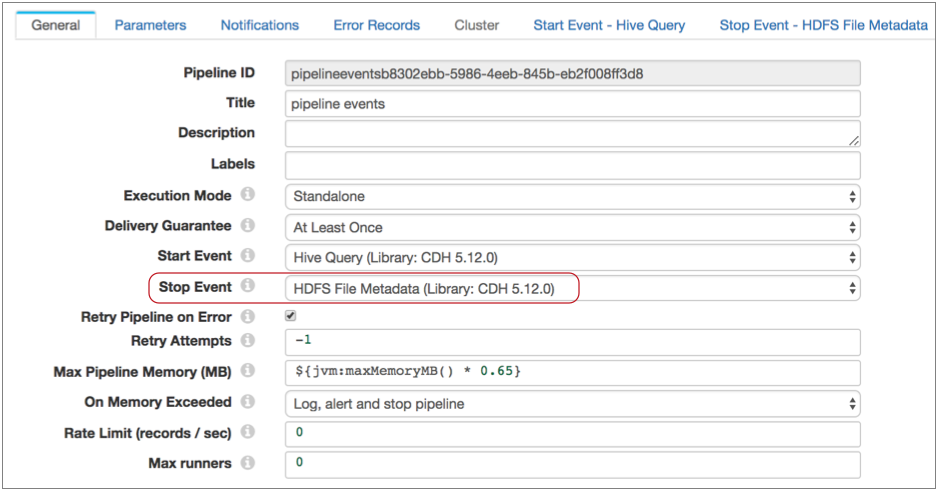
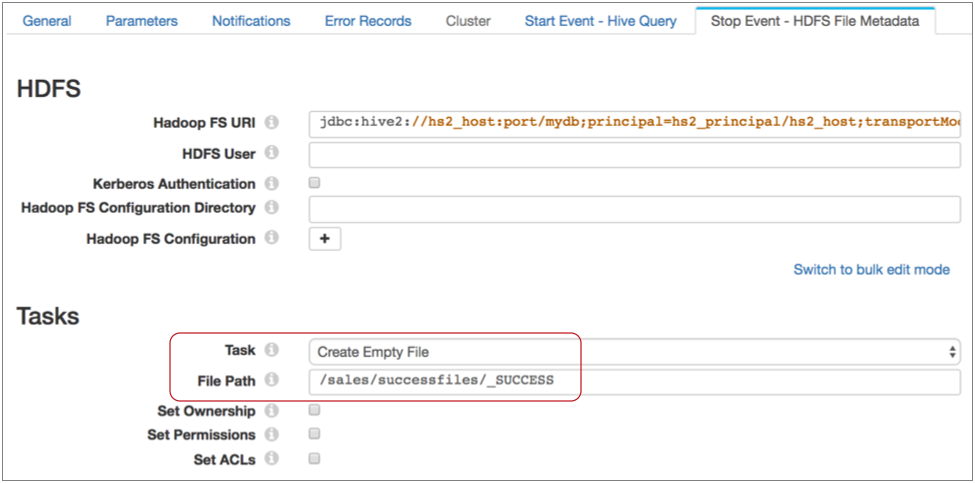
- Then, on the Stop Event - HDFS File Metadata tab, specify
the connection information and configure the executor to create the success file
in the required directory with the specified name.
With these configurations in place, when you start the pipeline, the Hive Query executor truncates the table specified in the query, then pipeline processing begins. When the JDBC Multitable Consumer completes processing all available data, it passes a no-more-data event to the Pipeline Finisher executor.
The Pipeline Finisher executor allows the pipeline stop event to trigger the HDFS File Metadata executor to create the empty file, then brings the pipeline to a graceful stop. Batch job complete!