Text Data Format with Custom Delimiters
By default, the text data format creates records based on line breaks, creating a record for each line of text. You can configure origins to create records based on custom delimiters.
Use custom delimiters when the origin system uses delimiters to separate logical sections of data that you want to use as records. A custom delimiter might be as simple as a semicolon or might be a set of characters. You can even use an XML tag as a custom delimiter to read XML data.
You can include the custom delimiters in records or you can remove them.
8/12/2016 6:01:00 unspecified error message;8/12/2016
6:01:04 another error message;8/12/2016 6:01:09 just a warning message;| Text |
|---|
| 8/12/2016 6:01:00 unspecified error message |
| 8/12/2016 6:01:04 another error message |
| 8/12/2016 6:01:09 just a warning message |
Note that the origin retains the line break, but does not use it to create a separate record.
Processing XML Data with Custom Delimiters
You can use custom delimiters with the text data format to process XML data. You might use the text data format to process XML data with no root element, which cannot be processed with the XML data format.
When using the text data format in the origin to read XML data, you can use the XML Parser processor downstream to parse the XML data.
For example, the following XML document is valid and is best processed using the XML data format:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<msg>
<time>8/12/2016 6:01:00</time>
<request>GET /index.html 200</request>
</msg>
<msg>
<time>8/12/2016 6:03:43</time>
<request>GET /images/sponsored.gif 304</request>
</msg>
</root><msg>
<time>8/12/2016 6:01:00</time>
<request>GET /index.html 200</request>
</msg>
<msg>
<time>8/12/2016 6:03:43</time>
<request>GET /images/sponsored.gif 304</request>
</msg>You can use the text data format with a custom delimiter to process the invalid XML document. To do so, use </msg> as the custom delimiter to separate data into records, and make sure to include the delimiter in the record as follows:

| text |
|---|
| <msg> <time>8/12/2016 6:01:00</time> <request>GET /index.html 200</request> </msg> |
| <msg> <time>8/12/2016 6:03:43</time> <request>GET /images/sponsored.gif 304</request> </msg> |
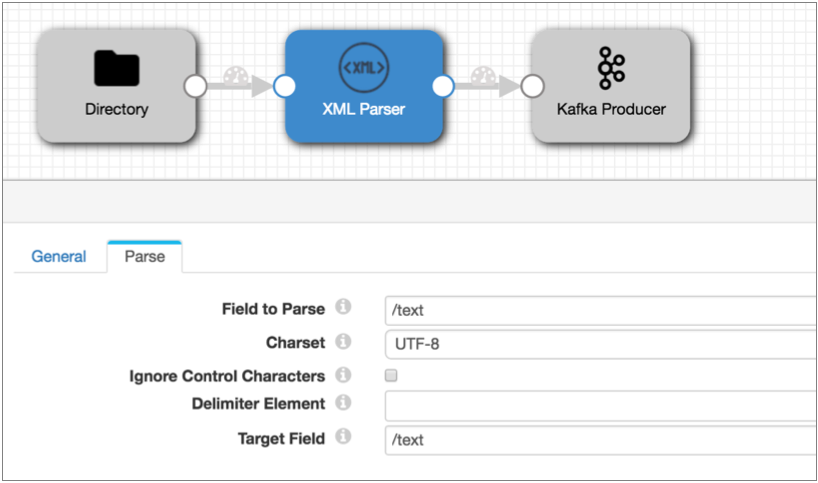
| text <map> |
|---|
- time <list>:
- request <list>:
|
- time <list>:
- request <list>:
|