Join
The Join processor joins data from two input streams. When you use more than one origin in a pipeline, you must use the Join processor to join the data read by the origins. When needed, you can use a Join processor to join lookup data to primary pipeline data.
You can add the Join processor immediately after the origin stages. Or, you can add other processors after the origins to perform additional transformations and then use the Join processor to join the data.
Each Join processor can join data from two input streams. To join more than two input streams in a single pipeline, use additional Join processors in the pipeline. However, be aware that the Join processor causes Spark to shuffle the data, redistributing the data so that it's grouped differently across the partitions, which can be an expensive operation.
When you configure the Join processor, you specify the type of join and the criteria used to perform the join. To avoid duplicate field names in the resulting data, you can also specify prefixes to add to field names from each input stream.
Join Types
- Cross - Returns the Cartesian product of two sets of data.
- Inner - Returns records that have matching values in both inputs.
- Full outer - Returns all records, including records that have matching values in both inputs and records from either input that do not have a match.
- Left anti - Returns records from the left input that do not have a match in the right input.
- Left outer - Returns records from the left input, and the matched records from the right input.
- Left semi - Returns records that have matching values in both inputs, but includes only the data from the left input.
- Right anti - Returns records from the right input that do not have a match in the left input.
- Right outer - Returns records from the right input, and the matched records from the left input.
In the pipeline canvas, the first input stream that you connect to the Join processor represents the left input. The second input stream that you connect to the processor represents the right input.
For example, in the following image, the customers input stream represents the left input because it was connected to the processor first. The orders input stream represents the right input because it was connected to the processor second.
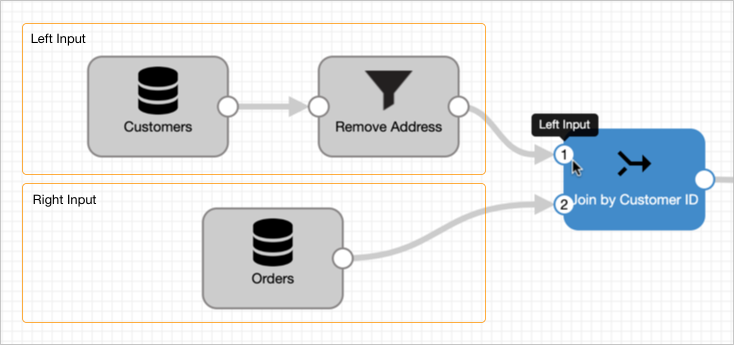
You can swap the left and right inputs by clicking the processor and then clicking ![]() .
.
Let's look at an example for each join type. We'll join customer and order data using the
matching field named customer_id as the join criteria.
| customer_id | customer_name |
|---|---|
| 2 | Anna Smith |
| 47 | Raquel Trujillo |
| 98 | Theo Barnes |
| customer_id | order_id | amount |
|---|---|---|
| 2 | 1075623 | 34.56 |
| 47 | 1076645 | 234.67 |
| 342 | 1050945 | 126.05 |
Cross Join
A cross join returns the Cartesian product of two sets of data. A Cartesian product is the set of all possible ordered pairs between the two inputs.
When configuring the Join processor to perform a cross join, you do not specify the join criteria used to perform the join.
When the Join processor performs a cross join on our sample data, the processor produces the following output:
| customer_id | customer_name | customer_id | order_id | amount |
|---|---|---|---|---|
| 2 | Anna Smith | 2 | 1075623 | 34.56 |
| 47 | Raquel Trujillo | 2 | 1075623 | 34.56 |
| 98 | Theo Barnes | 2 | 1075623 | 34.56 |
| 2 | Anna Smith | 47 | 1076645 | 234.67 |
| 47 | Raquel Trujillo | 47 | 1076645 | 234.67 |
| 98 | Theo Barnes | 47 | 1076645 | 234.67 |
| 2 | Anna Smith | 342 | 1050945 | 126.05 |
| 47 | Raquel Trujillo | 342 | 1050945 | 126.05 |
| 98 | Theo Barnes | 342 | 1050945 | 126.05 |
Inner Join
An inner join returns records that have matching values in both inputs.
customer_id as the join
field, the processor produces the following output:| customer_id | customer_name | order_id | amount |
|---|---|---|---|
| 2 | Anna Smith | 1075623 | 34.56 |
| 47 | Raquel Trujillo | 1076645 | 234.67 |
Full Outer Join
A full outer join returns all records, including records that have matching values in both inputs and records from either input that do not have a match.
customer_id as the join field, the
processor produces the following output: | customer_id | customer_name | order_id | amount |
|---|---|---|---|
| 2 | Anna Smith | 1075623 | 34.56 |
| 47 | Raquel Trujillo | 1076645 | 234.67 |
| 98 | Theo Barnes | ||
| 342 | 1050945 | 126.05 |
{"customer_id":98,"customer_name":"Theo Barnes"}
{"customer_id":342,"order_id":1050945,"amount":126.05}Left Anti Join
A left anti join returns records from the left input that do not have a match in the right input.
customer_id as the
join field, the processor produces the following output:| customer_id | customer_name |
|---|---|
| 98 | Theo Barnes |
Left Outer Join
A left outer join returns records from the left input, and the matched records from the right input.
customer_id as the join field, the
processor produces the following output:| customer_id | customer_name | order_id | amount |
|---|---|---|---|
| 2 | Anna Smith | 1075623 | 34.56 |
| 47 | Raquel Trujillo | 1076645 | 234.67 |
| 98 | Theo Barnes |
Note that the processor doesn't return a table in the output, but returns records. In a returned record, the processor omits fields that have no values. For example, in our sample output data above, the processor does not include the fields with missing values in the third record. The processor produces the following output for this record:
{"customer_id":98,"customer_name":"Theo Barnes"}Left Semi Join
A left semi join returns records that have matching values in both inputs, but does not include the merged data from both inputs. The results include only the data from the left input.
customer_id as the
join field, the processor produces the following output:| customer_id | customer_name |
|---|---|
| 2 | Anna Smith |
| 47 | Raquel Trujillo |
Right Anti Join
A right anti join returns records from the right input that do not have a match in the left input.
customer_id as the join field, the
processor produces the following output:| customer_id | order_id | amount |
|---|---|---|
| 342 | 1050945 | 126.05 |
Right Outer Join
A right outer join returns records from the right input, and the matched records from the left input.
customer_id as the join field, the
processor produces the following output:| customer_id | customer_name | order_id | amount |
|---|---|---|---|
| 2 | Anna Smith | 1075623 | 34.56 |
| 47 | Raquel Trujillo | 1076645 | 234.67 |
| 342 | 1050945 | 126.05 |
Note that the processor doesn't return a table in the output, but returns records. In a returned record, the processor omits fields that have no values. For example, in our sample output data above, the processor does not include the field with a missing value in the third record. The processor produces the following output for this record:
{"customer_id":342,"order_id":1050945,"amount":126.05}Join Criteria
When you configure the Join processor, you define the criteria used to perform the join. The processor can join data based on matching field names or based on a condition that you define.
Matching Field Names
When configured to join by matching field names, the Join processor joins data from two input streams based on one or more matching field names. The field names must be identical in both inputs.
For example,
the processor can join data by department name when both inputs use
dept as the field name. If the inputs use unique field names, use a
condition to join the data. Or, use a Field Renamer processor before the Join processor
to rename one of the fields.
Condition
When configured to join by condition, the Join processor joins data from two input streams based on a condition that you define. The field names used in the condition must be unique in each input. If needed, use a Field Renamer processor before the Join processor to rename the fields.
dept as the field name and the other input uses
department as the field name, define the following join condition:
dept = departmentWhen the processor performs the join, it adds both fields to the output. For example,
both dept and department are added to the output with
the same value of Sales. To remove one of the fields, use the Field
Remover processor after the Join processor.
emp_id = id AND total_salary >= base_salary * 1.2- When you define a condition, you typically base it on field values in the record. For information about referencing fields in the condition, see Referencing Fields in Spark SQL Expressions.
- You can use any Spark SQL
syntax that can be used in the JOIN clause of a query, including functions such as
isnullortrimand operators such as=or<=.You can also use user-defined functions (UDFs), but you must define the UDFs in the pipeline. Use a pipeline preprocessing script to define UDFs.
For more information about Spark SQL functions, see the Apache Spark SQL Functions documentation.
id = order_id AND year(transaction_date) >= 2000Sample Conditions
The following table lists some common scenarios that you might adapt for your use:| Condition Example | Description |
|---|---|
cust_no = cust_id AND total > 0 |
Join records with the same value for the customer ID and
where the value in the total field is greater
than 0. |
cust_no = cust_id AND cust_name =
customer_name |
Join records with the same values for both the customer ID and the customer name. |
order_id = ORDERID AND accountId is NOT
NULL |
Join records with the same value for the order ID and where
the record has a value in the accountId field.
Note that |
(emp_id = employee_id) AND (initcap(country) like
'China' OR initcap(country) like 'Japan') |
Join records with the same value for the employee ID and
where the value in the country field is
China or Japan.The
condition changes the strings in the
|
Configuring a Join Processor
Configure a Join processor to join data from two input streams. When you use more than one origin in a pipeline, you must use the Join processor to join the data read by the origins.
-
In the Properties panel, on the General tab, configure the
following properties:
General Description Name Stage name. Description Optional description. Cache Data Caches data processed for a batch so the data can be reused for multiple downstream stages. Use to improve performance when the stage passes data to multiple stages. Caching can limit pushdown optimization when the pipeline runs in ludicrous mode.
-
On the Join tab, configure the following properties:
Join Property Description Join Type Type of join to perform: - Cross - Returns the Cartesian product of two sets of data.
- Inner - Returns records that have matching values in both inputs.
- Full outer - Returns all records, including records that have matching values in both inputs and records from either input that do not have a match.
- Left anti - Returns records from the left input that do not have a match in the right input.
- Left outer - Returns records from the left input, and the matched records from the right input.
- Left semi - Returns records that have matching values in both inputs, but includes only the data from the left input.
- Right anti - Returns records from the right input that do not have a match in the left input.
- Right outer - Returns records from the right input, and the matched records from the left input.
Add Prefix to Field Names Adds specified prefixes to the names of fields not specified as matching fields. Use to avoid duplicate field names from the two inputs in the joined record. When you select this property, you must specify at least one prefix, for either the left input or the right input.
Left Prefix Text added to the start of field names in the left input. Do not include periods. Right Prefix Text added to the start of field names in the right input. Do not include periods. Join Criteria Criteria used to perform the join: - Matching Fields - Join data based on one or more matching field names.
- Condition - Join data based on a condition that you define.
Not used for a cross join.
Matching Fields Names of the matching fields used to perform the join. Click the Add icon to specify each field name. The field names must be identical in both inputs.
Condition Condition used to perform the join. The field names used in the condition must be unique in each input.