Local Pipelines
Typically, you run a Transformer pipeline on a cluster. You can also run a pipeline on a Spark installation on the Transformer machine. This is known as a local pipeline.
In a production environment, configure pipelines to run on the cluster to leverage the performance and scale that Spark offers. However during development, you might want to develop and test pipelines on the local Spark installation.
To run a local pipeline, Spark must be installed on the Transformer machine. If the Transformer machine is also configured to submit Spark jobs to a cluster, you can configure pipelines to run either locally or on the cluster.
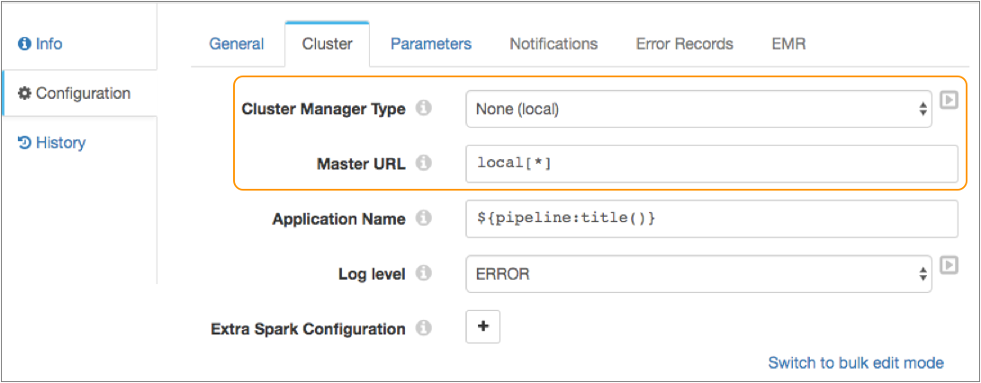
To run a local pipeline, configure the pipeline to use no cluster manager on the Cluster tab, and then define the local master URL to use to connect to Spark.
You can define any valid local master URL as described in the
Spark Master URL documentation. The default master URL is local[*] which runs the pipeline in
the local Spark installation using the same number of worker threads as logical
cores on the machine.
When you start a local pipeline, Transformer uses the user that runs the Transformer process to launch the Spark application. Transformer runs as the user account logged into the command prompt or as the user account that you impersonate when you run the command.
The following image displays a local pipeline configured to run on the local Spark installation: