Kafka
The Kafka origin reads data from one or more topics in an Apache Kafka cluster. All messages in a batch must use the same schema. The origin supports Apache Kafka 0.10 and later. When using a Cloudera distribution of Apache Kafka, use CDH Kafka 3.0 or later.
The Kafka origin can read messages from a list of Kafka topics or from topics that match a pattern defined in a Java-based regular expression. When reading topics in the first batch, the origin can start from the first message, the last message, or a particular position in a partition. In subsequent batches, the origin starts from the last-saved offset.
When configuring the Kafka origin, you specify the Kafka brokers that the origin can initially connect to, the topics the origin reads, and where to start reading each topic. You can configure the origin to connect securely to Kafka. You specify the maximum number of messages to read from any partition in each batch. You can configure the origin to include Kafka message keys in records. You can also specify additional Kafka configuration properties to pass to Kafka.
You can also use a connection to configure the origin.
You select the data format of the data and configure related properties. When processing delimited or JSON data, you can define a custom schema for reading the data and configure related properties.
You can configure the origin to load data only once and cache the data for reuse throughout the pipeline run. Or, you can configure the origin to cache each batch of data so the data can be passed to multiple downstream batches efficiently. You can also configure the origin to skip tracking offsets.
Partitioning
Spark runs a Transformer pipeline just as it runs any other application, splitting the data into partitions and performing operations on the partitions in parallel. When the pipeline starts processing a new batch, Spark determines how to split pipeline data into initial partitions based on the origins in the pipeline.
For a Kafka origin, Spark determines the partitioning based on the number of partitions in the Kafka topics being read.
For example, if a Kafka origin is configured to read from 10 topics that each have 5 partitions, Spark creates a total of 50 partitions to read from Kafka.
Spark uses these partitions while the pipeline processes the batch unless a processor causes Spark to shuffle the data. To change the partitioning in the pipeline, use the Repartition processor.
Topic Specification
The Kafka origin reads data in messages from one or more topics that you specify.
- Topic list
- Add a list of topics from your Kafka cluster. For example, suppose you want the origin to read two topics named orders_exp and orders_reg. When configuring the origin, clear the Use Topic Pattern property and in the Topic List property, add the following two topics:
- orders_exp
- orders_reg
- Topic pattern
- Specify a Java-based regular expression that identifies topics from your
Kafka cluster.
For example, suppose your cluster has four topics named cust_east, cust_west, orders_exp, and orders_reg. To read the two topics cust_east and cust_west, you can use an expression. Select the Use Topic Pattern property and in the Topic Pattern property, enter the Java expression c+.
With this configuration, if you later add the topic cust_north to your cluster, the origin will automatically read the new topic.
Offsets
In a Kafka topic, an offset identifies a message in a partition. When configuring the Kafka origin, you define the starting offset to specify the first message to read in each partition of a topic.
- Earliest
- The origin reads all available messages, starting with the first message in each partition of each topic.
- Latest
- The origin reads the last message in each partition of each topic and any subsequent messages added to those topics after the pipeline starts.
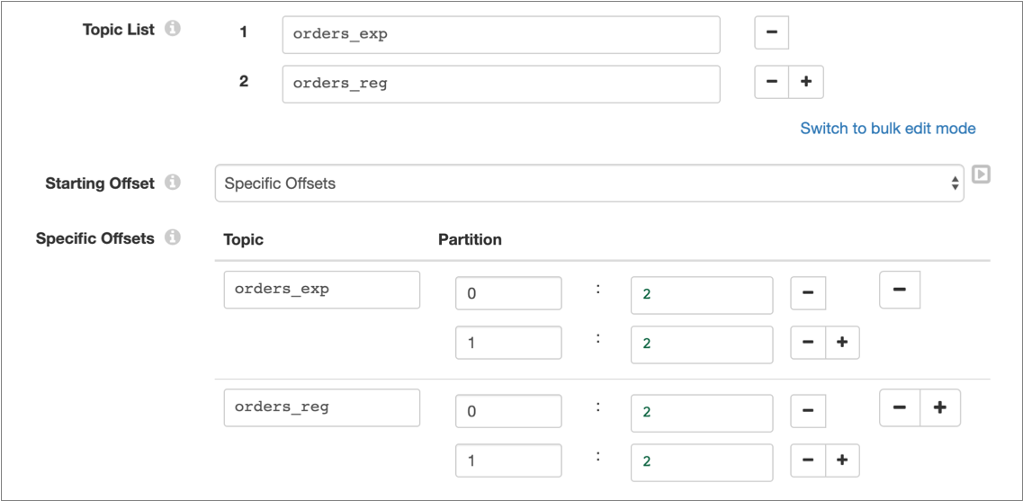
- Specific offsets
- The origin reads messages starting from a specified offset for each partition in each topic. If an offset is not specified for a partition in a topic, the origin returns an error.
When reading the last message in a batch, the origin saves the offset from that message. In the subsequent batch, the origin starts reading from the next message.
For example, suppose the orders_exp and
orders_reg topics have two partitions, 0 and
1. To have the origin read from the partitions starting with
the third message, which has an offset of 2, configure the origin
as follows:
Kafka Security
You can configure the originto connect securely to Kafka through SSL/TLS, SASL, or both. For more information about the methods and details on how to configure each method, see Security in Kafka Stages.
Data Formats
The Kafka origin generates records based on the specified data format.
- Avro
- The origin generates a record for every message. You can use one of the following methods to specify the location of the Avro schema definition:
- In Pipeline Configuration - Use the schema defined in the stage properties.
- Confluent Schema Registry - Retrieve the schema from Confluent Schema Registry. Confluent Schema Registry is a distributed storage layer for Avro schemas. You specify the URL to Confluent Schema Registry and whether to look up the schema by the schema ID or subject.
- Delimited
- The origin generates a record for every message. You can specify a custom delimiter, quote, and escape character used in the data.
- JSON
- The origin generates a record for every message.
- Text
- The origin generates a record for every message.
Configuring a Kafka Origin
Configure a Kafka origin to read data from topics in an Apache Kafka cluster.
-
On the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Stage Library Stage library to use to connect to Kafka: - Kafka cluster-provided libraries - The cluster where the pipeline runs has Kafka libraries installed, and therefore has all of the necessary libraries to run the pipeline.
- Kafka Transformer-provided libraries - Transformer passes the necessary libraries with the pipeline
to enable running the pipeline.
Use when running the pipeline locally or when the cluster where the pipeline runs does not include the Kafka libraries.
Note: When using additional Kafka stages in the pipeline, ensure that they use the same stage library.Load Data Only Once Reads data while processing the first batch of a pipeline run and caches the results for reuse throughout the pipeline run. Select this property for lookup origins. When configuring lookup origins, do not limit the batch size. All lookup data should be read in a single batch.
Cache Data Caches data processed for a batch so the data can be reused for multiple downstream stages. Use to improve performance when the stage passes data to multiple stages. Caching can limit pushdown optimization when the pipeline runs in ludicrous mode.
Available when Load Data Only Once is not enabled. When the origin loads data once, the origin caches data for the entire pipeline run.
Skip Offset Tracking Skips tracking offsets. The origin reads all available data for each batch that the pipeline processes, limited by any batch-size configuration for the origin.
-
On the Kafka tab, configure the following
properties:
Kafka Property Description Connection Connection that defines the information required to connect to an external system. To connect to an external system, you can select a connection that contains the details, or you can directly enter the details in the pipeline. When you select a connection, Control Hub hides other properties so that you cannot directly enter connection details in the pipeline.
To create a new connection, click the Add New Connection icon:
 . To view and edit the details of the
selected connection, click the Edit
Connection icon:
. To view and edit the details of the
selected connection, click the Edit
Connection icon:  .
.Broker URIs List of comma-separated pairs of hosts and ports used to establish the initial connection to the Kafka cluster. Use the following format: <host1>:<port1>,<host2>:<port2>,…
Once a connection is established, the stage discovers the full set of available brokers.
Match Topic Pattern Enables the origin to find the topics to read based on a regular expression. When not used, you enter a list of topics. Topic Pattern Java-based regular expression (regex) that specifies the topics to read. Available when you specify topics based on pattern.
Topic List List of Kafka topics to read. Click the Add icon to add additional topics. You can use simple or bulk edit mode to configure the topics.
Available when you do not specify topics based on pattern.
Include Message Keys Includes the Kafka message keys in a String field named key.Can be used with all data formats except Delimited.
Starting Offset Method to determine first message to read: - Earliest - Reads messages starting with the first messages in each topic.
- Latest - Reads messages starting with the last message in each topic.
- Specific Offsets - For each topic, reads messages from a specified partition and position.
Specific Offsets For each topic, the first message to read from each partition. For the first topic, enter the topic name, then if needed, click the Add Partition icon to add fields for specifying the partition names and starting positions for the topic.
For additional topics, click the Add Topic icon to add another topic field, and add partition information as needed.
You must specify an offset for each partition in a topic.
Available when Starting Offset is set to Specific Offsets.
Max Messages per Partition In each batch, the maximum number of messages the origin reads from each partition in a topic. Additional Configurations Additional Kafka configuration properties to pass to Kafka. To add properties, click the Add icon and define the Kafka property name and value. Usekafka.as a prefix for the property names, as follows:kafka.<kafka property name> -
On the Security tab, configure the security properties
to enable the origin to securely connect to Kafka.
For information about the security options and additional steps required to enable security, see Security in Kafka Stages.
-
On the Data Format tab, configure the following
property:
Data Format Property Description Data Format Format of data in Kafka messages. Select one of the following formats: - Avro
- Delimited
- JSON
- Text
-
For Avro data, click the Schema tab and configure the
following properties:
Avro Property Description Avro Schema Location Location of the Avro schema definition to use to process data: - In Pipeline Configuration - Use the schema specified in the Avro Schema property.
- Confluent Schema Registry - Retrieve the schema from Confluent Schema Registry.
Avro Schema Avro schema definition used to process the data. Overrides any existing schema definitions associated with the data. You can optionally use the
runtime:loadResourcefunction to use a schema definition stored in a runtime resource file.Available when Avro Schema Location is set to In Pipeline Configuration.
Register Schema Registers the specified Avro schema with Confluent Schema Registry. Available when Avro Schema Location is set to In Pipeline Configuration.
Schema Registry URLs Confluent Schema Registry URLs used to look up the schema. To add a URL, click Add. Use the following format to enter the URL: http://<host name>:<port number>Available when Avro Schema Location is set to In Pipeline Configuration.
Basic Auth User Info Confluent Schema Registry basic.auth.user.infocredential.Available when Avro Schema Location is set to Confluent Schema Registry.
Lookup Schema By Method used to look up the schema in Confluent Schema Registry: - Subject - Look up the specified Avro schema subject.
- Schema ID - Look up the specified Avro schema ID.
Available when Avro Schema Location is set to In Pipeline Configuration.
Schema Subject Avro schema subject to look up in Confluent Schema Registry. If the specified subject has multiple schema versions, the origin uses the latest schema version for that subject. To use an older version, find the corresponding schema ID, and then set the Look Up Schema By property to Schema ID.
Available when Avro Schema Location is set to In Pipeline Configuration.
Schema ID Avro schema ID to look up in the Confluent Schema Registry. Available when Avro Schema Location is set to In Pipeline Configuration.
-
For delimited data, on the Data Format tab, optionally
configure the following properties:
Delimited Property Description Delimiter Character Delimiter character used in the data. Select one of the available options or select Other to enter a custom character. You can enter a Unicode control character using the format \uNNNN, where N is a hexadecimal digit from the numbers 0-9 or the letters A-F. For example, enter \u0000 to use the null character as the delimiter or \u2028 to use a line separator as the delimiter.
Quote Character Quote character used in the data. Escape Character Escape character used in the data Includes Header Indicates that the data includes a header line. When selected, the origin uses the first line to create field names and begins reading with the second line. -
To use a custom schema for delimited or JSON data, click the
Schema tab and configure the following
properties:
Schema Property Description Schema Mode Mode that determines the schema to use when processing data: - Infer from Data
The origin infers the field names and data types from the data.
- Use Custom Schema - JSON Format
The origin uses a custom schema defined in the JSON format.
- Use Custom Schema - DDL Format
The origin uses a custom schema defined in the DDL format.
Note that the schema is applied differently depending on the data format of the data.
Schema Custom schema to use to process the data. Enter the schema in DDL or JSON format, depending on the selected schema mode.
Error Handling Determines how the origin handles parsing errors: - Permissive - When the origin encounters a problem parsing any field in the record, it creates a record with the field names defined in the schema, but with null values in every field.
- Drop Malformed - When the origin encounters a problem parsing any field in the record, it drops the entire record from the pipeline.
- Fail Fast - When the origin encounters a problem parsing any field in the record, it stops the pipeline.
Original Data Field Field where the data from the original record is written when the origin cannot parse the record. When writing the original record to a field, you must add the field to the custom schema as a String field.
Available when using permissive error handling.
- Infer from Data