Creating Pipelines
Section Contents
Creating Pipelines#
Pipeline creation and management in the Platform SDK follows the structure and conventions that you’re already used to in the UI, while offering an extensible, programmatic interaction with pipeline objects.
For more details, refer to the StreamSets Platform Documentation for pipelines.
Instantiating a Pipeline Builder#
In the UI, a pipeline can be created and modified from the Pipelines section as seen below:
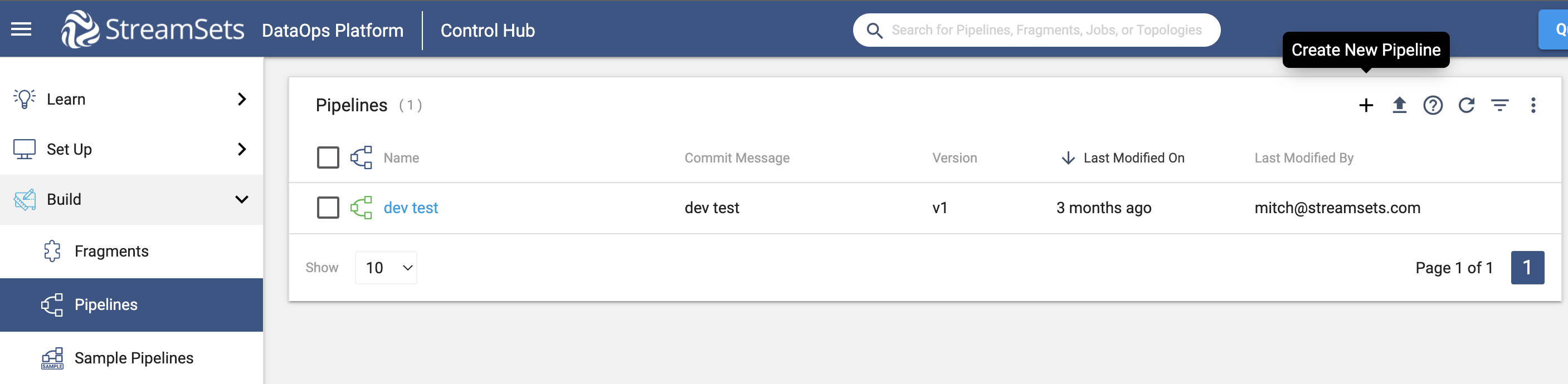
To accomplish the same task and create a pipeline using the SDK, the first step is to instantiate a
streamsets.sdk.sch_models.PipelineBuilder instance. This class handles the majority of the pipeline
configuration on your behalf by building the initial JSON representation of the pipeline, and setting default values for
essential properties (instead of requiring each to be set manually). Use the streamsets.sdk.ControlHub.get_pipeline_builder()
method to instantiate the builder object by passing in the engine_type for the pipeline you plan to create -
available engine types are 'data_collector', 'snowflake', or 'transformer'.
Instantiating a streamsets.sdk.sch_models.PipelineBuilder instance for either
the 'data_collector' or 'transformer' engine types requires the Authoring Engine be specified for the pipeline.
It can be passed into the builder’s instantiation via the engine_id parameter:
sdc = sch.data_collectors.get(url='<data_collector_address>')
# Available engine types are 'data_collector', 'snowflake', or 'transformer'
pipeline_builder = sch.get_pipeline_builder(engine_type='data_collector', engine_id=sdc.id)
The 'transformer' engine type follows the same conventions:
transformer = sch.transformers.get(url='<transformer_address>')
pipeline_builder = sch.get_pipeline_builder(engine_type='transformer', engine_id=transformer.id)
On the other hand, when instantiating a streamsets.sdk.sch_models.PipelineBuilder instance for the
'snowflake' engine type, the engine_id parameter should not be specified:
pipeline_builder = sch.get_pipeline_builder(engine_type='snowflake')
Adding Stages to the Pipeline Builder#
Once the pipeline is created, you can add stages to it using the Pipeline Canvas UI, seen below:
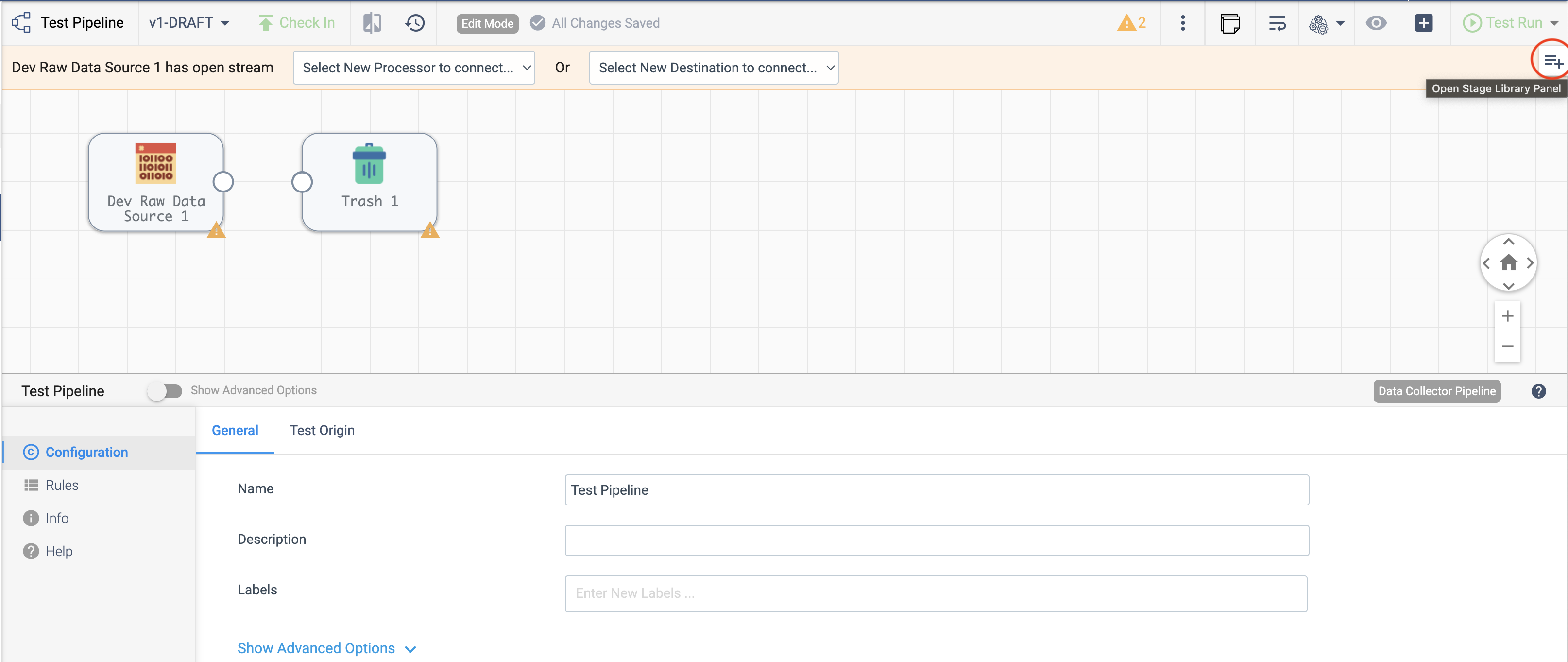
To add stages to the pipeline using the SDK, utilize the streamsets.sdk.sch_models.PipelineBuilder.add_stage()
method - see the API reference for this method for details on the arguments this method takes.
As shown in the image above, the simplest type of pipeline directs one origin into one destination. For this example,
you can do this with Dev Raw Data Source origin and Trash destination, respectively:
dev_raw_data_source = pipeline_builder.add_stage('Dev Raw Data Source')
trash = pipeline_builder.add_stage('Trash')
Note
Dev Raw Data Source origin cannot be used in Transformer for Snowflake pipelines.
Instead, use Snowflake Table or Snowflake Query
Connecting the Stages#
Once stages have been added in the Pipeline Canvas, linking the output of one stage to the input of another connects them, as seen below:
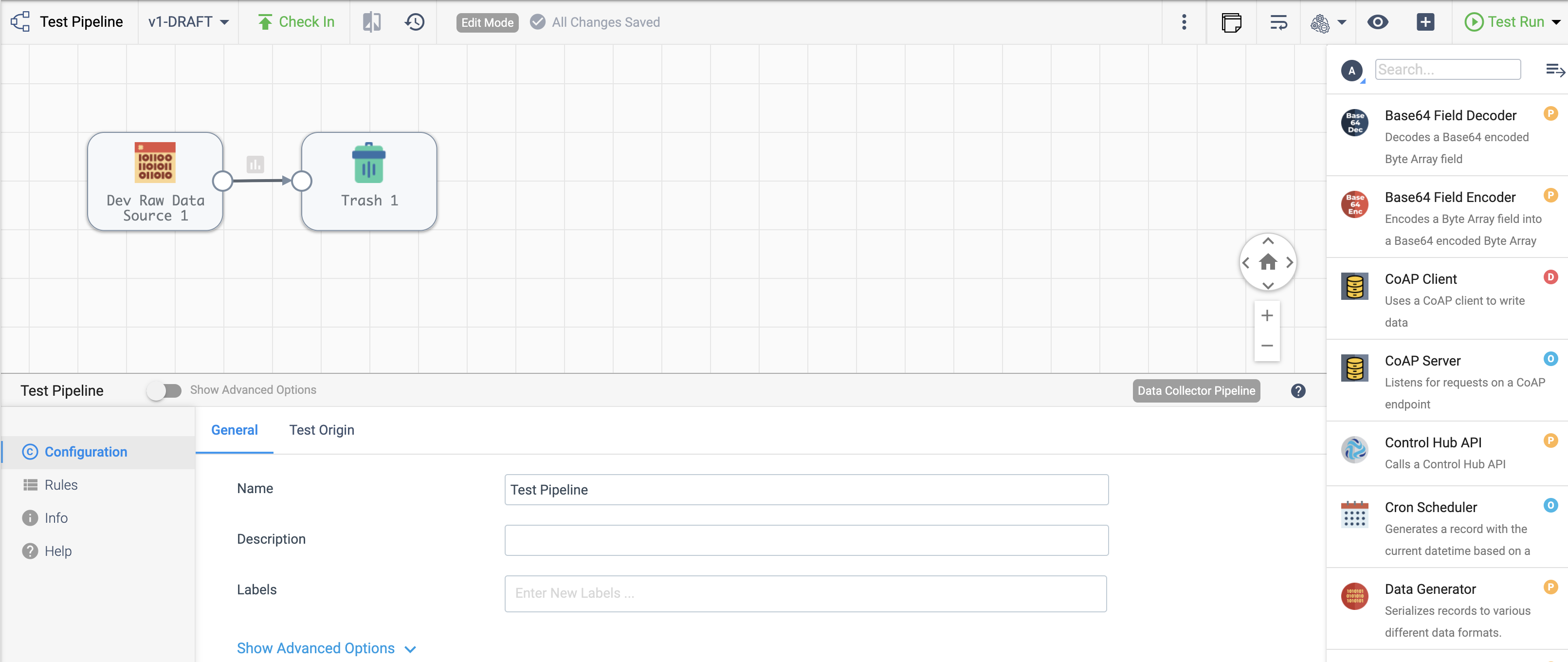
With streamsets.sdk.sch_models.SchSdcStage instances in hand, you can connect them by using the >>
operator. Connecting the Dev Raw Data Source origin and Trash destination from the example above would look
like the following:
dev_raw_data_source >> trash
Output:
<com_streamsets_pipeline_stage_destination_devnull_NullDTarget (instance_name=Trash_01)>
You can also connect a stage’s event stream to another stage, like a pipeline finisher, using a similar convention. To
connect a stage’s event stream to another stage, use the >= operator:
pipeline_finisher = pipeline_builder.add_stage('Pipeline Finisher Executor')
dev_raw_data_source >= pipeline_finisher
Once the stages are connected, you can build the streamsets.sdk.sch_models.Pipeline instance with
the streamsets.sdk.sch_models.PipelineBuilder.build() method:
pipeline = pipeline_builder.build('My first pipeline')
pipeline
Output:
<Pipeline (pipeline_id=None, commit_id=None, name=My first pipeline, version=None)>
When building a Transformer for Snowflake pipeline, there are 4 parameters required by the Pipeline Canvas UI, seen below:
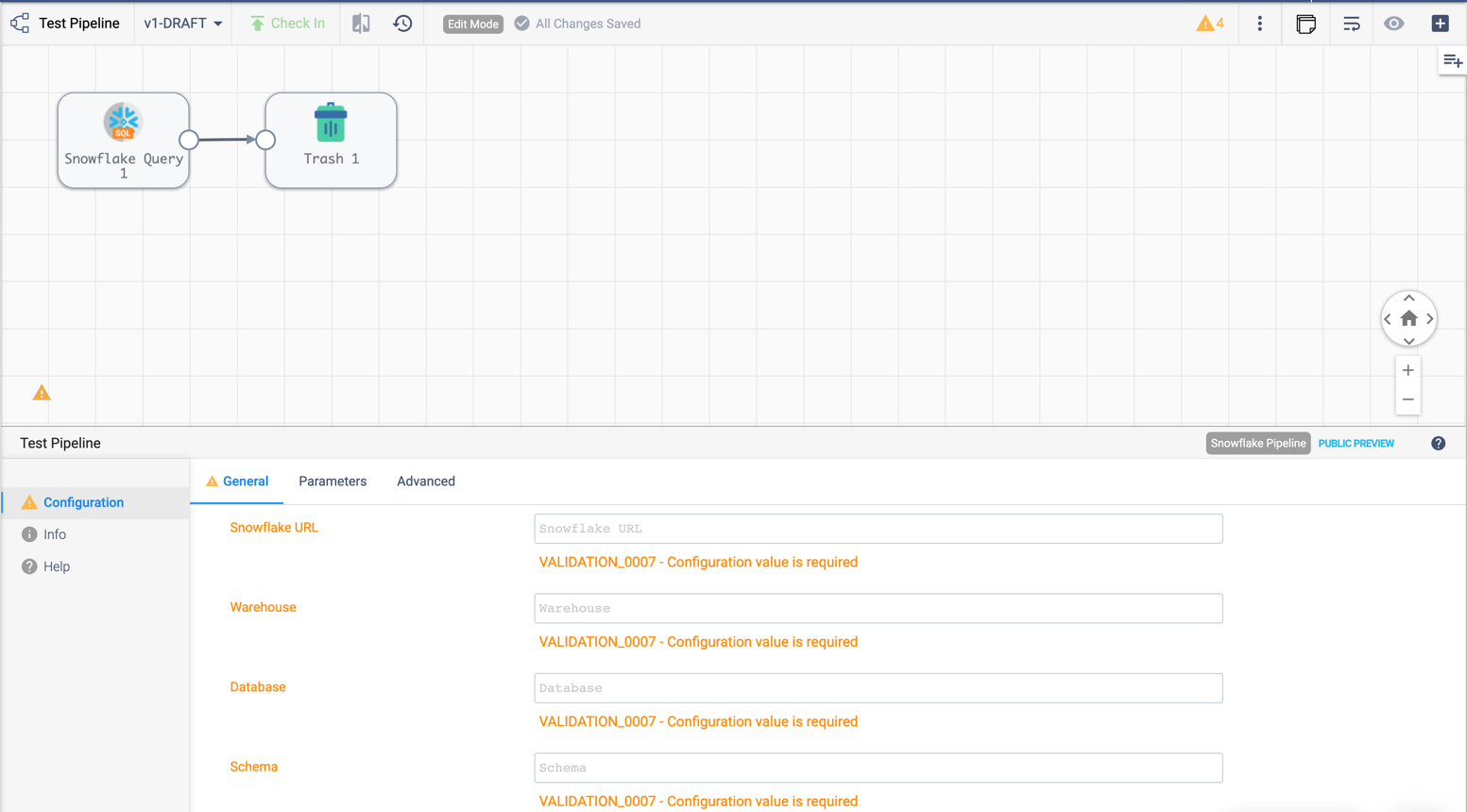
Default values for them can be set in your account (My Account > Snowflake Settings > Snowflake Pipeline Defaults). If they aren’t set, or you want to modify those values, you must do so before publishing the pipeline:
pipeline.configuration['connectionString'] = <Account URL>
pipeline.configuration['warehouse'] = <Warehouse>
pipeline.configuration['db'] = <Database>
pipeline.configuration['schema'] = <Schema>
Add the Pipeline to the StreamSets Platform#
To add (commit) the pipeline to your StreamSets Platform organization, you can use the Check In button as seen below:
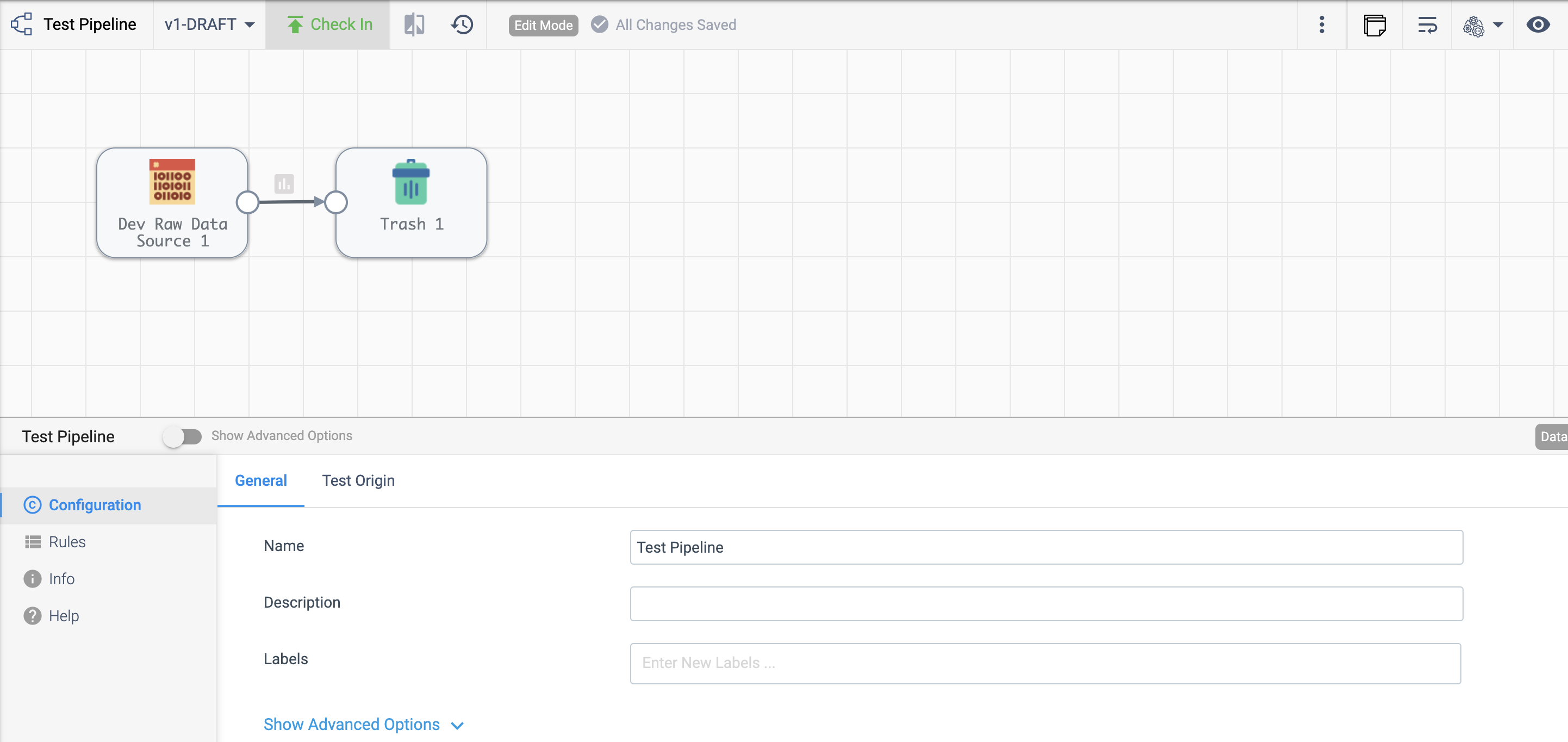
To add a pipeline to your StreamSets Platform organization using the SDK, pass the built pipeline to the
streamsets.sdk.ControlHub.publish_pipeline() method:
sch.publish_pipeline(pipeline, commit_message='First commit of my first pipeline')
Output:
<streamsets.sdk.sch_api.Command object at 0x7f8f2e0579b0>
Bringing It All Together#
The complete scripts from this section can be found below. Commands that only served to verify some output from the example have been removed.
from streamsets.sdk import ControlHub
sch = ControlHub(credential_id='<credential_id>', token='<token>')
sdc = sch.data_collectors.get(url='<data_collector_address>')
pipeline_builder = sch.get_pipeline_builder(engine_type='data_collector', engine_id=sdc.id)
#transformer = sch.transformers.get(url='<transformer_address>')
#pipeline_builder = sch.get_pipeline_builder(engine_type='transformer', engine_id=transformer.id)
dev_raw_data_source = pipeline_builder.add_stage('Dev Raw Data Source')
trash = pipeline_builder.add_stage('Trash')
dev_raw_data_source >> trash
pipeline = pipeline_builder.build('My first pipeline')
sch.publish_pipeline(pipeline, commit_message='First commit of my first pipeline')
from streamsets.sdk import ControlHub
sch = ControlHub(credential_id='<credential_id>', token='<token>')
pipeline_builder = sch.get_pipeline_builder(engine_type='snowflake')
snowflake_query_origin = pipeline_builder.add_stage('Snowflake Query')
trash = pipeline_builder.add_stage('Trash')
snowflake_query_origin >> trash
pipeline = pipeline_builder.build('My first pipeline')
sch.publish_pipeline(pipeline, commit_message='First commit of my first pipeline')