Snowflake
The Snowflake executor runs one or more user-defined SQL queries each time it receives an event record. For information about supported versions, see Supported Systems and Versions.
Use the executor to run queries as part of an event stream. The executor is designed to load whole files staged by the Snowflake File Uploader destination to Snowflake tables each time that the executor receives an event record. However, you can use the executor to execute any JDBC query supported by Snowflake.
Before you use the Snowflake executor, you must complete a prerequisite task.
When you configure the executor, you specify connection information, one or more SQL queries to run, and how to submit the queries.
You can also configure the executor to generate events for another event stream, and whether you want record count information included in generated event records. For more information about dataflow triggers and the event framework, see Dataflow Triggers Overview.
Prerequisite
Writing data to Snowflake requires that the user specified in the stage has the appropriate Snowflake privileges. The privileges differ depending on the method you use to write to Snowflake. Though you can use any command in the query, the privileges required for the most common commands are below.
When using other commands, see the Snowflake documentation to ensure that the user in the stage has the required privileges.
- COPY command
- When you use the COPY command to load data to Snowflake, the user must have
a Snowflake role with one of the following sets of access privileges:
Object Type Privilege Internal Snowflake stage READ, WRITE Table SELECT, INSERT - MERGE command
- When you use the MERGE command to load data to Snowflake, the user must have
a Snowflake role with one of the following sets of access privileges:
Object Type Privilege Internal Snowflake stage READ, WRITE Table SELECT, INSERT, UPDATE, DELETE
Implementation Notes
Note the following implementation requirements when working with the Snowflake executor:
- The executor is designed to load whole files staged by the Snowflake File Uploader destination to Snowflake tables each time that the executor receives an event record. However, you can use the executor to execute any JDBC query supported by Snowflake.
- It is best practice to configure the Snowflake warehouse to auto-resume upon receiving new queries.
Snowflake File Uploader and Executor Pipelines
Use the Snowflake executor to load data to Snowflake after it is placed by the Snowflake File Uploader destination into an internal stage.
The Snowflake File Uploader destination processes only whole file data, which typically requires a simple origin to destination pipeline. As a result, the typical Snowflake executor pipeline is also simple:
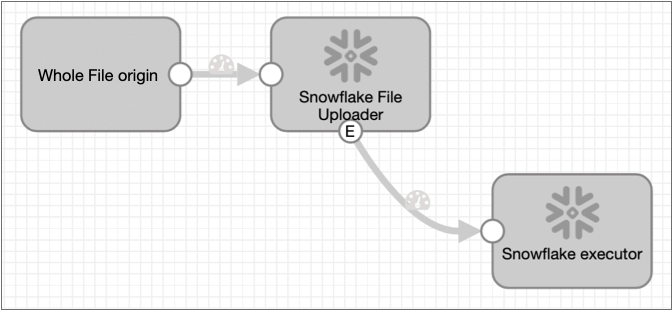
- Whole file origin
- Since the Snowflake File Uploader destination processes only whole file data, you must use a whole file origin to read data for the pipeline. For a list of origins that process whole file data, see Data Formats by Stage.
- Snowflake File Uploader destination
- The Snowflake File Uploader destination processes whole files efficiently and stages output files to an internal Snowflake stage.
- Snowflake executor
- The Snowflake executor submits one or more user-defined SQL queries to Snowflake upon receiving an event record. You configure the executor to load each staged file to the appropriate Snowflake stage.
When the pipeline runs, the Snowflake File Uploader destination generates an event record each time that it writes a file. The Snowflake executor then submits the queries to Snowflake, loading the staged files to Snowflake tables as specified in the queries.
Define a Role
The Snowflake executor requires a Snowflake role that grants all privileges needed to load data using the specified query. Each load method requires a different set of privileges.
Before configuring the executor, ensure that you have granted the required privileges to a Snowflake role, as explained in Prerequisite.
- Assign the custom role as the default role
- In Snowflake, assign the custom role as the default role for the Snowflake user account specified in the stage. A Snowflake user account is associated with a single default role.
- Override the default role with the custom role
- In the stage, use the Role property to specify the name of the custom role. The custom role overrides the role assigned to the Snowflake user account specified in the stage.
SQL Queries
- Query submission
- Configure the Query Submission property to define how the executor submits
your queries:
- Consecutively - The executor submits one query at a time, and waits until the previous query is complete before submitting the next query. Queries are submitted in the order that they appear in the executor.
- Simultaneously - The executor submits all queries at the same time. Snowflake processes the queries one at a time in the order that they appear in the executor. Use this option to reduce network traffic.
- Referencing tables
-
Each query can write to one or more Snowflake tables. When specifying a table, use the full path to the table, as follows:
<warehouse>.<database>.<schema>.<table>Note that
<warehouse>may be required in some instances. - Expressions in queries
- You can use Data Collector expressions in the SQL query. These expressions are evaluated before the executor passes the query to Snowflake.
Sample Queries
To load each file written by the Snowflake File Uploader destination to the same Snowflake table, you might use the following query:COPY into <target_warehouse>.<target_database>.<target_schema>.<target_table>
from @<staging_warehouse>.<staging_database>.<staging_schema>.<internal_stage/${record:value('/filename')}>;COPY into sharedDB.sales.infotable
from @myDB.mystaging.sdcstaging/${record:value('/filename')};filename field in the event
record:COPY into <target_warehouse>.<target_database>.<target_schema>.${record:value('/filename')}
from @<staging_warehouse>.<staging_database>.<staging_schema>.<internal_stage/${record:value('/filename')}>;COPY into sharedDB.sales.${record:value('/filename')}
from @myDB.mystaging.sdcstaging/${record:value('/filename')};Event Generation
The Snowflake executor can generate events that you can use in an event stream. When you enable event generation, the executor generates events for each successful or failed query.
- With the Email executor to send a custom email
after receiving an event.
For an example, see Sending Email During Pipeline Processing.
- With a destination to store event information.
For an example, see Preserving an Audit Trail of Events.
For more information about dataflow triggers and the event framework, see Dataflow Triggers Overview.
Event Record
| Record Header Attribute | Description |
|---|---|
| sdc.event.type | Event type. Uses the following event types:
|
| sdc.event.version | Integer that indicates the version of the event record type. |
| sdc.event.creation_timestamp | Epoch timestamp when the stage created the event. |
- Successful query
-
The executor generates a successful-query event record after successfully completing a query.
Successful-query event records have thesdc.event.typerecord header attribute set tosucessful-queryand include the following fields:Event Field Name Description query Query completed. query-result Number of rows affected by query. Included if the Include Query Result Count in Events property is selected. - Failed query
-
The executor generates a failed-query event record after failing to complete a query.
Failed-query event records have thesdc.event.typerecord header attribute set tofailed-queryand include the following field:Event Field Name Description query Query attempted.
Configuring a Snowflake Executor
Configure a Snowflake executor to write staged whole files to Snowflake tables. Before you use the executor in a pipeline, complete the prerequisite task.
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Produce Events Generates event records when events occur. Use for event handling. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
-
On the Snowflake Connection Info tab, configure the
following properties:
Note: Snowflake JDBC driver versions 3.13.25 or higher convert underscores to hyphens, by default. When needed, you can bypass this behavior by setting the
allowUnderscoresInHostdriver property totrue. For more information and alternate solutions, see this Snowflake community article.Snowflake Connection Property Description Snowflake Region Region where the Snowflake warehouse is located. Select one of the following: - An available Snowflake region.
- Other - Enables specifying a Snowflake region not listed in the property.
- Custom JDBC URL - Enables specifying a virtual private Snowflake installation.
Available when Include Organization is disabled.
Custom Snowflake Region Custom Snowflake region. Available when using Other as the Snowflake region. Organization Snowflake organization. Account Snowflake account name. Authentication Method Authentication method to connect to Snowflake:- User Credentials
- Key Pair Path - Use to specify the location of a private key file.
- Key Pair Content - Use to provide the contents of a private key file.
- OAuth
- None
User Snowflake user name. The user account or the custom role that overrides the default role for this user account must have the required Snowflake privileges.
For information about required privileges, see Prerequisite.
Required when using authentication.
Password Snowflake password. Required when using User Credentials authentication.
Private Key Path Path to the private key file. Required when using Key Pair Path authentication.
Private Key Content Contents of the private key file. Required when using Key Pair Content authentication.
Private Key Password Optional password for the specified private key file or content. Use for encrypted private keys. Available when using Key Pair Path or Key Pair Content authentication.
OAuth Token OAuth token to use. You can use a Snowflake security integration access token, refresh token, or code grant. Required when using OAuth authentication.
OAuth Client ID Client ID for Snowflake security integration access tokens. Available when using OAuth authentication.
OAuth Client Secret Client secret for Snowflake security integration access tokens. Available when using OAuth authentication.
OAuth Redirect URI Redirect URI for Snowflake security integration access tokens. Available when using OAuth authentication.
Role Overrides the default role for the specified user account. The custom role must have the required Snowflake privileges. The required privileges depend on the queries that the executor uses. For details, see Prerequisite.
Warehouse Snowflake warehouse. Database Snowflake database. Schema Snowflake schema. Use a Custom JDBC URL Custom JDBC URL to use when using a virtual private Snowflake installation. Include Organization Enables specifying the Snowflake organization. Connection Pool Size Maximum number of connections that the executor uses. The default, 0, ensures that the executor uses the same number of connections as threads used by the pipeline. When writing to multiple tables, increasing this property can improve performance.
Use Private Link Snowflake URL Enables using a private link URL. You can specify the URL in the Custom JDBC URL property above. Or, you can define the appropriate values for the Account property and either the Snowflake Region or Organization properties.
Connection Properties Additional Snowflake connection properties to use. To add properties, click Add and define the property name and value. Use the property names and values as expected by Snowflake.
-
On the Queries tab, configure the following
properties:
Queries Property Description SQL Queries One or more SQL queries to execute upon receiving an event record. By default, queries are executed in the specified order. To add additional queries, click Add.
Query Submission Determines how the executor submits multiple queries: - Sequential - Submits a query and waits for query completion before submitting another.
- Parallel - Submits all queries at once.
By default, the executor waits for a query to complete before submitting the next query.
Include Query Result Count in Events When the executor is configured to generate events, the executor includes query result counts in event records. -
On the Resilience tab, configure the following
properties:
Resilience Property Description Max Connection Attempts Maximum number of attempts to establish a connection to the data source. Default is 3.
Wait Duration Time in seconds to wait between attempts to establish a connection to the data source. Default is 10 seconds.