Google Bigtable
The Google Bigtable destination writes data to Google Cloud Bigtable. For information about supported versions, see Supported Systems and Versions in the Data Collector documentation.
Before you configure the destination, you must complete several prerequisites including installing the BoringSSL library and configuring the Google Cloud default credentials.
When you configure the destination, you define the instance ID, project ID, and the table that you want to write to. The destination can write to an existing table or can create and write to a new table. You specify the row key for the table, and then map fields from the pipeline to Cloud Bigtable columns.
When necessary, you can configure a time basis and specify the number of records to buffer in each commit to Cloud Bigtable.
Prerequisites
Before you can write to Cloud Bigtable, you must complete the following prerequisites:
- Download and install the BoringSSL library.
- Configure the Google Cloud credentials.
Install the BoringSSL Library
The Google Bigtable destination requires the BoringSSL library. You must download and install the external library so that the Google Bigtable destination can access it.
Download the BoringSSL library from the following location:
Then install the library into the Google Bigtable stage library, streamsets-datacollector-bigtable-lib, which includes the destination.
For information about installing additional drivers, see Install External Libraries in the Data Collector documentation.
Configure Credentials
Configure the Google Cloud default credentials that the Google Bigtable destination uses to connect to Google Cloud Bigtable.
- Create a JSON file that contains the Google Application Default Credentials.
To create the credentials file, use the Google API Console or run the following Google Cloud Platform command:
gcloud auth login.For more information about creating the credentials file, search for Google Application Default Credentials in the Google Developer documentation.
- Store the generated credentials file in a local directory external to the Data Collector
installation directory. For example, if you installed Data Collector in the following directory:
/opt/sdc/you might store the credentials file at:/opt/sdc-credentials - Add the
GOOGLE_APPLICATION_CREDENTIALSenvironment variable to the appropriate file and point it to the credentials file.Modify environment variables using the method required by your installation type.
Set the environment variable as follows:
export GOOGLE_APPLICATION_CREDENTIALS="/opt/sdc-credentials/keyfile.json" - Restart Data Collector to enable the changes.
For more information about environment variables, see Data Collector Environment Configuration in the Data Collector documentation.
Row Key
Each Google Cloud Bigtable table has one index, the row key. When you configure the Google Bigtable destination, you define which field or fields in the record to use as the row key.
Define the row key in one of the following ways:
- Single field as the row key
-
You can define a single field as the row key by clearing the Row Key is Composite property and then defining the field to use. Enter the path to each field.
For example, the following configuration uses the ID field in the record as the row key:

- Multiple fields as the row key
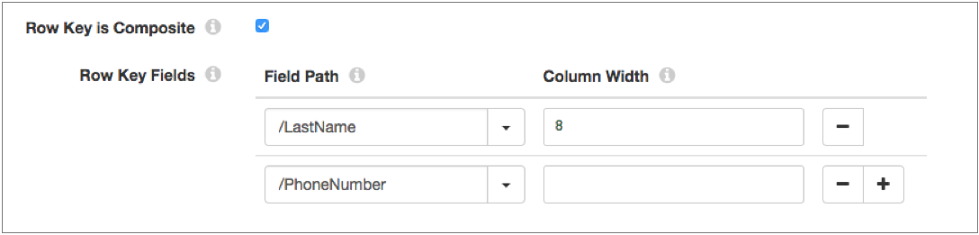
- You can define multiple fields as the row key by selecting the Row Key is Composite property and then defining multiple fields to use. Enter the path to each field.
- For example, let's assume that you are writing to a Cloud Bigtable table that
uses the customer last name and phone number as the row key. In the destination,
you select Row Key is Composite and then define the
LastName and PhoneNumber fields as the row key fields. You define the column
width of the LastName field as 8, as follows:
If one or more fields defined as the row key are missing, the destination sends that record to the pipeline for error handling.
Cloud Bigtable Data Types
When you map record fields to Google Cloud Bigtable columns, you specify whether the Cloud Bigtable storage type is text or binary. The destination converts the data types of the record fields to the Cloud Bigtable storage types.
The destination cannot convert the Data Collector List and Map data types. The destination converts Date, Datetime, and Time data types to the Text storage type with a default date format. To use a specific date format, use a Field Type Converter processor earlier in the pipeline to convert Date, Datetime, and Time fields to the String data type with the required date format. Then, you can map the String field to a Cloud Bigtable column with the Text storage type.
The following table lists the Data Collector data types that the destination can convert to a Cloud Bigtable storage type:
| Data Collector Data Type | Cloud Bigtable Storage Type |
|---|---|
| Boolean | Text, Binary |
| Byte | Text, Binary |
| Byte Array | Text, Binary |
| Character | Text, Binary |
| Date | Text |
| Datetime | Text |
| Decimal | Text, Binary |
| Double | Text, Binary |
| Float | Text, Binary |
| Integer | Text, Binary |
| Long | Text, Binary |
| Short | Text, Binary |
| String | Text |
| Time | Text |
Column Family and Field Mappings
When you configure the Google Bigtable destination, you map record fields to Google Cloud Bigtable columns. You define the Cloud Bigtable columns to write to by defining the column family and column qualifier.
You can specify a
default column family to use for all columns, or you can explicitly define the column
family for each field mapping using the following format: <column
family>:<qualifier>. Use the default or the explicit column family
mapping based on the following scenarios:
- All columns belong to the same column family
- When all columns written to the table belong to the same column family, you can
enter a default column family, clear the Explicit Column Family
Mapping property, and then enter only the qualifier when you map
fields to columns. Note: When you enter a default column family and clear the Explicit Column Family Mapping, any column family defined in a field to column mapping is ignored. The destination always uses the default column family.
- The following image shows the destination configured to use a default column
family for all columns:

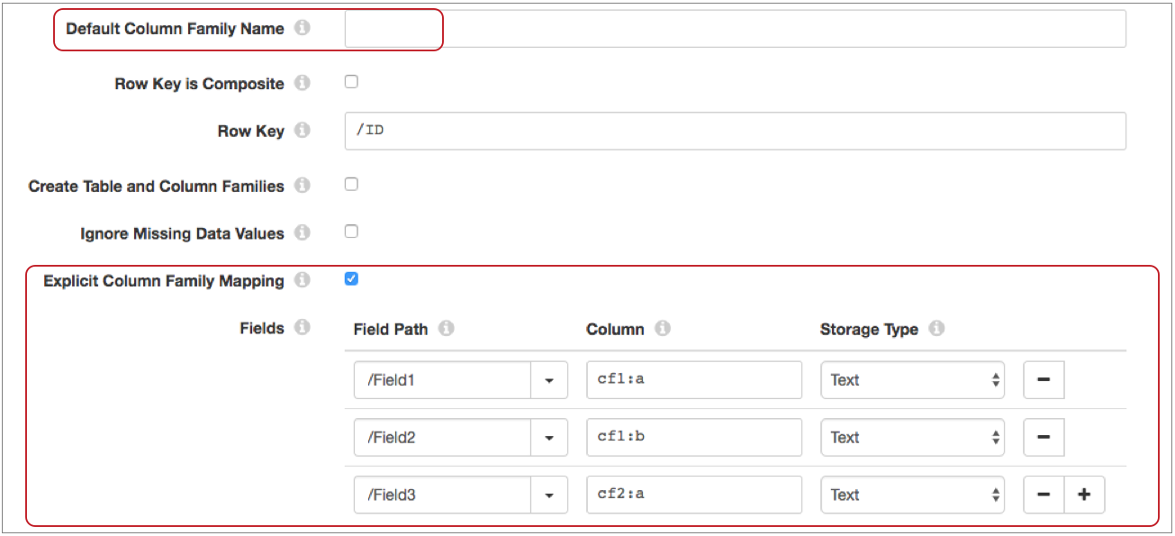
- Columns belong to different column families
- When columns written to the table belong to different column families, do not
enter a default column family. Instead, select the Explicit Column
Family Mapping property, and then enter the column family and
qualifier when you map fields to columns using the following format:
<column family>:<qualifier>. - The following image shows the destination configured to explicitly define the
column family for each field mapping:
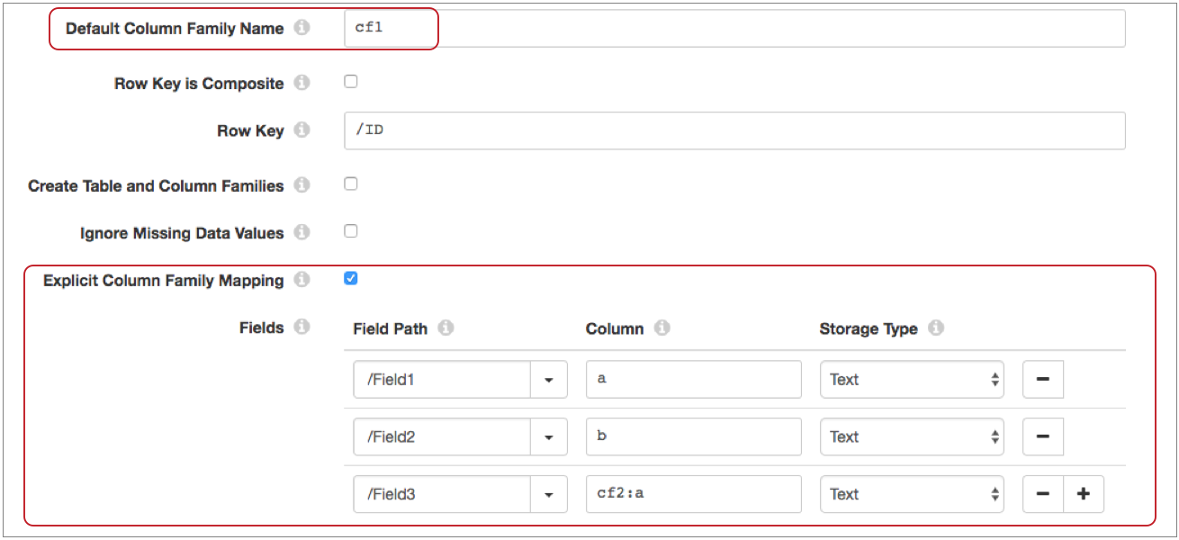
- Columns belong to different column families, but you’d like to use a default value for a group of columns
- When columns written to the table belong to different column families, you can
use a default column family for a group of columns. Then, you can override the
default for some of the columns by selecting the Explicit Column
Family Mapping property. When you map fields to columns, enter
only the qualifier to use the default column family. Enter the column family and
qualifier using the format
<column family>:<qualifier>to override the default column family. - The following image shows the destination configured to use a default column
family where some field mappings override the default value:
Time Basis
The time basis determines the timestamp value added for each column written to Google Cloud Bigtable.
You can use the following times as the time basis:
- Pipeline start time
- When you use pipeline start time as the time basis, the destination uses the time that the pipeline started as the timestamp value. The timestamp value is an epoch or UNIX time in milliseconds. The processing time is calculated once per pipeline.
- Batch start time
- When you use batch start time as the time basis, the destination uses the time that Data Collector starts processing the current batch as the timestamp value. The timestamp value is an epoch or UNIX time in milliseconds. The processing time is calculated once per batch.
- System time for each record
- When you use system time as the time basis, the destination uses the timestamp value automatically generated by Cloud Bigtable when the column is written to Cloud Bigtable. The timestamp value is an epoch or UNIX time in milliseconds.
- Long value from field in the record
- When you use the time associated with the record as the time basis, you specify
a field in the record that contains a Long value with an epoch or UNIX time in
milliseconds. The destination uses the field value as the timestamp value. If
the field value is not a Long, then the destination sends the record to the
pipeline for error handling.Tip: You can use a time function, such as time:dateTimeToMilliseconds or time:extractLongFromDate, in a processor earlier in the pipeline to convert a Datetime value to the Long data type.
Configuring a Google Bigtable Destination
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
On Record Error Error record handling for the stage:- Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
-
On the Bigtable tab, configure the following
properties:
Bigtable Property Description Instance ID Cloud Bigtable instance ID. Project ID Cloud Bigtable project ID. Table Name Cloud Bigtable table to write to. Enter the name of a table. Or define an expression that evaluates to the table name.
For example, you can use an Expression Evaluator to add a header attribute to the record named "BigtableTable" that defines the Cloud Bigtable table to write to. Then you can enter the following expression for this property:${record:attribute('BigtableTable')}Default Column Family Name Default column family to use when mapping fields in the record to Cloud Bigtable columns. The default column family is used in the field to column mapping in the following situations:- Explicit Column Family Mapping property is cleared.
- Explicit Column Family Mapping property is selected, but the field to column mapping specifies the qualifier only.
Row Key Field in the record to use as the row key for the table. Enter the path to the field.
Row Key Fields Fields in the record to use as the row key for the table when you configure a composite row key. The destination concatenates the values of the fields into the row key. Enter the path to each field and define the column width for all String fields.
Available when Row Key is Composite is enabled.
Create Table and Column Families Determines whether the destination creates tables and column families if they do not exist. When cleared, the destination produces an error when it attempts to write to a table or column family that does not exist. When selected, the destination creates table and column families if they do not exist.
Ignore Missing Data Values Determines whether the destination ignores missing data in the record. When cleared, records that include missing fields are sent to the pipeline for error handling. When selected, records that include missing fields are still written to Cloud Bigtable.
Note: If the missing field is defined as the row key, the record is always sent to the pipeline for error handling, regardless of how this property is configured.Explicit Column Family Mapping Determines whether column families are explicitly defined in the field to column mappings. Fields Map fields from records to Cloud Bigtable columns, and then define the storage type for the column in Cloud Bigtable. Using simple or bulk edit mode, click the Add icon to create additional field mappings.
Row Key is Composite Determines whether the row key is defined from a single field in the record or from multiple fields in the record. Clear to use a single field. Select to concatenate the values from multiple fields. Time Basis Time basis to use for the timestamp value added to each column written to Cloud Bigtable. Time Stamp Field Name Field in the record that contains the timestamp value to use for the time basis. The field must contain a Long value. Number of Records to Buffers Number of records to buffer in each commit to Cloud Bigtable. Enter a number between 1 and 1000. You might want to decrease the number if the destination is writing large columns of data. Default is 1000.