Automating Impala Metadata Updates for Drift Synchronization for Hive
This solution describes how to configure a Drift Synchronization Solution for Hive pipeline to automatically refresh the Impala metadata cache each time changes occur in the Hive metastore.
You love the Drift Synchronization Solution for Hive because it automatically updates the Hive metastore when needed. But if you've been using it with Impala, you've been trying to execute the Invalidate Metadata command to refresh the Impala metadata cache.
Instead of running the command manually, you use the event framework in your Drift Synchronization Solution for Hive pipeline to execute the command automatically.
Enable both the Hive Metastore destination and the Hadoop FS destination to generate events. You can connect both event streams to a single Hive Query executor. The executor then runs the Invalidate Metadata command each time the Hive Metastore destination changes the Hive metastore and each time Hadoop FS writes a file to a Hive table.
Here's how it works:
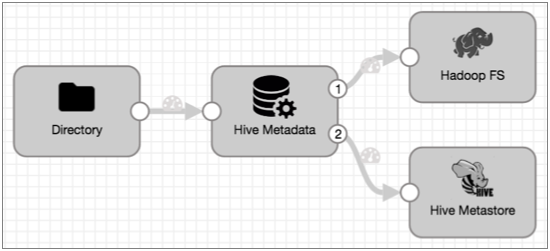
The following Drift Synchronization Solution for Hive pipeline reads files from a directory. The Hive Metadata processor evaluates the data for structural changes. It passes data to Hadoop FS and metadata records to the Hive Metastore destination. Hive Metastore creates and updates tables in Hive based on the metadata records it receives:
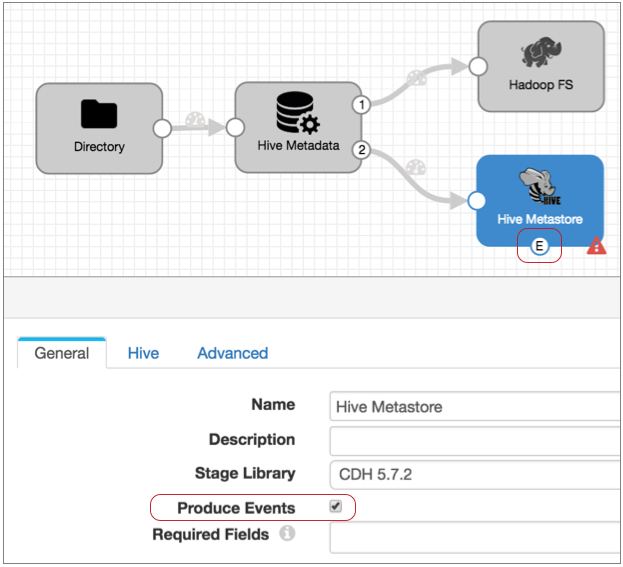
- Configure the Hive Metastore destination to generate events.
On the General tab, select the Produce Events property.
Now, the event output stream becomes available, and Hive Metastore destination generates an event record every time it updates the Hive metastore. The event record contains the name of the table that was created or updated.
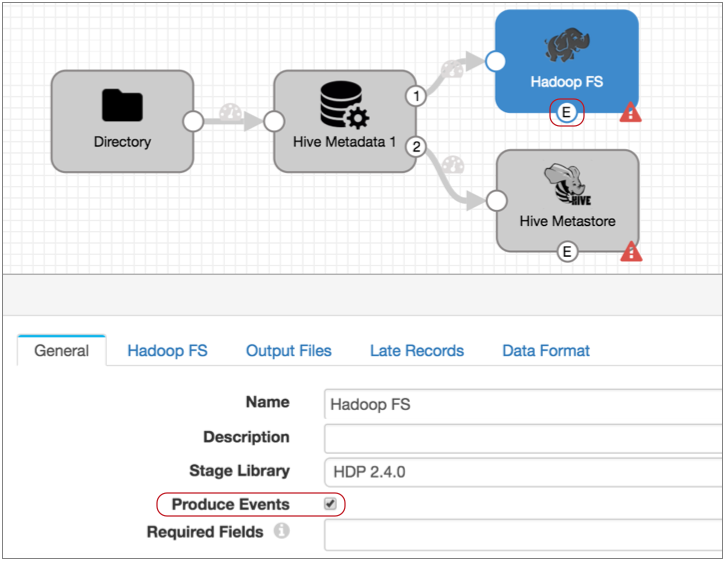
- We also need to add an event stream to the Hadoop FS destination so we can run
the Invalidate Metadata command each time the destination writes a file to Hive.
So in the Hadoop FS destination, on the General tab, select
Produce Events.
With this property selected the event output stream becomes available, and Hadoop FS generates an event record every time it closes a file:
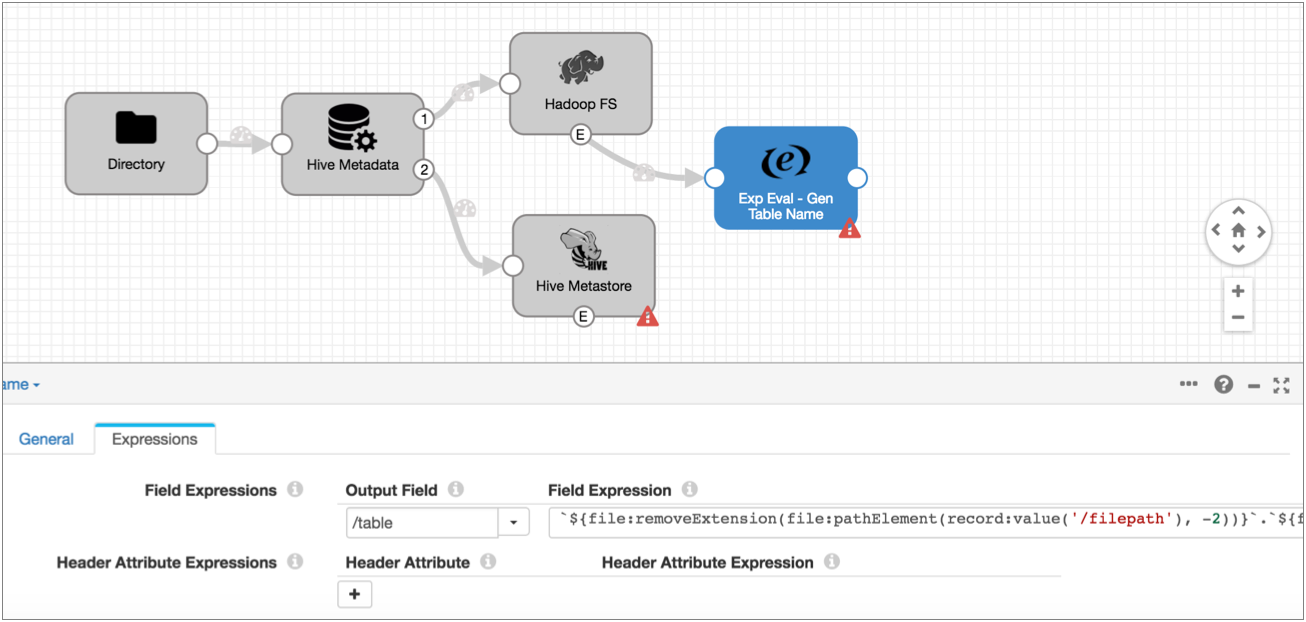
- The event record generated by the Hadoop FS destination does not include the
table name required by the Hive Query executor, but it contains the table name
in the file path. So add an Expression Evaluator processor to the event stream.
Create a new Table field and use the following
expression:
`${file:pathElement(record:value('/filepath'), -3)}`.`${file:pathElement(record:value('/filepath'), -2)}`This expression uses the path in the Filepath field of the event record and performs the following calculations:- Extracts the third-to-last section of the path and uses it as the database name.
- Extracts the second-to-last section of the path and uses it as the table name.
So when Hadoop FS completes a file, it writes the path of the written file in the filepath field, such as users/logs/server1weblog.txt. And the expression above properly interprets the database and table name as: logs.server1weblog.
- Add the Hive Query executor and connect the Hive Metastore destination and the
Expression Evaluator to the executor. Then configure the Hive Query executor.Note: If you want to use an Impala JDBC driver, make sure to install the driver as an external library for the Hive Query executor. For more information, see Installing the Impala Driver. When using the Apache Hive JDBC driver included with Data Collector, no additional steps are required.
In the Hive Query executor, configure the Hive configuration details on the Hive tab. If you have any trouble configuring the URL, see the Impala driver information in this informative blog post.
Then, on the Query tab, enter the following query:invalidate metadata ${record:value('/table')}This query refreshes the Impala cache for the specified table. And the table is either the table in the Hive Metastore event record that was just updated or the table where Hadoop FS wrote a file.
Here's the final pipeline:
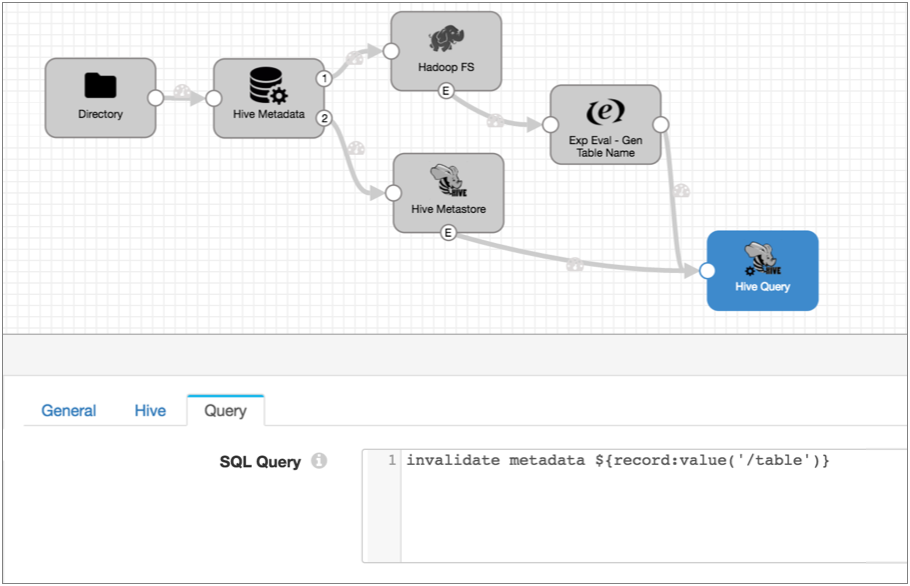
With these new event streams, each time the Hive Metastore destination creates a table, partition or column, and each time the Hadoop FS destination completes writing a file, the destinations generate event records. When the Hive Query executor receives an event record, it runs the Invalidate Metadata command so Impala can update its cache with the new information. Done!