What is IBM StreamSets?
IBM© StreamSets is a cloud-native platform for building, running, and monitoring data pipelines.
A pipeline describes the flow of data from origin to destination systems and defines how to process the data along the way. Pipelines can access multiple types of external systems, including cloud data lakes, cloud data warehouses, and storage systems installed on-premises such as relational databases.
As a pipeline runs, you can view real-time statistics and error information about the data as it flows from origin to destination systems.
- Control Hub
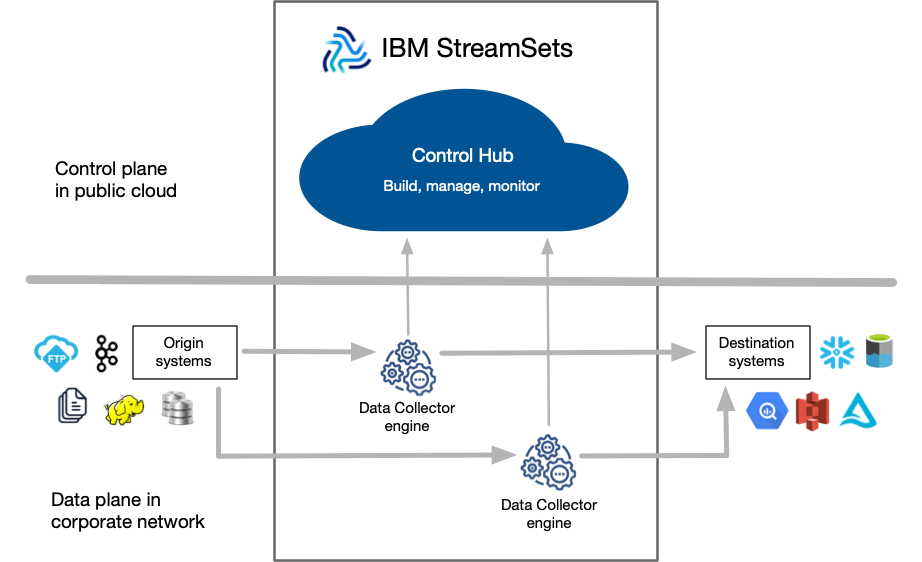
- Control Hub serves as the central point of control for your data pipelines. You access Control Hub using a web browser. You use Control Hub to build, manage, and monitor your pipelines.
- Data Collector
- Data Collector is an engine that processes data. Use the engine to run streaming data pipelines that continuously read, process, and write data as soon as the data becomes available. Data Collector pipelines can read from and write to a large number of heterogeneous origins and destinations. The pipelines perform record-based data transformations.
You use Control Hub to deploy Data Collector engines in your corporate network, which can be on-premises or on a protected cloud computing platform.
When you start a pipeline from Control Hub, the engine uses the pipeline configuration to process the data. The engine sends status updates and metrics about the running pipeline back to Control Hub so that you can monitor the pipeline progress in real time.
IBM StreamSets is available through multiple offerings. For more information, see the Control Hub documentation.
The following image provides a general overview of the IBM StreamSets components: